 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-Pose: Unpaired Full-Body Portrait Synthesis via Canonical UV Maps
Dec 19, 2025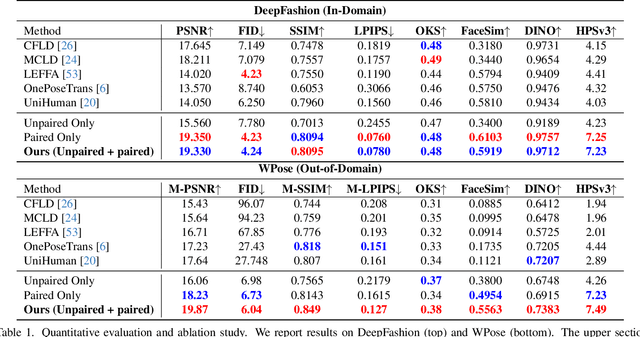
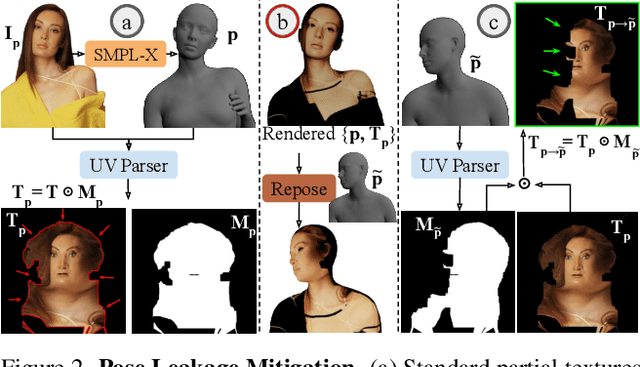
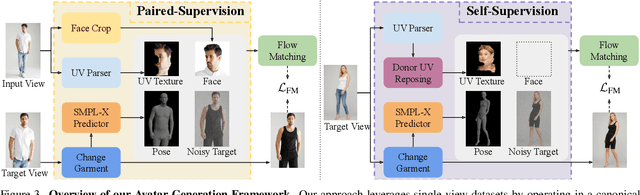

Photographs of people taken by professional photographers typically present the person in beautiful lighting, with an interesting pose, and flattering quality. This is unlike common photos people can take of themselves. In this paper, we explore how to create a ``professional'' version of a person's photograph, i.e., in a chosen pose, in a simple environment, with good lighting, and standard black top/bottom clothing. A key challenge is to preserve the person's unique identity, face and body features while transforming the photo. If there would exist a large paired dataset of the same person photographed both ``in the wild'' and by a professional photographer, the problem would potentially be easier to solve. However, such data does not exist, especially for a large variety of identities. To that end, we propose two key insights: 1) Our method transforms the input photo and person's face to a canonical UV space, which is further coupled with reposing methodology to model occlusions and novel view synthesis. Operating in UV space allows us to leverage existing unpaired datasets. 2) We personalize the output photo via multi image finetuning. Our approach yields high-quality, reposed portraits and achieves strong qualitative and quantitative performance on real-world imagery.
Test-Time Anchoring for Discrete Diffusion Posterior Sampling
Oct 02, 2025We study the problem of posterior sampling using pretrained discrete diffusion foundation models, aiming to recover images from noisy measurements without retraining task-specific models. While diffusion models have achieved remarkable success in generative modeling, most advances rely on continuous Gaussian diffusion. In contrast, discrete diffusion offers a unified framework for jointly modeling categorical data such as text and images. Beyond unification, discrete diffusion provides faster inference, finer control, and principled training-free Bayesian inference, making it particularly well-suited for posterior sampling. However, existing approaches to discrete diffusion posterior sampling face severe challenges: derivative-free guidance yields sparse signals, continuous relaxations limit applicability, and split Gibbs samplers suffer from the curse of dimensionality. To overcome these limitations, we introduce Anchored Posterior Sampling (APS) for masked diffusion foundation models, built on two key innovations -- quantized expectation for gradient-like guidance in discrete embedding space, and anchored remasking for adaptive decoding. Our approach achieves state-of-the-art performance among discrete diffusion samplers across linear and nonlinear inverse problems on the standard benchmarks. We further demonstrate the benefits of our approach in training-free stylization and text-guided editing.
UltraZoom: Generating Gigapixel Images from Regular Photos
Jun 16, 2025We present UltraZoom, a system for generating gigapixel-resolution images of objects from casually captured inputs, such as handheld phone photos. Given a full-shot image (global, low-detail) and one or more close-ups (local, high-detail), UltraZoom upscales the full image to match the fine detail and scale of the close-up examples. To achieve this, we construct a per-instance paired dataset from the close-ups and adapt a pretrained generative model to learn object-specific low-to-high resolution mappings. At inference, we apply the model in a sliding window fashion over the full image. Constructing these pairs is non-trivial: it requires registering the close-ups within the full image for scale estimation and degradation alignment. We introduce a simple, robust method for getting registration on arbitrary materials in casual, in-the-wild captures. Together, these components form a system that enables seamless pan and zoom across the entire object, producing consistent, photorealistic gigapixel imagery from minimal input.
