 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Federated Risk Difference Estimation for Time-to-Event Clinical Outcomes
Jan 21, 2026Privacy-preserving model co-training in medical research is often hindered by server-dependent architectures incompatible with protected hospital data systems and by the predominant focus on relative effect measures (hazard ratios) which lack clinical interpretability for absolute survival risk assessment. We propose FedRD, a communication-efficient framework for federated risk difference estimation in distributed survival data. Unlike typical federated learning frameworks (e.g., FedAvg) that require persistent server connections and extensive iterative communication, FedRD is server-independent with minimal communication: one round of summary statistics exchange for the stratified model and three rounds for the unstratified model. Crucially, FedRD provides valid confidence intervals and hypothesis testing--capabilities absent in FedAvg-based frameworks. We provide theoretical guarantees by establishing the asymptotic properties of FedRD and prove that FedRD (unstratified) is asymptotically equivalent to pooled individual-level analysis. Simulation studies and real-world clinical applications across different countries demonstrate that FedRD outperforms local and federated baselines in both estimation accuracy and prediction performance, providing an architecturally feasible solution for absolute risk assessment in privacy-restricted, multi-site clinical studies.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
TRACER: Transfer Learning based Real-time Adaptation for Clinical Evolving Risk
Dec 14, 2025Clinical decision support tools built on electronic health records often experience performance drift due to temporal population shifts, particularly when changes in the clinical environment initially affect only a subset of patients, resulting in a transition to mixed populations. Such case-mix changes commonly arise following system-level operational updates or the emergence of new diseases, such as COVID-19. We propose TRACER (Transfer Learning-based Real-time Adaptation for Clinical Evolving Risk), a framework that identifies encounter-level transition membership and adapts predictive models using transfer learning without full retraining. In simulation studies, TRACER outperformed static models trained on historical or contemporary data. In a real-world application predicting hospital admission following emergency department visits across the COVID-19 transition, TRACER improved both discrimination and calibration. TRACER provides a scalable approach for maintaining robust predictive performance under evolving and heterogeneous clinical conditions.
Retrieval-Augmented Generation in Medicine: A Scoping Review of Technical Implementations, Clinical Applications, and Ethical Considerations
Nov 13, 2025The rapid growth of medical knowledge and increasing complexity of clinical practice pose challenges. In this context, large language models (LLMs) have demonstrated value; however, inherent limitations remain. Retrieval-augmented generation (RAG) technologies show potential to enhance their clinical applicability. This study reviewed RAG applications in medicine. We found that research primarily relied on publicly available data, with limited application in private data. For retrieval, approaches commonly relied on English-centric embedding models, while LLMs were mostly generic, with limited use of medical-specific LLMs. For evaluation, automated metrics evaluated generation quality and task performance, whereas human evaluation focused on accuracy, completeness, relevance, and fluency, with insufficient attention to bias and safety. RAG applications were concentrated on question answering, report generation, text summarization, and information extraction. Overall, medical RAG remains at an early stage, requiring advances in clinical validation, cross-linguistic adaptation, and support for low-resource settings to enable trustworthy and responsible global use.
Equitable Survival Prediction: A Fairness-Aware Survival Modeling (FASM) Approach
Oct 23, 2025As machine learning models become increasingly integrated into healthcare, structural inequities and social biases embedded in clinical data can be perpetuated or even amplified by data-driven models. In survival analysis, censoring and time dynamics can further add complexity to fair model development. Additionally, algorithmic fairness approaches often overlook disparities in cross-group rankings, e.g., high-risk Black patients may be ranked below lower-risk White patients who do not experience the event of mortality. Such misranking can reinforce biological essentialism and undermine equitable care. We propose a Fairness-Aware Survival Modeling (FASM), designed to mitigate algorithmic bias regarding both intra-group and cross-group risk rankings over time. Using breast cancer prognosis as a representative case and applying FASM to SEER breast cancer data, we show that FASM substantially improves fairness while preserving discrimination performance comparable to fairness-unaware survival models. Time-stratified evaluations show that FASM maintains stable fairness over a 10-year horizon, with the greatest improvements observed during the mid-term of follow-up. Our approach enables the development of survival models that prioritize both accuracy and equity in clinical decision-making, advancing fairness as a core principle in clinical care.
