 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Retrieval-Augmented Generation in Medicine: A Scoping Review of Technical Implementations, Clinical Applications, and Ethical Considerations
Nov 13, 2025The rapid growth of medical knowledge and increasing complexity of clinical practice pose challenges. In this context, large language models (LLMs) have demonstrated value; however, inherent limitations remain. Retrieval-augmented generation (RAG) technologies show potential to enhance their clinical applicability. This study reviewed RAG applications in medicine. We found that research primarily relied on publicly available data, with limited application in private data. For retrieval, approaches commonly relied on English-centric embedding models, while LLMs were mostly generic, with limited use of medical-specific LLMs. For evaluation, automated metrics evaluated generation quality and task performance, whereas human evaluation focused on accuracy, completeness, relevance, and fluency, with insufficient attention to bias and safety. RAG applications were concentrated on question answering, report generation, text summarization, and information extraction. Overall, medical RAG remains at an early stage, requiring advances in clinical validation, cross-linguistic adaptation, and support for low-resource settings to enable trustworthy and responsible global use.
The Evolving Landscape of Generative Large Language Models and Traditional Natural Language Processing in Medicine
May 15, 2025Natural language processing (NLP) has been traditionally applied to medicine, and generative large language models (LLMs) have become prominent recently. However, the differences between them across different medical tasks remain underexplored. We analyzed 19,123 studies, finding that generative LLMs demonstrate advantages in open-ended tasks, while traditional NLP dominates in information extraction and analysis tasks. As these technologies advance, ethical use of them is essential to ensure their potential in medical applications.
Fairness-Aware Interpretable Modeling (FAIM) for Trustworthy Machine Learning in Healthcare
Mar 08, 2024
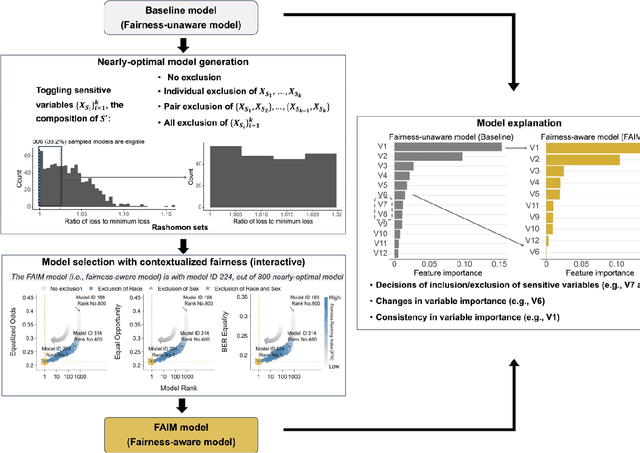


The escalating integration of machine learning in high-stakes fields such as healthcare raises substantial concerns about model fairness. We propose an interpretable framework - Fairness-Aware Interpretable Modeling (FAIM), to improve model fairness without compromising performance, featuring an interactive interface to identify a "fairer" model from a set of high-performing models and promoting the integration of data-driven evidence and clinical expertise to enhance contextualized fairness. We demonstrated FAIM's value in reducing sex and race biases by predicting hospital admission with two real-world databases, MIMIC-IV-ED and SGH-ED. We show that for both datasets, FAIM models not only exhibited satisfactory discriminatory performance but also significantly mitigated biases as measured by well-established fairness metrics, outperforming commonly used bias-mitigation methods. Our approach demonstrates the feasibility of improving fairness without sacrificing performance and provides an a modeling mode that invites domain experts to engage, fostering a multidisciplinary effort toward tailored AI fairness.
Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots in Ophthalmology and LLM-based evaluation using GPT-4
Feb 15, 2024



