 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-Pose: Unpaired Full-Body Portrait Synthesis via Canonical UV Maps
Dec 19, 2025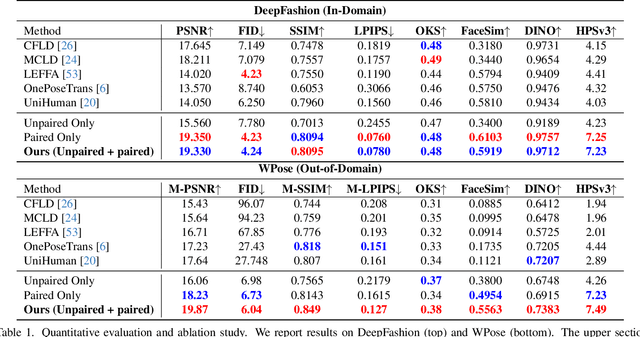
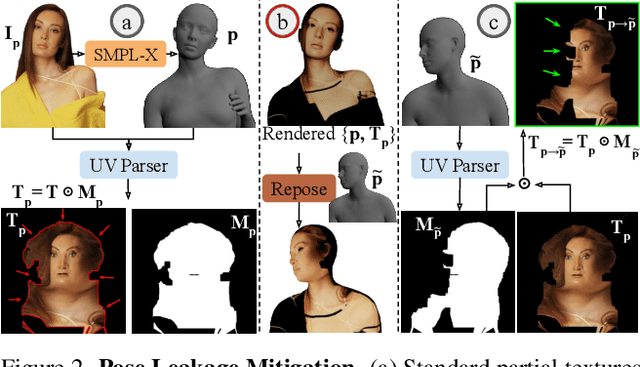
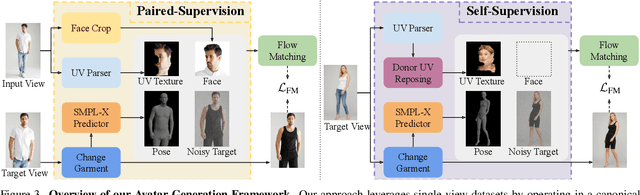

Photographs of people taken by professional photographers typically present the person in beautiful lighting, with an interesting pose, and flattering quality. This is unlike common photos people can take of themselves. In this paper, we explore how to create a ``professional'' version of a person's photograph, i.e., in a chosen pose, in a simple environment, with good lighting, and standard black top/bottom clothing. A key challenge is to preserve the person's unique identity, face and body features while transforming the photo. If there would exist a large paired dataset of the same person photographed both ``in the wild'' and by a professional photographer, the problem would potentially be easier to solve. However, such data does not exist, especially for a large variety of identities. To that end, we propose two key insights: 1) Our method transforms the input photo and person's face to a canonical UV space, which is further coupled with reposing methodology to model occlusions and novel view synthesis. Operating in UV space allows us to leverage existing unpaired datasets. 2) We personalize the output photo via multi image finetuning. Our approach yields high-quality, reposed portraits and achieves strong qualitative and quantitative performance on real-world imagery.
Test-Time Anchoring for Discrete Diffusion Posterior Sampling
Oct 02, 2025We study the problem of posterior sampling using pretrained discrete diffusion foundation models, aiming to recover images from noisy measurements without retraining task-specific models. While diffusion models have achieved remarkable success in generative modeling, most advances rely on continuous Gaussian diffusion. In contrast, discrete diffusion offers a unified framework for jointly modeling categorical data such as text and images. Beyond unification, discrete diffusion provides faster inference, finer control, and principled training-free Bayesian inference, making it particularly well-suited for posterior sampling. However, existing approaches to discrete diffusion posterior sampling face severe challenges: derivative-free guidance yields sparse signals, continuous relaxations limit applicability, and split Gibbs samplers suffer from the curse of dimensionality. To overcome these limitations, we introduce Anchored Posterior Sampling (APS) for masked diffusion foundation models, built on two key innovations -- quantized expectation for gradient-like guidance in discrete embedding space, and anchored remasking for adaptive decoding. Our approach achieves state-of-the-art performance among discrete diffusion samplers across linear and nonlinear inverse problems on the standard benchmarks. We further demonstrate the benefits of our approach in training-free stylization and text-guided editing.
CATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
Fashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024
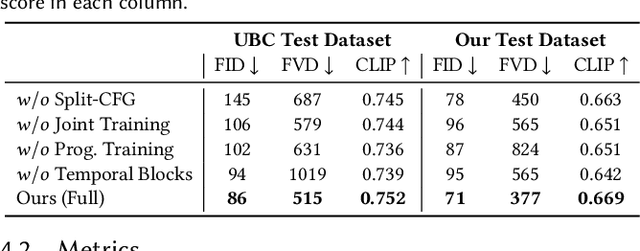
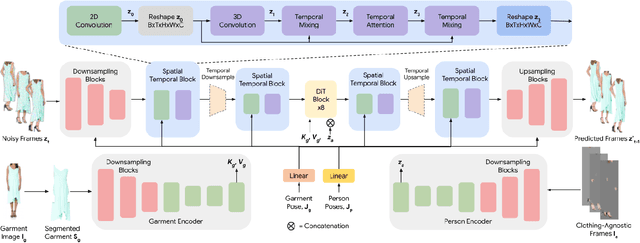
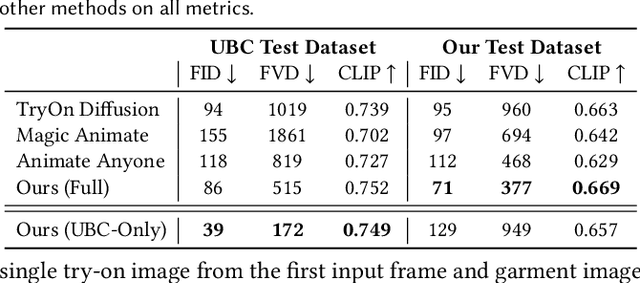
We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
ReBotNet: Fast Real-time Video Enhancement
Mar 23, 2023Most video restoration networks are slow, have high computational load, and can't be used for real-time video enhancement. In this work, we design an efficient and fast framework to perform real-time video enhancement for practical use-cases like live video calls and video streams. Our proposed method, called Recurrent Bottleneck Mixer Network (ReBotNet), employs a dual-branch framework. The first branch learns spatio-temporal features by tokenizing the input frames along the spatial and temporal dimensions using a ConvNext-based encoder and processing these abstract tokens using a bottleneck mixer. To further improve temporal consistency, the second branch employs a mixer directly on tokens extracted from individual frames. A common decoder then merges the features form the two branches to predict the enhanced frame. In addition, we propose a recurrent training approach where the last frame's prediction is leveraged to efficiently enhance the current frame while improving temporal consistency. To evaluate our method, we curate two new datasets that emulate real-world video call and streaming scenarios, and show extensive results on multiple datasets where ReBotNet outperforms existing approaches with lower computations, reduced memory requirements, and faster inference time.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022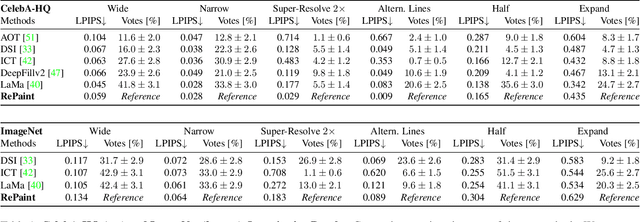
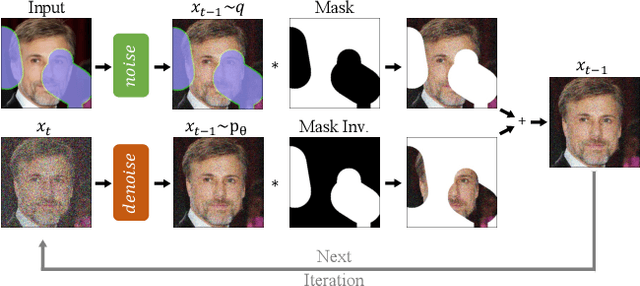


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Normalizing Flow as a Flexible Fidelity Objective for Photo-Realistic Super-resolution
Nov 05, 2021
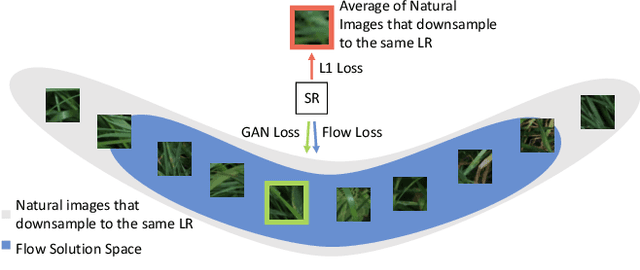
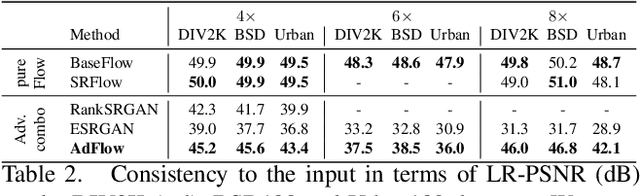
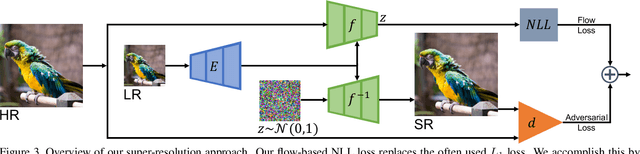