Generating Fit Check Videos with a Handheld Camera
May 29, 2025Self-captured full-body videos are popular, but most deployments require mounted cameras, carefully-framed shots, and repeated practice. We propose a more convenient solution that enables full-body video capture using handheld mobile devices. Our approach takes as input two static photos (front and back) of you in a mirror, along with an IMU motion reference that you perform while holding your mobile phone, and synthesizes a realistic video of you performing a similar target motion. We enable rendering into a new scene, with consistent illumination and shadows. We propose a novel video diffusion-based model to achieve this. Specifically, we propose a parameter-free frame generation strategy, as well as a multi-reference attention mechanism, that effectively integrate appearance information from both the front and back selfies into the video diffusion model. Additionally, we introduce an image-based fine-tuning strategy to enhance frame sharpness and improve the generation of shadows and reflections, achieving a more realistic human-scene composition.
MusicInfuser: Making Video Diffusion Listen and Dance
Mar 18, 2025We introduce MusicInfuser, an approach for generating high-quality dance videos that are synchronized to a specified music track. Rather than attempting to design and train a new multimodal audio-video model, we show how existing video diffusion models can be adapted to align with musical inputs by introducing lightweight music-video cross-attention and a low-rank adapter. Unlike prior work requiring motion capture data, our approach fine-tunes only on dance videos. MusicInfuser achieves high-quality music-driven video generation while preserving the flexibility and generative capabilities of the underlying models. We introduce an evaluation framework using Video-LLMs to assess multiple dimensions of dance generation quality. The project page and code are available at https://susunghong.github.io/MusicInfuser.
Perturb-and-Revise: Flexible 3D Editing with Generative Trajectories
Dec 06, 2024The fields of 3D reconstruction and text-based 3D editing have advanced significantly with the evolution of text-based diffusion models. While existing 3D editing methods excel at modifying color, texture, and style, they struggle with extensive geometric or appearance changes, thus limiting their applications. We propose Perturb-and-Revise, which makes possible a variety of NeRF editing. First, we perturb the NeRF parameters with random initializations to create a versatile initialization. We automatically determine the perturbation magnitude through analysis of the local loss landscape. Then, we revise the edited NeRF via generative trajectories. Combined with the generative process, we impose identity-preserving gradients to refine the edited NeRF. Extensive experiments demonstrate that Perturb-and-Revise facilitates flexible, effective, and consistent editing of color, appearance, and geometry in 3D. For 360{\deg} results, please visit our project page: https://susunghong.github.io/Perturb-and-Revise.
Fashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024
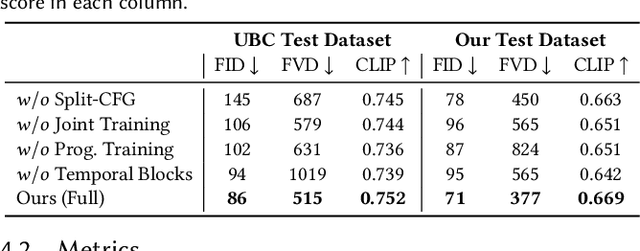
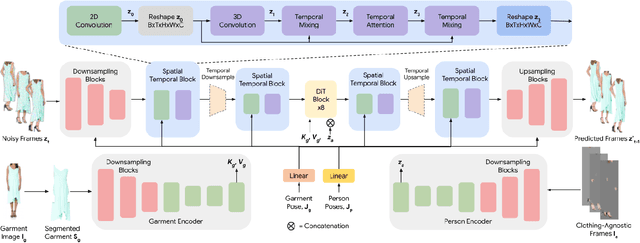
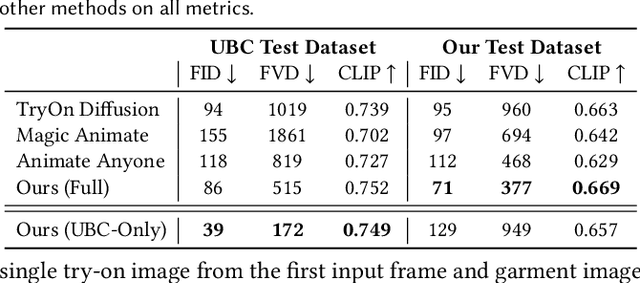
We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
Constrained Diffusion Implicit Models
Nov 01, 2024



This paper describes an efficient algorithm for solving noisy linear inverse problems using pretrained diffusion models. Extending the paradigm of denoising diffusion implicit models (DDIM), we propose constrained diffusion implicit models (CDIM) that modify the diffusion updates to enforce a constraint upon the final output. For noiseless inverse problems, CDIM exactly satisfies the constraints; in the noisy case, we generalize CDIM to satisfy an exact constraint on the residual distribution of the noise. Experiments across a variety of tasks and metrics show strong performance of CDIM, with analogous inference acceleration to unconstrained DDIM: 10 to 50 times faster than previous conditional diffusion methods. We demonstrate the versatility of our approach on many problems including super-resolution, denoising, inpainting, deblurring, and 3D point cloud reconstruction.