Purpose: To assess the alignment of GPT-4-based evaluation to human clinician experts, for the evaluation of responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. Methods: 400 ophthalmology questions and paired answers were created by ophthalmologists to represent commonly asked patient questions, divided into fine-tuning (368; 92%), and testing (40; 8%). We find-tuned 5 different LLMs, including LLAMA2-7b, LLAMA2-7b-Chat, LLAMA2-13b, and LLAMA2-13b-Chat. For the testing dataset, additional 8 glaucoma QnA pairs were included. 200 responses to the testing dataset were generated by 5 fine-tuned LLMs for evaluation. A customized clinical evaluation rubric was used to guide GPT-4 evaluation, grounded on clinical accuracy, relevance, patient safety, and ease of understanding. GPT-4 evaluation was then compared against ranking by 5 clinicians for clinical alignment. Results: Among all fine-tuned LLMs, GPT-3.5 scored the highest (87.1%), followed by LLAMA2-13b (80.9%), LLAMA2-13b-chat (75.5%), LLAMA2-7b-Chat (70%) and LLAMA2-7b (68.8%) based on the GPT-4 evaluation. GPT-4 evaluation demonstrated significant agreement with human clinician rankings, with Spearman and Kendall Tau correlation coefficients of 0.90 and 0.80 respectively; while correlation based on Cohen Kappa was more modest at 0.50. Notably, qualitative analysis and the glaucoma sub-analysis revealed clinical inaccuracies in the LLM-generated responses, which were appropriately identified by the GPT-4 evaluation. Conclusion: The notable clinical alignment of GPT-4 evaluation highlighted its potential to streamline the clinical evaluation of LLM chatbot responses to healthcare-related queries. By complementing the existing clinician-dependent manual grading, this efficient and automated evaluation could assist the validation of future developments in LLM applications for healthcare.
Development and Testing of a Novel Large Language Model-Based Clinical Decision Support Systems for Medication Safety in 12 Clinical Specialties
Jan 29, 2024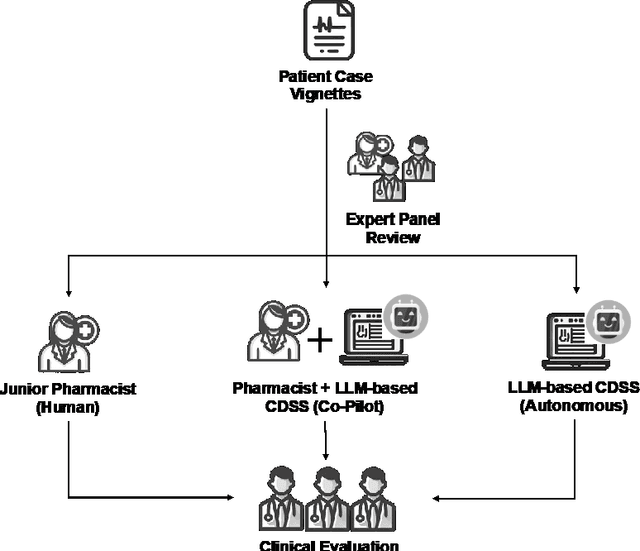


