 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Validation of Medical-based Large Language Model Chatbots on Ophthalmic Patient Queries with LLM-based Evaluation
Feb 05, 2026Domain specific large language models are increasingly used to support patient education, triage, and clinical decision making in ophthalmology, making rigorous evaluation essential to ensure safety and accuracy. This study evaluated four small medical LLMs Meerkat-7B, BioMistral-7B, OpenBioLLM-8B, and MedLLaMA3-v20 in answering ophthalmology related patient queries and assessed the feasibility of LLM based evaluation against clinician grading. In this cross sectional study, 180 ophthalmology patient queries were answered by each model, generating 2160 responses. Models were selected for parameter sizes under 10 billion to enable resource efficient deployment. Responses were evaluated by three ophthalmologists of differing seniority and by GPT-4-Turbo using the S.C.O.R.E. framework assessing safety, consensus and context, objectivity, reproducibility, and explainability, with ratings assigned on a five point Likert scale. Agreement between LLM and clinician grading was assessed using Spearman rank correlation, Kendall tau statistics, and kernel density estimate analyses. Meerkat-7B achieved the highest performance with mean scores of 3.44 from Senior Consultants, 4.08 from Consultants, and 4.18 from Residents. MedLLaMA3-v20 performed poorest, with 25.5 percent of responses containing hallucinations or clinically misleading content, including fabricated terminology. GPT-4-Turbo grading showed strong alignment with clinician assessments overall, with Spearman rho of 0.80 and Kendall tau of 0.67, though Senior Consultants graded more conservatively. Overall, medical LLMs demonstrated potential for safe ophthalmic question answering, but gaps remained in clinical depth and consensus, supporting the feasibility of LLM based evaluation for large scale benchmarking and the need for hybrid automated and clinician review frameworks to guide safe clinical deployment.
A Proposed S.C.O.R.E. Evaluation Framework for Large Language Models : Safety, Consensus, Objectivity, Reproducibility and Explainability
Jul 10, 2024



A comprehensive qualitative evaluation framework for large language models (LLM) in healthcare that expands beyond traditional accuracy and quantitative metrics needed. We propose 5 key aspects for evaluation of LLMs: Safety, Consensus, Objectivity, Reproducibility and Explainability (S.C.O.R.E.). We suggest that S.C.O.R.E. may form the basis for an evaluation framework for future LLM-based models that are safe, reliable, trustworthy, and ethical for healthcare and clinical applications.
Towards Clinical AI Fairness: Filling Gaps in the Puzzle
May 28, 2024



The ethical integration of Artificial Intelligence (AI) in healthcare necessitates addressing fairness-a concept that is highly context-specific across medical fields. Extensive studies have been conducted to expand the technical components of AI fairness, while tremendous calls for AI fairness have been raised from healthcare. Despite this, a significant disconnect persists between technical advancements and their practical clinical applications, resulting in a lack of contextualized discussion of AI fairness in clinical settings. Through a detailed evidence gap analysis, our review systematically pinpoints several deficiencies concerning both healthcare data and the provided AI fairness solutions. We highlight the scarcity of research on AI fairness in many medical domains where AI technology is increasingly utilized. Additionally, our analysis highlights a substantial reliance on group fairness, aiming to ensure equality among demographic groups from a macro healthcare system perspective; in contrast, individual fairness, focusing on equity at a more granular level, is frequently overlooked. To bridge these gaps, our review advances actionable strategies for both the healthcare and AI research communities. Beyond applying existing AI fairness methods in healthcare, we further emphasize the importance of involving healthcare professionals to refine AI fairness concepts and methods to ensure contextually relevant and ethically sound AI applications in healthcare.
Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots in Ophthalmology and LLM-based evaluation using GPT-4
Feb 15, 2024



Purpose: To assess the alignment of GPT-4-based evaluation to human clinician experts, for the evaluation of responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. Methods: 400 ophthalmology questions and paired answers were created by ophthalmologists to represent commonly asked patient questions, divided into fine-tuning (368; 92%), and testing (40; 8%). We find-tuned 5 different LLMs, including LLAMA2-7b, LLAMA2-7b-Chat, LLAMA2-13b, and LLAMA2-13b-Chat. For the testing dataset, additional 8 glaucoma QnA pairs were included. 200 responses to the testing dataset were generated by 5 fine-tuned LLMs for evaluation. A customized clinical evaluation rubric was used to guide GPT-4 evaluation, grounded on clinical accuracy, relevance, patient safety, and ease of understanding. GPT-4 evaluation was then compared against ranking by 5 clinicians for clinical alignment. Results: Among all fine-tuned LLMs, GPT-3.5 scored the highest (87.1%), followed by LLAMA2-13b (80.9%), LLAMA2-13b-chat (75.5%), LLAMA2-7b-Chat (70%) and LLAMA2-7b (68.8%) based on the GPT-4 evaluation. GPT-4 evaluation demonstrated significant agreement with human clinician rankings, with Spearman and Kendall Tau correlation coefficients of 0.90 and 0.80 respectively; while correlation based on Cohen Kappa was more modest at 0.50. Notably, qualitative analysis and the glaucoma sub-analysis revealed clinical inaccuracies in the LLM-generated responses, which were appropriately identified by the GPT-4 evaluation. Conclusion: The notable clinical alignment of GPT-4 evaluation highlighted its potential to streamline the clinical evaluation of LLM chatbot responses to healthcare-related queries. By complementing the existing clinician-dependent manual grading, this efficient and automated evaluation could assist the validation of future developments in LLM applications for healthcare.
Towards clinical AI fairness: A translational perspective
Apr 26, 2023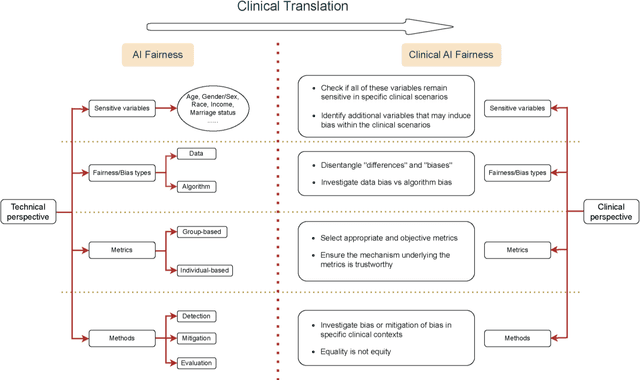
Artificial intelligence (AI) has demonstrated the ability to extract insights from data, but the issue of fairness remains a concern in high-stakes fields such as healthcare. Despite extensive discussion and efforts in algorithm development, AI fairness and clinical concerns have not been adequately addressed. In this paper, we discuss the misalignment between technical and clinical perspectives of AI fairness, highlight the barriers to AI fairness' translation to healthcare, advocate multidisciplinary collaboration to bridge the knowledge gap, and provide possible solutions to address the clinical concerns pertaining to AI fairness.