Shift-Invariant Attribute Scoring for Kolmogorov-Arnold Networks via Shapley Value
Oct 02, 2025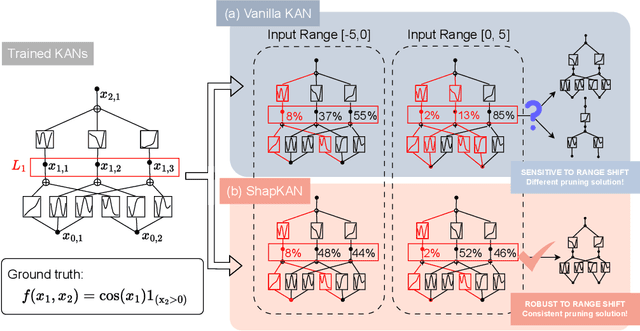
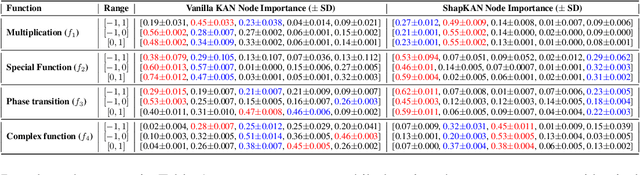
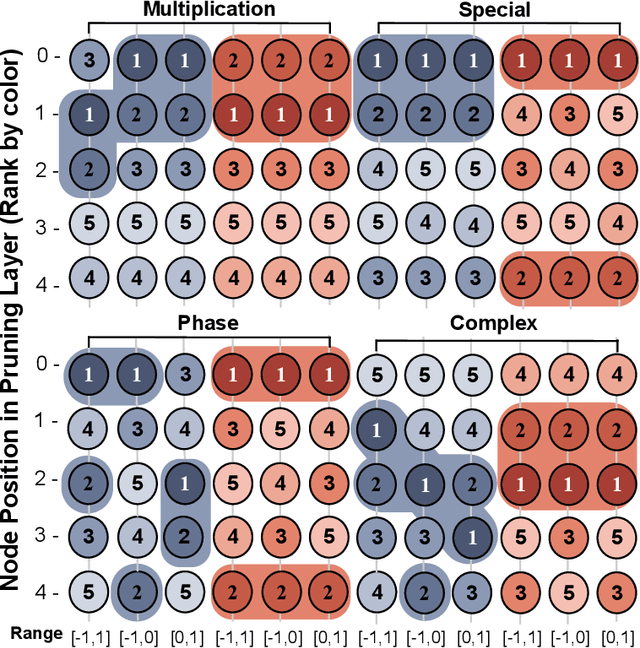
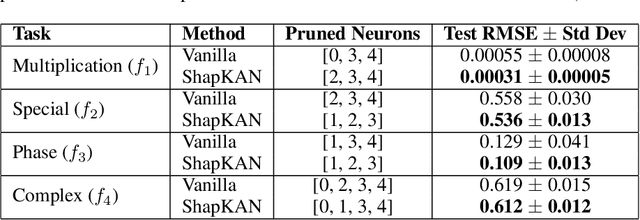
For many real-world applications, understanding feature-outcome relationships is as crucial as achieving high predictive accuracy. While traditional neural networks excel at prediction, their black-box nature obscures underlying functional relationships. Kolmogorov--Arnold Networks (KANs) address this by employing learnable spline-based activation functions on edges, enabling recovery of symbolic representations while maintaining competitive performance. However, KAN's architecture presents unique challenges for network pruning. Conventional magnitude-based methods become unreliable due to sensitivity to input coordinate shifts. We propose \textbf{ShapKAN}, a pruning framework using Shapley value attribution to assess node importance in a shift-invariant manner. Unlike magnitude-based approaches, ShapKAN quantifies each node's actual contribution, ensuring consistent importance rankings regardless of input parameterization. Extensive experiments on synthetic and real-world datasets demonstrate that ShapKAN preserves true node importance while enabling effective network compression. Our approach improves KAN's interpretability advantages, facilitating deployment in resource-constrained environments.
AURAD: Anatomy-Pathology Unified Radiology Synthesis with Progressive Representations
Sep 05, 2025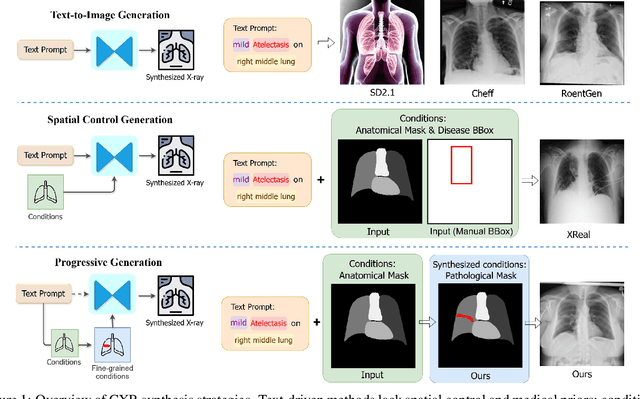

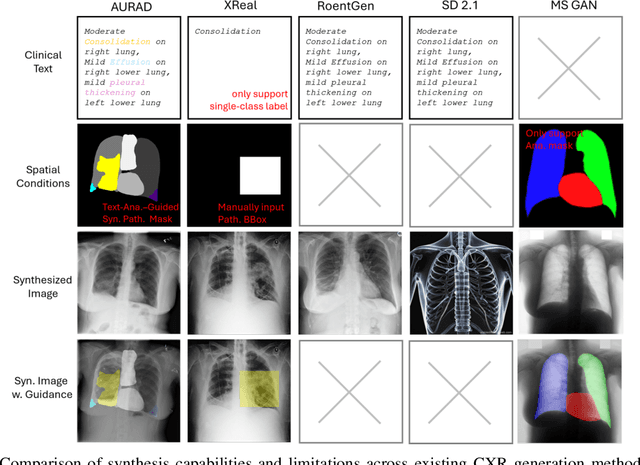
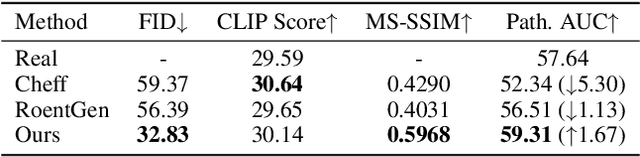
Medical image synthesis has become an essential strategy for augmenting datasets and improving model generalization in data-scarce clinical settings. However, fine-grained and controllable synthesis remains difficult due to limited high-quality annotations and domain shifts across datasets. Existing methods, often designed for natural images or well-defined tumors, struggle to generalize to chest radiographs, where disease patterns are morphologically diverse and tightly intertwined with anatomical structures. To address these challenges, we propose AURAD, a controllable radiology synthesis framework that jointly generates high-fidelity chest X-rays and pseudo semantic masks. Unlike prior approaches that rely on randomly sampled masks-limiting diversity, controllability, and clinical relevance-our method learns to generate masks that capture multi-pathology coexistence and anatomical-pathological consistency. It follows a progressive pipeline: pseudo masks are first generated from clinical prompts conditioned on anatomical structures, and then used to guide image synthesis. We also leverage pretrained expert medical models to filter outputs and ensure clinical plausibility. Beyond visual realism, the synthesized masks also serve as labels for downstream tasks such as detection and segmentation, bridging the gap between generative modeling and real-world clinical applications. Extensive experiments and blinded radiologist evaluations demonstrate the effectiveness and generalizability of our method across tasks and datasets. In particular, 78% of our synthesized images are classified as authentic by board-certified radiologists, and over 40% of predicted segmentation overlays are rated as clinically useful. All code, pre-trained models, and the synthesized dataset will be released upon publication.
