 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-world Deployment and Evaluation of PErioperative AI CHatbot (PEACH) -- a Large Language Model Chatbot for Perioperative Medicine
Dec 24, 2024



Large Language Models (LLMs) are emerging as powerful tools in healthcare, particularly for complex, domain-specific tasks. This study describes the development and evaluation of the PErioperative AI CHatbot (PEACH), a secure LLM-based system integrated with local perioperative guidelines to support preoperative clinical decision-making. PEACH was embedded with 35 institutional perioperative protocols in the secure Claude 3.5 Sonet LLM framework within Pair Chat (developed by Singapore Government) and tested in a silent deployment with real-world data. Accuracy, safety, and usability were assessed. Deviations and hallucinations were categorized based on potential harm, and user feedback was evaluated using the Technology Acceptance Model (TAM). Updates were made after the initial silent deployment to amend one protocol. In 240 real-world clinical iterations, PEACH achieved a first-generation accuracy of 97.5% (78/80) and an overall accuracy of 96.7% (232/240) across three iterations. The updated PEACH demonstrated improved accuracy of 97.9% (235/240), with a statistically significant difference from the null hypothesis of 95% accuracy (p = 0.018, 95% CI: 0.952-0.991). Minimal hallucinations and deviations were observed (both 1/240 and 2/240, respectively). Clinicians reported that PEACH expedited decisions in 95% of cases, and inter-rater reliability ranged from kappa 0.772-0.893 within PEACH and 0.610-0.784 among attendings. PEACH is an accurate, adaptable tool that enhances consistency and efficiency in perioperative decision-making. Future research should explore its scalability across specialties and its impact on clinical outcomes.
oRetrieval Augmented Generation for 10 Large Language Models and its Generalizability in Assessing Medical Fitness
Oct 11, 2024



Large Language Models (LLMs) show potential for medical applications but often lack specialized clinical knowledge. Retrieval Augmented Generation (RAG) allows customization with domain-specific information, making it suitable for healthcare. This study evaluates the accuracy, consistency, and safety of RAG models in determining fitness for surgery and providing preoperative instructions. We developed LLM-RAG models using 35 local and 23 international preoperative guidelines and tested them against human-generated responses. A total of 3,682 responses were evaluated. Clinical documents were processed using Llamaindex, and 10 LLMs, including GPT3.5, GPT4, and Claude-3, were assessed. Fourteen clinical scenarios were analyzed, focusing on seven aspects of preoperative instructions. Established guidelines and expert judgment were used to determine correct responses, with human-generated answers serving as comparisons. The LLM-RAG models generated responses within 20 seconds, significantly faster than clinicians (10 minutes). The GPT4 LLM-RAG model achieved the highest accuracy (96.4% vs. 86.6%, p=0.016), with no hallucinations and producing correct instructions comparable to clinicians. Results were consistent across both local and international guidelines. This study demonstrates the potential of LLM-RAG models for preoperative healthcare tasks, highlighting their efficiency, scalability, and reliability.
Development and Testing of Retrieval Augmented Generation in Large Language Models -- A Case Study Report
Jan 29, 2024Purpose: Large Language Models (LLMs) hold significant promise for medical applications. Retrieval Augmented Generation (RAG) emerges as a promising approach for customizing domain knowledge in LLMs. This case study presents the development and evaluation of an LLM-RAG pipeline tailored for healthcare, focusing specifically on preoperative medicine. Methods: We developed an LLM-RAG model using 35 preoperative guidelines and tested it against human-generated responses, with a total of 1260 responses evaluated. The RAG process involved converting clinical documents into text using Python-based frameworks like LangChain and Llamaindex, and processing these texts into chunks for embedding and retrieval. Vector storage techniques and selected embedding models to optimize data retrieval, using Pinecone for vector storage with a dimensionality of 1536 and cosine similarity for loss metrics. Human-generated answers, provided by junior doctors, were used as a comparison. Results: The LLM-RAG model generated answers within an average of 15-20 seconds, significantly faster than the 10 minutes typically required by humans. Among the basic LLMs, GPT4.0 exhibited the best accuracy of 80.1%. This accuracy was further increased to 91.4% when the model was enhanced with RAG. Compared to the human-generated instructions, which had an accuracy of 86.3%, the performance of the GPT4.0 RAG model demonstrated non-inferiority (p=0.610). Conclusions: In this case study, we demonstrated a LLM-RAG model for healthcare implementation. The pipeline shows the advantages of grounded knowledge, upgradability, and scalability as important aspects of healthcare LLM deployment.
