 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealisMotion: Decomposed Human Motion Control and Video Generation in the World Space
Aug 12, 2025Generating human videos with realistic and controllable motions is a challenging task. While existing methods can generate visually compelling videos, they lack separate control over four key video elements: foreground subject, background video, human trajectory and action patterns. In this paper, we propose a decomposed human motion control and video generation framework that explicitly decouples motion from appearance, subject from background, and action from trajectory, enabling flexible mix-and-match composition of these elements. Concretely, we first build a ground-aware 3D world coordinate system and perform motion editing directly in the 3D space. Trajectory control is implemented by unprojecting edited 2D trajectories into 3D with focal-length calibration and coordinate transformation, followed by speed alignment and orientation adjustment; actions are supplied by a motion bank or generated via text-to-motion methods. Then, based on modern text-to-video diffusion transformer models, we inject the subject as tokens for full attention, concatenate the background along the channel dimension, and add motion (trajectory and action) control signals by addition. Such a design opens up the possibility for us to generate realistic videos of anyone doing anything anywhere. Extensive experiments on benchmark datasets and real-world cases demonstrate that our method achieves state-of-the-art performance on both element-wise controllability and overall video quality.
Uni3C: Unifying Precisely 3D-Enhanced Camera and Human Motion Controls for Video Generation
Apr 21, 2025



Camera and human motion controls have been extensively studied for video generation, but existing approaches typically address them separately, suffering from limited data with high-quality annotations for both aspects. To overcome this, we present Uni3C, a unified 3D-enhanced framework for precise control of both camera and human motion in video generation. Uni3C includes two key contributions. First, we propose a plug-and-play control module trained with a frozen video generative backbone, PCDController, which utilizes unprojected point clouds from monocular depth to achieve accurate camera control. By leveraging the strong 3D priors of point clouds and the powerful capacities of video foundational models, PCDController shows impressive generalization, performing well regardless of whether the inference backbone is frozen or fine-tuned. This flexibility enables different modules of Uni3C to be trained in specific domains, i.e., either camera control or human motion control, reducing the dependency on jointly annotated data. Second, we propose a jointly aligned 3D world guidance for the inference phase that seamlessly integrates both scenic point clouds and SMPL-X characters to unify the control signals for camera and human motion, respectively. Extensive experiments confirm that PCDController enjoys strong robustness in driving camera motion for fine-tuned backbones of video generation. Uni3C substantially outperforms competitors in both camera controllability and human motion quality. Additionally, we collect tailored validation sets featuring challenging camera movements and human actions to validate the effectiveness of our method.
Low-Light Image Enhancement using Event-Based Illumination Estimation
Apr 13, 2025Low-light image enhancement (LLIE) aims to improve the visibility of images captured in poorly lit environments. Prevalent event-based solutions primarily utilize events triggered by motion, i.e., ''motion events'' to strengthen only the edge texture, while leaving the high dynamic range and excellent low-light responsiveness of event cameras largely unexplored. This paper instead opens a new avenue from the perspective of estimating the illumination using ''temporal-mapping'' events, i.e., by converting the timestamps of events triggered by a transmittance modulation into brightness values. The resulting fine-grained illumination cues facilitate a more effective decomposition and enhancement of the reflectance component in low-light images through the proposed Illumination-aided Reflectance Enhancement module. Furthermore, the degradation model of temporal-mapping events under low-light condition is investigated for realistic training data synthesizing. To address the lack of datasets under this regime, we construct a beam-splitter setup and collect EvLowLight dataset that includes images, temporal-mapping events, and motion events. Extensive experiments across 5 synthetic datasets and our real-world EvLowLight dataset substantiate that the devised pipeline, dubbed RetinEV, excels in producing well-illuminated, high dynamic range images, outperforming previous state-of-the-art event-based methods by up to 6.62 dB, while maintaining an efficient inference speed of 35.6 frame-per-second on a 640X480 image.
Hierarchical Information Flow for Generalized Efficient Image Restoration
Nov 27, 2024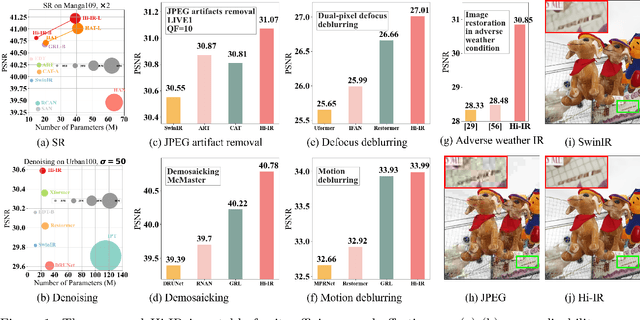