Super-resolution is an ill-posed problem, where a ground-truth high-resolution image represents only one possibility in the space of plausible solutions. Yet, the dominant paradigm is to employ pixel-wise losses, such as L_1, which drive the prediction towards a blurry average. This leads to fundamentally conflicting objectives when combined with adversarial losses, which degrades the final quality. We address this issue by revisiting the L_1 loss and show that it corresponds to a one-layer conditional flow. Inspired by this relation, we explore general flows as a fidelity-based alternative to the L_1 objective. We demonstrate that the flexibility of deeper flows leads to better visual quality and consistency when combined with adversarial losses. We conduct extensive user studies for three datasets and scale factors, where our approach is shown to outperform state-of-the-art methods for photo-realistic super-resolution. Code and trained models will be available at: git.io/AdFlow
Hierarchical Conditional Flow: A Unified Framework for Image Super-Resolution and Image Rescaling
Aug 11, 2021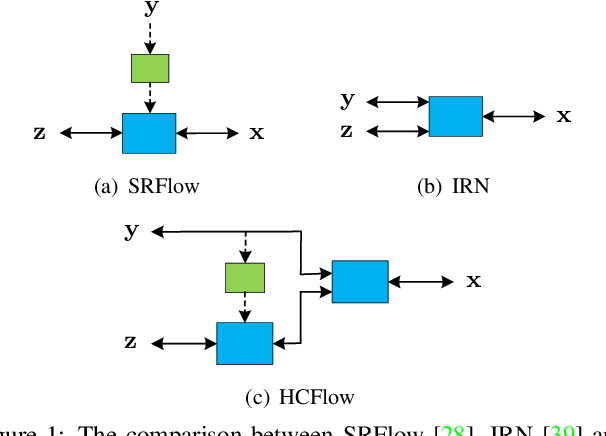

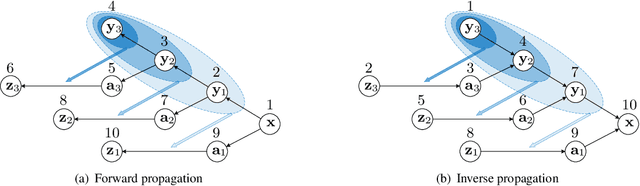
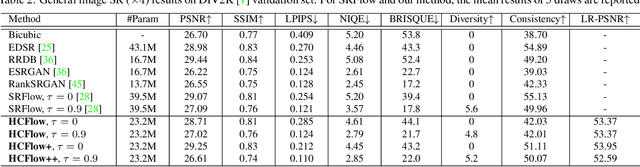
Normalizing flows have recently demonstrated promising results for low-level vision tasks. For image super-resolution (SR), it learns to predict diverse photo-realistic high-resolution (HR) images from the low-resolution (LR) image rather than learning a deterministic mapping. For image rescaling, it achieves high accuracy by jointly modelling the downscaling and upscaling processes. While existing approaches employ specialized techniques for these two tasks, we set out to unify them in a single formulation. In this paper, we propose the hierarchical conditional flow (HCFlow) as a unified framework for image SR and image rescaling. More specifically, HCFlow learns a bijective mapping between HR and LR image pairs by modelling the distribution of the LR image and the rest high-frequency component simultaneously. In particular, the high-frequency component is conditional on the LR image in a hierarchical manner. To further enhance the performance, other losses such as perceptual loss and GAN loss are combined with the commonly used negative log-likelihood loss in training. Extensive experiments on general image SR, face image SR and image rescaling have demonstrated that the proposed HCFlow achieves state-of-the-art performance in terms of both quantitative metrics and visual quality.
DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows
Jan 14, 2021
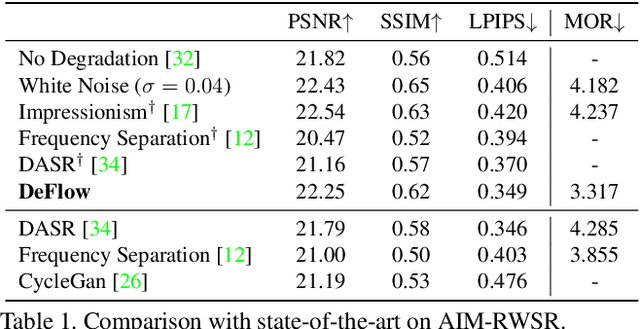
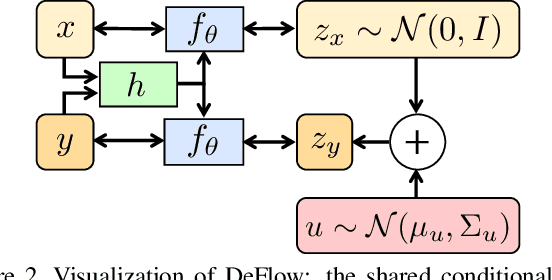
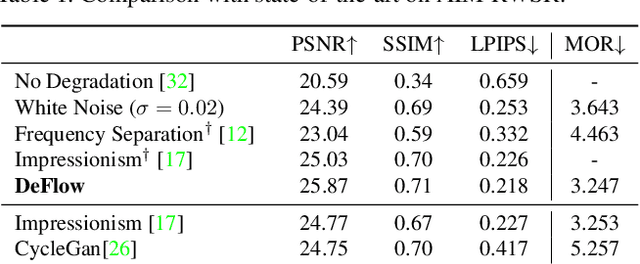
The difficulty of obtaining paired data remains a major bottleneck for learning image restoration and enhancement models for real-world applications. Current strategies aim to synthesize realistic training data by modeling noise and degradations that appear in real-world settings. We propose DeFlow, a method for learning stochastic image degradations from unpaired data. Our approach is based on a novel unpaired learning formulation for conditional normalizing flows. We model the degradation process in the latent space of a shared flow encoder-decoder network. This allows us to learn the conditional distribution of a noisy image given the clean input by solely minimizing the negative log-likelihood of the marginal distributions. We validate our DeFlow formulation on the task of joint image restoration and super-resolution. The models trained with the synthetic data generated by DeFlow outperform previous learnable approaches on all three datasets.
SRFlow: Learning the Super-Resolution Space with Normalizing Flow
Jun 25, 2020

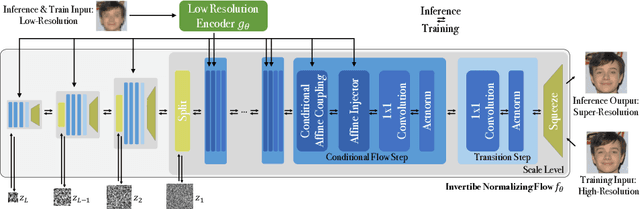
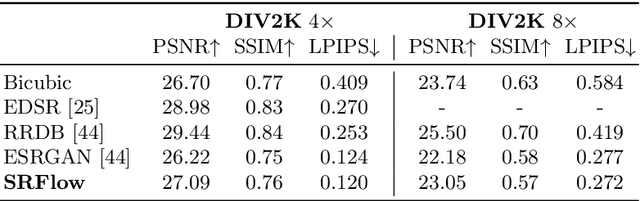
Super-resolution is an ill-posed problem, since it allows for multiple predictions for a given low-resolution image. This fundamental fact is largely ignored by state-of-the-art deep learning based approaches. These methods instead train a deterministic mapping using combinations of reconstruction and adversarial losses. In this work, we therefore propose SRFlow: a normalizing flow based super-resolution method capable of learning the conditional distribution of the output given the low-resolution input. Our model is trained in a principled manner using a single loss, namely the negative log-likelihood. SRFlow therefore directly accounts for the ill-posed nature of the problem, and learns to predict diverse photo-realistic high-resolution images. Moreover, we utilize the strong image posterior learned by SRFlow to design flexible image manipulation techniques, capable of enhancing super-resolved images by, e.g., transferring content from other images. We perform extensive experiments on faces, as well as on super-resolution in general. SRFlow outperforms state-of-the-art GAN-based approaches in terms of both PSNR and perceptual quality metrics, while allowing for diversity through the exploration of the space of super-resolved solutions.