Enhancing Diagnostic Accuracy through Multi-Agent Conversations: Using Large Language Models to Mitigate Cognitive Bias
Jan 26, 2024Background: Cognitive biases in clinical decision-making significantly contribute to errors in diagnosis and suboptimal patient outcomes. Addressing these biases presents a formidable challenge in the medical field. This study explores the role of large language models (LLMs) in mitigating these biases through the utilization of a multi-agent framework. We simulate the clinical decision-making processes through multi-agent conversation and evaluate its efficacy in improving diagnostic accuracy. Methods: A total of 16 published and unpublished case reports where cognitive biases have resulted in misdiagnoses were identified from the literature. In the multi-agent system, we leveraged GPT-4 Turbo to facilitate interactions among four simulated agents to replicate clinical team dynamics. Each agent has a distinct role: 1) To make the initial and final diagnosis after considering the discussions, 2) The devil's advocate and correct confirmation and anchoring bias, 3) The tutor and facilitator of the discussion to reduce premature closure bias, and 4) To record and summarize the findings. A total of 80 simulations were evaluated for the accuracy of initial diagnosis, top differential diagnosis and final two differential diagnoses. Findings: In a total of 80 responses evaluating both initial and final diagnoses, the initial diagnosis had an accuracy of 0% (0/80), but following multi-agent discussions, the accuracy for the top differential diagnosis increased to 71.3% (57/80), and for the final two differential diagnoses, to 80.0% (64/80). The system demonstrated an ability to reevaluate and correct misconceptions, even in scenarios with misleading initial investigations. Interpretation: The LLM-driven multi-agent conversation system shows promise in enhancing diagnostic accuracy in diagnostically challenging medical scenarios.
Cluster trajectory of SOFA score in predicting mortality in sepsis
Nov 23, 2023



Objective: Sepsis is a life-threatening condition. Sequential Organ Failure Assessment (SOFA) score is commonly used to assess organ dysfunction and predict ICU mortality, but it is taken as a static measurement and fails to capture dynamic changes. This study aims to investigate the relationship between dynamic changes in SOFA scores over the first 72 hours of ICU admission and patient outcomes. Design, setting, and participants: 3,253 patients in the Medical Information Mart for Intensive Care IV database who met the sepsis-3 criteria and were admitted from the emergency department with at least 72 hours of ICU admission and full-active resuscitation status were analysed. Group-based trajectory modelling with dynamic time warping and k-means clustering identified distinct trajectory patterns in dynamic SOFA scores. They were subsequently compared using Python. Main outcome measures: Outcomes including hospital and ICU mortality, length of stay in hospital and ICU, and readmission during hospital stay, were collected. Discharge time from ICU to wards and cut-offs at 7-day and 14-day were taken. Results: Four clusters were identified: A (consistently low SOFA scores), B (rapid increase followed by a decline in SOFA scores), C (higher baseline scores with gradual improvement), and D (persistently elevated scores). Cluster D had the longest ICU and hospital stays, highest ICU and hospital mortality. Discharge rates from ICU were similar for Clusters A and B, while Cluster C had initially comparable rates but a slower transition to ward. Conclusion: Monitoring dynamic changes in SOFA score is valuable for assessing sepsis severity and treatment responsiveness.
Medical Intervention Duration Estimation Using Language-enhanced Transformer Encoder with Medical Prompts
Mar 30, 2023In recent years, estimating the duration of medical intervention based on electronic health records (EHRs) has gained significant attention in the filed of clinical decision support. However, current models largely focus on structured data, leaving out information from the unstructured clinical free-text data. To address this, we present a novel language-enhanced transformer-based framework, which projects all relevant clinical data modalities (continuous, categorical, binary, and free-text features) into a harmonized language latent space using a pre-trained sentence encoder with the help of medical prompts. The proposed method enables the integration of information from different modalities within the cell transformer encoder and leads to more accurate duration estimation for medical intervention. Our experimental results on both US-based (length of stay in ICU estimation) and Asian (surgical duration prediction) medical datasets demonstrate the effectiveness of our proposed framework, which outperforms tailored baseline approaches and exhibits robustness to data corruption in EHRs.