While vision transformers show promise in numerous image restoration (IR) tasks, the challenge remains in efficiently generalizing and scaling up a model for multiple IR tasks. To strike a balance between efficiency and model capacity for a generalized transformer-based IR method, we propose a hierarchical information flow mechanism for image restoration, dubbed Hi-IR, which progressively propagates information among pixels in a bottom-up manner. Hi-IR constructs a hierarchical information tree representing the degraded image across three levels. Each level encapsulates different types of information, with higher levels encompassing broader objects and concepts and lower levels focusing on local details. Moreover, the hierarchical tree architecture removes long-range self-attention, improves the computational efficiency and memory utilization, thus preparing it for effective model scaling. Based on that, we explore model scaling to improve our method's capabilities, which is expected to positively impact IR in large-scale training settings. Extensive experimental results show that Hi-IR achieves state-of-the-art performance in seven common image restoration tasks, affirming its effectiveness and generalizability.
Sharing Key Semantics in Transformer Makes Efficient Image Restoration
May 30, 2024

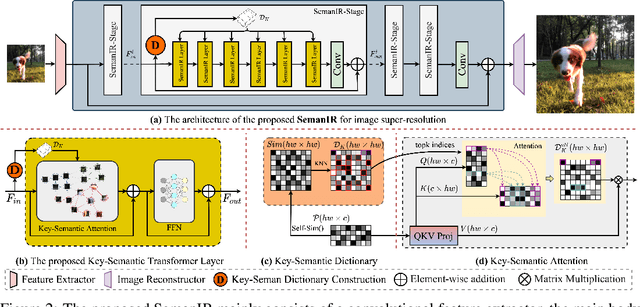

Image Restoration (IR), a classic low-level vision task, has witnessed significant advancements through deep models that effectively model global information. Notably, the Vision Transformers (ViTs) emergence has further propelled these advancements. When computing, the self-attention mechanism, a cornerstone of ViTs, tends to encompass all global cues, even those from semantically unrelated objects or regions. This inclusivity introduces computational inefficiencies, particularly noticeable with high input resolution, as it requires processing irrelevant information, thereby impeding efficiency. Additionally, for IR, it is commonly noted that small segments of a degraded image, particularly those closely aligned semantically, provide particularly relevant information to aid in the restoration process, as they contribute essential contextual cues crucial for accurate reconstruction. To address these challenges, we propose boosting IR's performance by sharing the key semantics via Transformer for IR (i.e., SemanIR) in this paper. Specifically, SemanIR initially constructs a sparse yet comprehensive key-semantic dictionary within each transformer stage by establishing essential semantic connections for every degraded patch. Subsequently, this dictionary is shared across all subsequent transformer blocks within the same stage. This strategy optimizes attention calculation within each block by focusing exclusively on semantically related components stored in the key-semantic dictionary. As a result, attention calculation achieves linear computational complexity within each window. Extensive experiments across 6 IR tasks confirm the proposed SemanIR's state-of-the-art performance, quantitatively and qualitatively showcasing advancements.
Key-Graph Transformer for Image Restoration
Feb 04, 2024While it is crucial to capture global information for effective image restoration (IR), integrating such cues into transformer-based methods becomes computationally expensive, especially with high input resolution. Furthermore, the self-attention mechanism in transformers is prone to considering unnecessary global cues from unrelated objects or regions, introducing computational inefficiencies. In response to these challenges, we introduce the Key-Graph Transformer (KGT) in this paper. Specifically, KGT views patch features as graph nodes. The proposed Key-Graph Constructor efficiently forms a sparse yet representative Key-Graph by selectively connecting essential nodes instead of all the nodes. Then the proposed Key-Graph Attention is conducted under the guidance of the Key-Graph only among selected nodes with linear computational complexity within each window. Extensive experiments across 6 IR tasks confirm the proposed KGT's state-of-the-art performance, showcasing advancements both quantitatively and qualitatively.
MoVideo: Motion-Aware Video Generation with Diffusion Models
Nov 19, 2023