Inverse Painting: Reconstructing The Painting Process
Sep 30, 2024
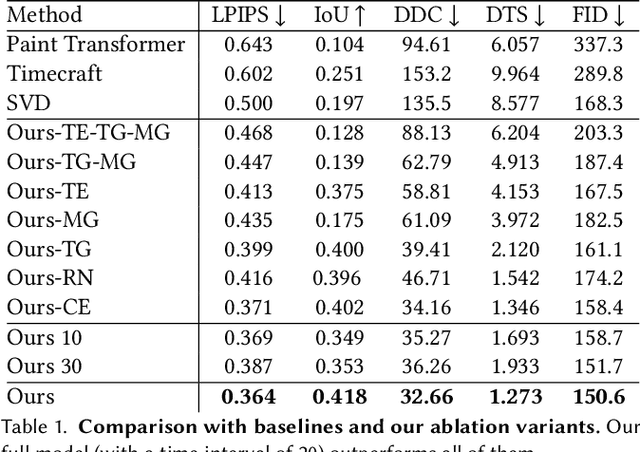

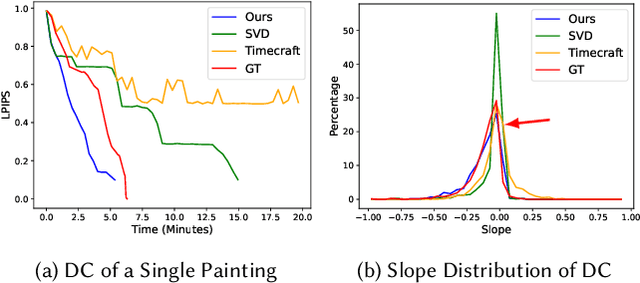
Given an input painting, we reconstruct a time-lapse video of how it may have been painted. We formulate this as an autoregressive image generation problem, in which an initially blank "canvas" is iteratively updated. The model learns from real artists by training on many painting videos. Our approach incorporates text and region understanding to define a set of painting "instructions" and updates the canvas with a novel diffusion-based renderer. The method extrapolates beyond the limited, acrylic style paintings on which it has been trained, showing plausible results for a wide range of artistic styles and genres.
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Aug 27, 2024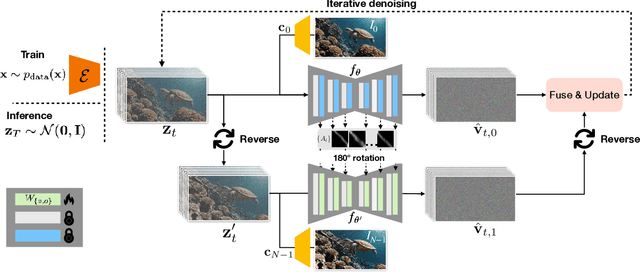
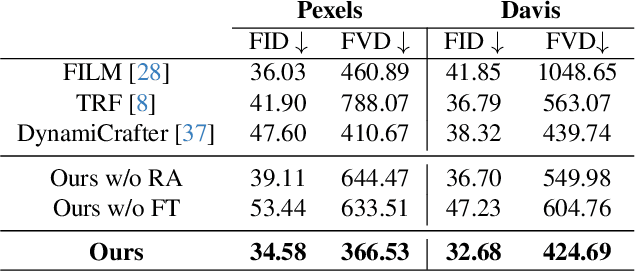
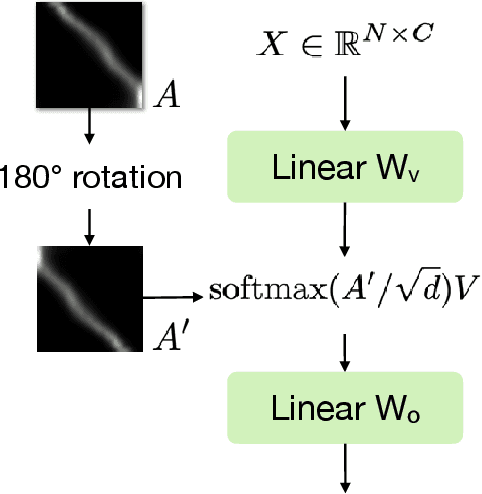

We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.