 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIT: A Large-Scale Dataset for Fit-Aware Virtual Try-On
Apr 09, 2026Given a person and a garment image, virtual try-on (VTO) aims to synthesize a realistic image of the person wearing the garment, while preserving their original pose and identity. Although recent VTO methods excel at visualizing garment appearance, they largely overlook a crucial aspect of the try-on experience: the accuracy of garment fit -- for example, depicting how an extra-large shirt looks on an extra-small person. A key obstacle is the absence of datasets that provide precise garment and body size information, particularly for "ill-fit" cases, where garments are significantly too large or too small. Consequently, current VTO methods default to generating well-fitted results regardless of the garment or person size. In this paper, we take the first steps towards solving this open problem. We introduce FIT (Fit-Inclusive Try-on), a large-scale VTO dataset comprising over 1.13M try-on image triplets accompanied by precise body and garment measurements. We overcome the challenges of data collection via a scalable synthetic strategy: (1) We programmatically generate 3D garments using GarmentCode and drape them via physics simulation to capture realistic garment fit. (2) We employ a novel re-texturing framework to transform synthetic renderings into photorealistic images while strictly preserving geometry. (3) We introduce person identity preservation into our re-texturing model to generate paired person images (same person, different garments) for supervised training. Finally, we leverage our FIT dataset to train a baseline fit-aware virtual try-on model. Our data and results set the new state-of-the-art for fit-aware virtual try-on, as well as offer a robust benchmark for future research. We will make all data and code publicly available on our project page: https://johannakarras.github.io/FIT.
Perturb-and-Revise: Flexible 3D Editing with Generative Trajectories
Dec 06, 2024



The fields of 3D reconstruction and text-based 3D editing have advanced significantly with the evolution of text-based diffusion models. While existing 3D editing methods excel at modifying color, texture, and style, they struggle with extensive geometric or appearance changes, thus limiting their applications. We propose Perturb-and-Revise, which makes possible a variety of NeRF editing. First, we perturb the NeRF parameters with random initializations to create a versatile initialization. We automatically determine the perturbation magnitude through analysis of the local loss landscape. Then, we revise the edited NeRF via generative trajectories. Combined with the generative process, we impose identity-preserving gradients to refine the edited NeRF. Extensive experiments demonstrate that Perturb-and-Revise facilitates flexible, effective, and consistent editing of color, appearance, and geometry in 3D. For 360{\deg} results, please visit our project page: https://susunghong.github.io/Perturb-and-Revise.
Fashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024
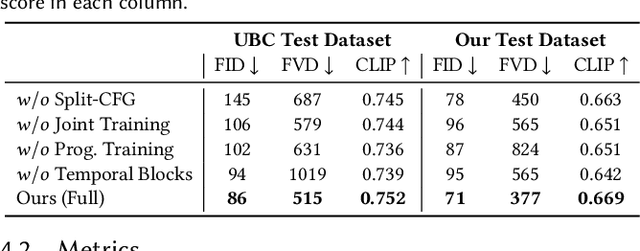
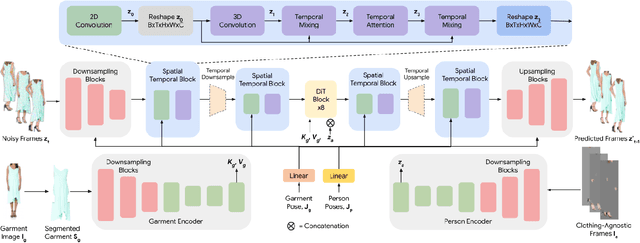
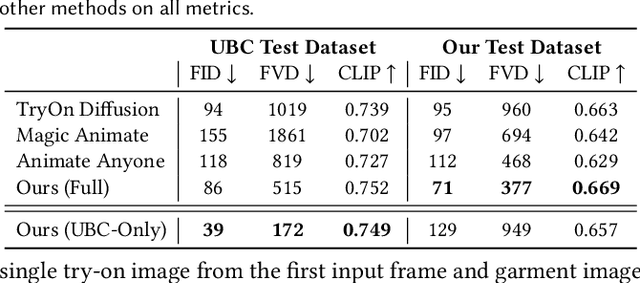
We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
May 04, 2023We present DreamPose, a diffusion-based method for generating animated fashion videos from still images. Given an image and a sequence of human body poses, our method synthesizes a video containing both human and fabric motion. To achieve this, we transform a pretrained text-to-image model (Stable Diffusion) into a pose-and-image guided video synthesis model, using a novel finetuning strategy, a set of architectural changes to support the added conditioning signals, and techniques to encourage temporal consistency. We fine-tune on a collection of fashion videos from the UBC Fashion dataset. We evaluate our method on a variety of clothing styles and poses, and demonstrate that our method produces state-of-the-art results on fashion video animation. Video results are available on our project page.