AutoScore-Imbalance: An interpretable machine learning tool for development of clinical scores with rare events data
Jul 13, 2021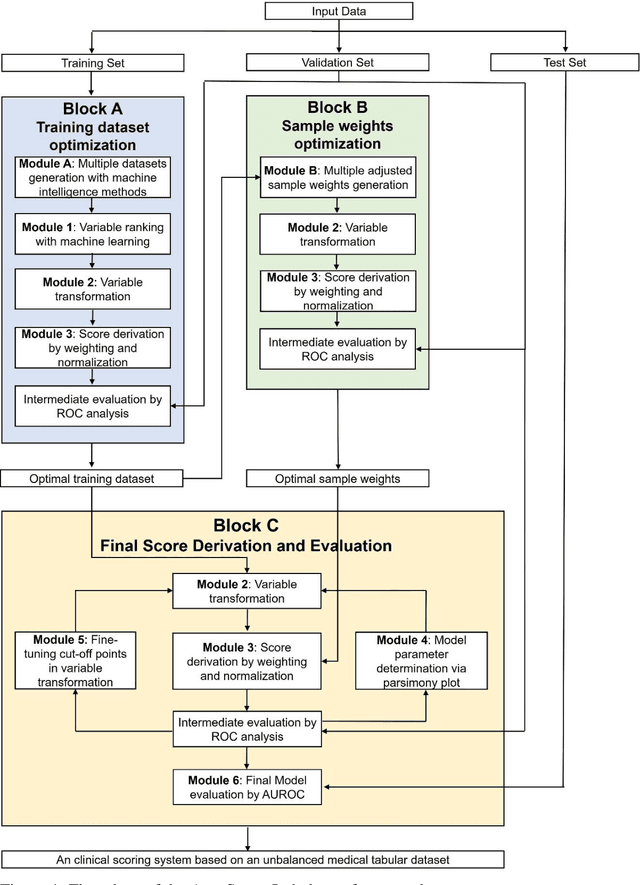
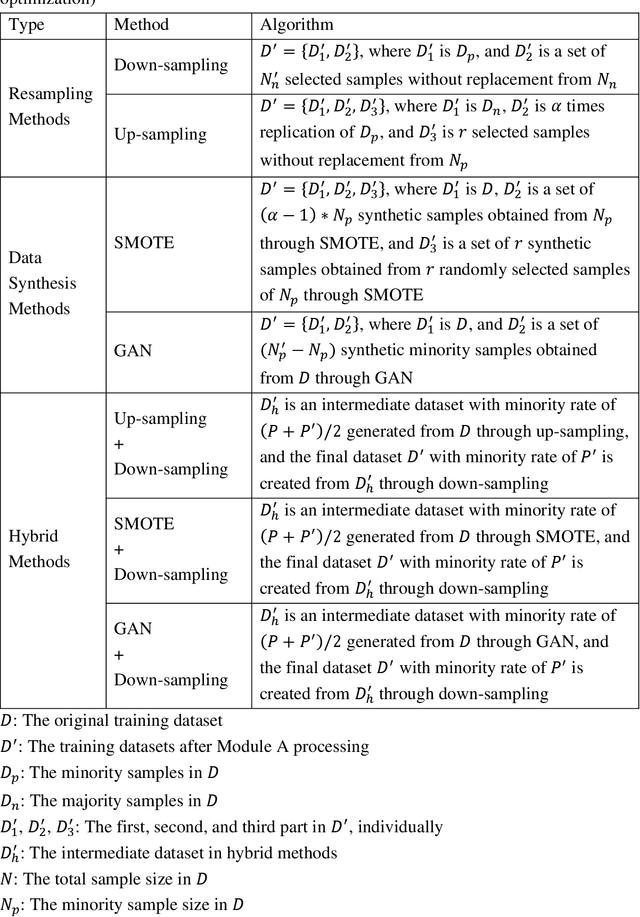
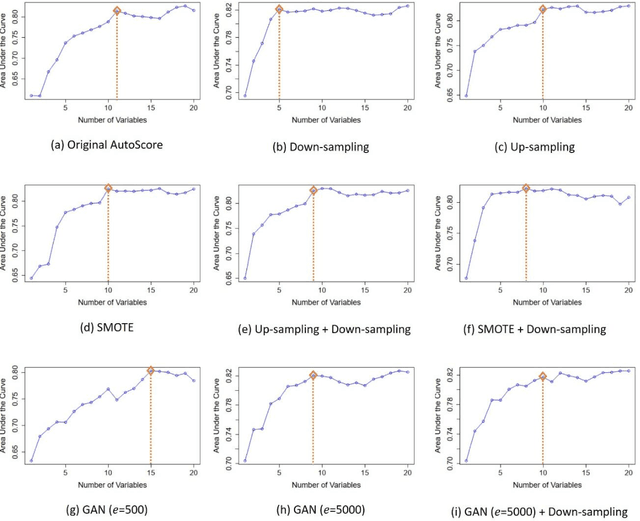
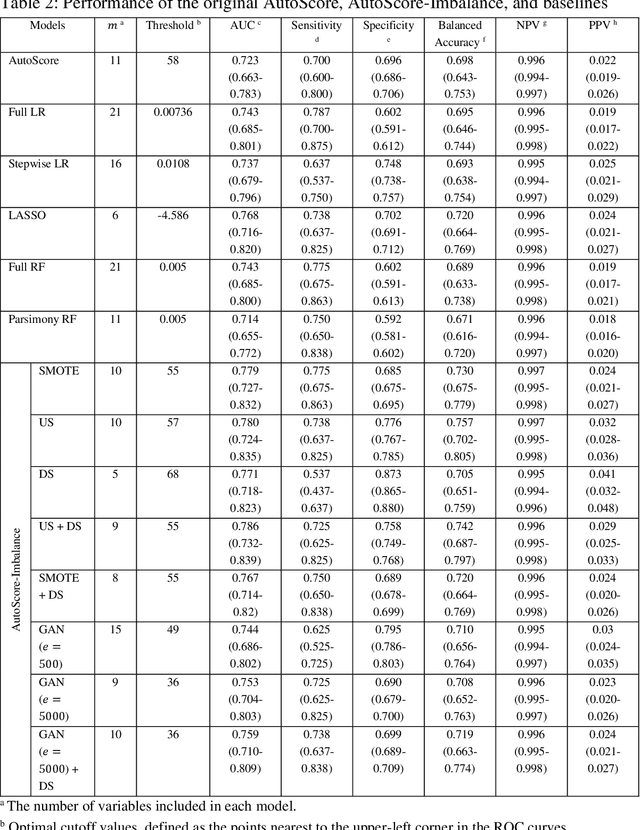
Background: Medical decision-making impacts both individual and public health. Clinical scores are commonly used among a wide variety of decision-making models for determining the degree of disease deterioration at the bedside. AutoScore was proposed as a useful clinical score generator based on machine learning and a generalized linear model. Its current framework, however, still leaves room for improvement when addressing unbalanced data of rare events. Methods: Using machine intelligence approaches, we developed AutoScore-Imbalance, which comprises three components: training dataset optimization, sample weight optimization, and adjusted AutoScore. All scoring models were evaluated on the basis of their area under the curve (AUC) in the receiver operating characteristic analysis and balanced accuracy (i.e., mean value of sensitivity and specificity). By utilizing a publicly accessible dataset from Beth Israel Deaconess Medical Center, we assessed the proposed model and baseline approaches in the prediction of inpatient mortality. Results: AutoScore-Imbalance outperformed baselines in terms of AUC and balanced accuracy. The nine-variable AutoScore-Imbalance sub-model achieved the highest AUC of 0.786 (0.732-0.839) while the eleven-variable original AutoScore obtained an AUC of 0.723 (0.663-0.783), and the logistic regression with 21 variables obtained an AUC of 0.743 (0.685-0.800). The AutoScore-Imbalance sub-model (using down-sampling algorithm) yielded an AUC of 0. 0.771 (0.718-0.823) with only five variables, demonstrating a good balance between performance and variable sparsity. Conclusions: The AutoScore-Imbalance tool has the potential to be applied to highly unbalanced datasets to gain further insight into rare medical events and to facilitate real-world clinical decision-making.