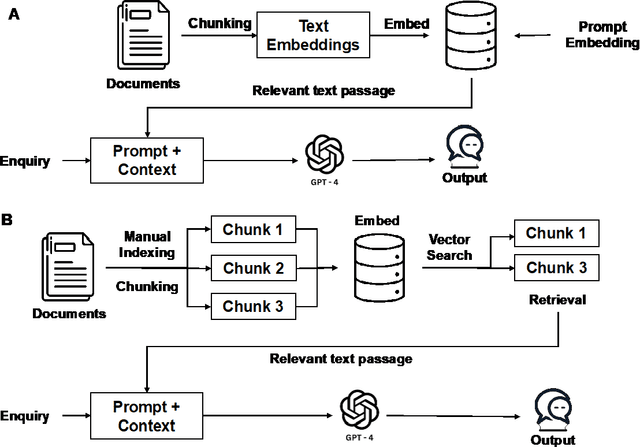
Importance: We introduce a novel Retrieval Augmented Generation (RAG)-Large Language Model (LLM) as a Clinical Decision Support System (CDSS) for safe medication prescription. This model addresses the limitations of traditional rule-based CDSS by providing relevant prescribing error alerts tailored to patient context and institutional guidelines. Objective: The study evaluates the efficacy of an LLM-based CDSS in identifying medication errors across various medical and surgical case vignettes, compared to a human expert panel. It also examines clinician preferences among different CDSS integration modalities: junior pharmacist, LLM-based CDSS alone, and a combination of both. Design, Setting, and Participants: Utilizing a RAG model with GPT-4.0, the study involved 61 prescribing error scenarios within 23 clinical vignettes across 12 specialties. An expert panel assessed these cases using the PCNE classification and NCC MERP index. Three junior pharmacists independently reviewed each vignette under simulated conditions. Main Outcomes and Measures: The study assesses the LLM-based CDSS's accuracy, precision, recall, and F1 scores in identifying Drug-Related Problems (DRPs), compared to junior pharmacists alone or in an assistive mode with the CDSS. Results: The co-pilot mode of RAG-LLM significantly improved DRP identification accuracy by 22% over solo pharmacists. It showed higher recall and F1 scores, indicating better detection of severe DRPs, despite a slight decrease in precision. Accuracy varied across categories when pharmacists had access to RAG-LLM responses. Conclusions: The RAG-LLM based CDSS enhances medication error identification accuracy when used with junior pharmacists, especially in detecting severe DRPs.
Cluster trajectory of SOFA score in predicting mortality in sepsis
Nov 23, 2023



Objective: Sepsis is a life-threatening condition. Sequential Organ Failure Assessment (SOFA) score is commonly used to assess organ dysfunction and predict ICU mortality, but it is taken as a static measurement and fails to capture dynamic changes. This study aims to investigate the relationship between dynamic changes in SOFA scores over the first 72 hours of ICU admission and patient outcomes. Design, setting, and participants: 3,253 patients in the Medical Information Mart for Intensive Care IV database who met the sepsis-3 criteria and were admitted from the emergency department with at least 72 hours of ICU admission and full-active resuscitation status were analysed. Group-based trajectory modelling with dynamic time warping and k-means clustering identified distinct trajectory patterns in dynamic SOFA scores. They were subsequently compared using Python. Main outcome measures: Outcomes including hospital and ICU mortality, length of stay in hospital and ICU, and readmission during hospital stay, were collected. Discharge time from ICU to wards and cut-offs at 7-day and 14-day were taken. Results: Four clusters were identified: A (consistently low SOFA scores), B (rapid increase followed by a decline in SOFA scores), C (higher baseline scores with gradual improvement), and D (persistently elevated scores). Cluster D had the longest ICU and hospital stays, highest ICU and hospital mortality. Discharge rates from ICU were similar for Clusters A and B, while Cluster C had initially comparable rates but a slower transition to ward. Conclusion: Monitoring dynamic changes in SOFA score is valuable for assessing sepsis severity and treatment responsiveness.
Integrating UMLS Knowledge into Large Language Models for Medical Question Answering
Oct 13, 2023



Large language models (LLMs) have demonstrated powerful text generation capabilities, bringing unprecedented innovation to the healthcare field. While LLMs hold immense promise for applications in healthcare, applying them to real clinical scenarios presents significant challenges, as these models may generate content that deviates from established medical facts and even exhibit potential biases. In our research, we develop an augmented LLM framework based on the Unified Medical Language System (UMLS), aiming to better serve the healthcare community. We employ LLaMa2-13b-chat and ChatGPT-3.5 as our benchmark models, and conduct automatic evaluations using the ROUGE Score and BERTScore on 104 questions from the LiveQA test set. Additionally, we establish criteria for physician-evaluation based on four dimensions: Factuality, Completeness, Readability and Relevancy. ChatGPT-3.5 is used for physician evaluation with 20 questions on the LiveQA test set. Multiple resident physicians conducted blind reviews to evaluate the generated content, and the results indicate that this framework effectively enhances the factuality, completeness, and relevance of generated content. Our research demonstrates the effectiveness of using UMLS-augmented LLMs and highlights the potential application value of LLMs in in medical question-answering.