 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-world Deployment and Evaluation of PErioperative AI CHatbot (PEACH) -- a Large Language Model Chatbot for Perioperative Medicine
Dec 24, 2024



Large Language Models (LLMs) are emerging as powerful tools in healthcare, particularly for complex, domain-specific tasks. This study describes the development and evaluation of the PErioperative AI CHatbot (PEACH), a secure LLM-based system integrated with local perioperative guidelines to support preoperative clinical decision-making. PEACH was embedded with 35 institutional perioperative protocols in the secure Claude 3.5 Sonet LLM framework within Pair Chat (developed by Singapore Government) and tested in a silent deployment with real-world data. Accuracy, safety, and usability were assessed. Deviations and hallucinations were categorized based on potential harm, and user feedback was evaluated using the Technology Acceptance Model (TAM). Updates were made after the initial silent deployment to amend one protocol. In 240 real-world clinical iterations, PEACH achieved a first-generation accuracy of 97.5% (78/80) and an overall accuracy of 96.7% (232/240) across three iterations. The updated PEACH demonstrated improved accuracy of 97.9% (235/240), with a statistically significant difference from the null hypothesis of 95% accuracy (p = 0.018, 95% CI: 0.952-0.991). Minimal hallucinations and deviations were observed (both 1/240 and 2/240, respectively). Clinicians reported that PEACH expedited decisions in 95% of cases, and inter-rater reliability ranged from kappa 0.772-0.893 within PEACH and 0.610-0.784 among attendings. PEACH is an accurate, adaptable tool that enhances consistency and efficiency in perioperative decision-making. Future research should explore its scalability across specialties and its impact on clinical outcomes.
oRetrieval Augmented Generation for 10 Large Language Models and its Generalizability in Assessing Medical Fitness
Oct 11, 2024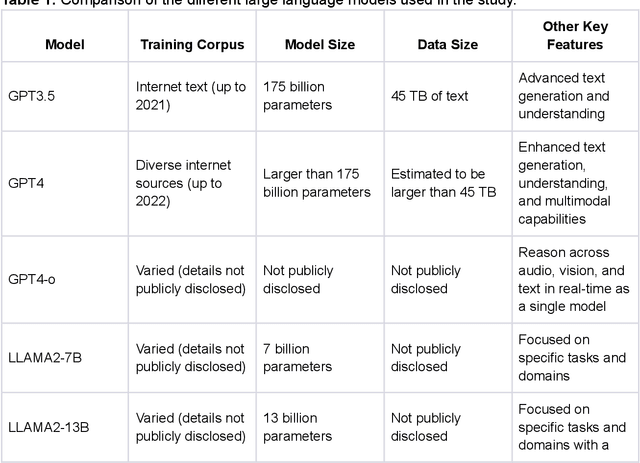



Large Language Models (LLMs) show potential for medical applications but often lack specialized clinical knowledge. Retrieval Augmented Generation (RAG) allows customization with domain-specific information, making it suitable for healthcare. This study evaluates the accuracy, consistency, and safety of RAG models in determining fitness for surgery and providing preoperative instructions. We developed LLM-RAG models using 35 local and 23 international preoperative guidelines and tested them against human-generated responses. A total of 3,682 responses were evaluated. Clinical documents were processed using Llamaindex, and 10 LLMs, including GPT3.5, GPT4, and Claude-3, were assessed. Fourteen clinical scenarios were analyzed, focusing on seven aspects of preoperative instructions. Established guidelines and expert judgment were used to determine correct responses, with human-generated answers serving as comparisons. The LLM-RAG models generated responses within 20 seconds, significantly faster than clinicians (10 minutes). The GPT4 LLM-RAG model achieved the highest accuracy (96.4% vs. 86.6%, p=0.016), with no hallucinations and producing correct instructions comparable to clinicians. Results were consistent across both local and international guidelines. This study demonstrates the potential of LLM-RAG models for preoperative healthcare tasks, highlighting their efficiency, scalability, and reliability.
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Mar 09, 2024Large Language Models (LLMs) have significantly advanced healthcare innovation on generation capabilities. However, their application in real clinical settings is challenging due to potential deviations from medical facts and inherent biases. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) with ranking and re-ranking techniques, aiming to improve free-text question-answering (QA) in the medical domain. Specifically, upon receiving a question, we initially retrieve triplets from a medical KG to gather factual information. Subsequently, we innovatively apply ranking methods to refine the ordering of these triplets, aiming to yield more precise answers. To the best of our knowledge, KG-Rank is the first application of ranking models combined with KG in medical QA specifically for generating long answers. Evaluation of four selected medical QA datasets shows that KG-Rank achieves an improvement of over 18% in the ROUGE-L score. Moreover, we extend KG-Rank to open domains, where it realizes a 14% improvement in ROUGE-L, showing the effectiveness and potential of KG-Rank.
Enhancing Diagnostic Accuracy through Multi-Agent Conversations: Using Large Language Models to Mitigate Cognitive Bias
Jan 26, 2024Background: Cognitive biases in clinical decision-making significantly contribute to errors in diagnosis and suboptimal patient outcomes. Addressing these biases presents a formidable challenge in the medical field. This study explores the role of large language models (LLMs) in mitigating these biases through the utilization of a multi-agent framework. We simulate the clinical decision-making processes through multi-agent conversation and evaluate its efficacy in improving diagnostic accuracy. Methods: A total of 16 published and unpublished case reports where cognitive biases have resulted in misdiagnoses were identified from the literature. In the multi-agent system, we leveraged GPT-4 Turbo to facilitate interactions among four simulated agents to replicate clinical team dynamics. Each agent has a distinct role: 1) To make the initial and final diagnosis after considering the discussions, 2) The devil's advocate and correct confirmation and anchoring bias, 3) The tutor and facilitator of the discussion to reduce premature closure bias, and 4) To record and summarize the findings. A total of 80 simulations were evaluated for the accuracy of initial diagnosis, top differential diagnosis and final two differential diagnoses. Findings: In a total of 80 responses evaluating both initial and final diagnoses, the initial diagnosis had an accuracy of 0% (0/80), but following multi-agent discussions, the accuracy for the top differential diagnosis increased to 71.3% (57/80), and for the final two differential diagnoses, to 80.0% (64/80). The system demonstrated an ability to reevaluate and correct misconceptions, even in scenarios with misleading initial investigations. Interpretation: The LLM-driven multi-agent conversation system shows promise in enhancing diagnostic accuracy in diagnostically challenging medical scenarios.