The Evolving Landscape of Generative Large Language Models and Traditional Natural Language Processing in Medicine
May 15, 2025Natural language processing (NLP) has been traditionally applied to medicine, and generative large language models (LLMs) have become prominent recently. However, the differences between them across different medical tasks remain underexplored. We analyzed 19,123 studies, finding that generative LLMs demonstrate advantages in open-ended tasks, while traditional NLP dominates in information extraction and analysis tasks. As these technologies advance, ethical use of them is essential to ensure their potential in medical applications.
Toward Fair Federated Learning under Demographic Disparities and Data Imbalance
May 14, 2025Ensuring fairness is critical when applying artificial intelligence to high-stakes domains such as healthcare, where predictive models trained on imbalanced and demographically skewed data risk exacerbating existing disparities. Federated learning (FL) enables privacy-preserving collaboration across institutions, but remains vulnerable to both algorithmic bias and subgroup imbalance - particularly when multiple sensitive attributes intersect. We propose FedIDA (Fed erated Learning for Imbalance and D isparity A wareness), a framework-agnostic method that combines fairness-aware regularization with group-conditional oversampling. FedIDA supports multiple sensitive attributes and heterogeneous data distributions without altering the convergence behavior of the underlying FL algorithm. We provide theoretical analysis establishing fairness improvement bounds using Lipschitz continuity and concentration inequalities, and show that FedIDA reduces the variance of fairness metrics across test sets. Empirical results on both benchmark and real-world clinical datasets confirm that FedIDA consistently improves fairness while maintaining competitive predictive performance, demonstrating its effectiveness for equitable and privacy-preserving modeling in healthcare. The source code is available on GitHub.
SIM-Shapley: A Stable and Computationally Efficient Approach to Shapley Value Approximation
May 13, 2025



Explainable artificial intelligence (XAI) is essential for trustworthy machine learning (ML), particularly in high-stakes domains such as healthcare and finance. Shapley value (SV) methods provide a principled framework for feature attribution in complex models but incur high computational costs, limiting their scalability in high-dimensional settings. We propose Stochastic Iterative Momentum for Shapley Value Approximation (SIM-Shapley), a stable and efficient SV approximation method inspired by stochastic optimization. We analyze variance theoretically, prove linear $Q$-convergence, and demonstrate improved empirical stability and low bias in practice on real-world datasets. In our numerical experiments, SIM-Shapley reduces computation time by up to 85% relative to state-of-the-art baselines while maintaining comparable feature attribution quality. Beyond feature attribution, our stochastic mini-batch iterative framework extends naturally to a broader class of sample average approximation problems, offering a new avenue for improving computational efficiency with stability guarantees. Code is publicly available at https://github.com/nliulab/SIM-Shapley.