While recent years have witnessed great progress on using diffusion models for video generation, most of them are simple extensions of image generation frameworks, which fail to explicitly consider one of the key differences between videos and images, i.e., motion. In this paper, we propose a novel motion-aware video generation (MoVideo) framework that takes motion into consideration from two aspects: video depth and optical flow. The former regulates motion by per-frame object distances and spatial layouts, while the later describes motion by cross-frame correspondences that help in preserving fine details and improving temporal consistency. More specifically, given a key frame that exists or generated from text prompts, we first design a diffusion model with spatio-temporal modules to generate the video depth and the corresponding optical flows. Then, the video is generated in the latent space by another spatio-temporal diffusion model under the guidance of depth, optical flow-based warped latent video and the calculated occlusion mask. Lastly, we use optical flows again to align and refine different frames for better video decoding from the latent space to the pixel space. In experiments, MoVideo achieves state-of-the-art results in both text-to-video and image-to-video generation, showing promising prompt consistency, frame consistency and visual quality.
Denoising Diffusion Models for Plug-and-Play Image Restoration
May 15, 2023



Plug-and-play Image Restoration (IR) has been widely recognized as a flexible and interpretable method for solving various inverse problems by utilizing any off-the-shelf denoiser as the implicit image prior. However, most existing methods focus on discriminative Gaussian denoisers. Although diffusion models have shown impressive performance for high-quality image synthesis, their potential to serve as a generative denoiser prior to the plug-and-play IR methods remains to be further explored. While several other attempts have been made to adopt diffusion models for image restoration, they either fail to achieve satisfactory results or typically require an unacceptable number of Neural Function Evaluations (NFEs) during inference. This paper proposes DiffPIR, which integrates the traditional plug-and-play method into the diffusion sampling framework. Compared to plug-and-play IR methods that rely on discriminative Gaussian denoisers, DiffPIR is expected to inherit the generative ability of diffusion models. Experimental results on three representative IR tasks, including super-resolution, image deblurring, and inpainting, demonstrate that DiffPIR achieves state-of-the-art performance on both the FFHQ and ImageNet datasets in terms of reconstruction faithfulness and perceptual quality with no more than 100 NFEs. The source code is available at {\url{https://github.com/yuanzhi-zhu/DiffPIR}}
Event-Based Frame Interpolation with Ad-hoc Deblurring
Jan 12, 2023


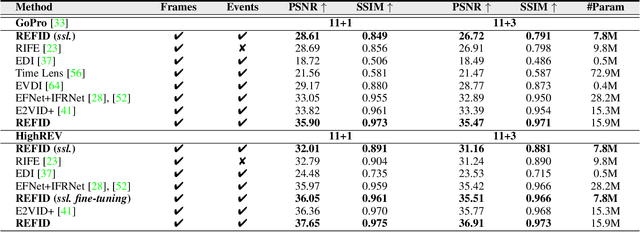
The performance of video frame interpolation is inherently correlated with the ability to handle motion in the input scene. Even though previous works recognize the utility of asynchronous event information for this task, they ignore the fact that motion may or may not result in blur in the input video to be interpolated, depending on the length of the exposure time of the frames and the speed of the motion, and assume either that the input video is sharp, restricting themselves to frame interpolation, or that it is blurry, including an explicit, separate deblurring stage before interpolation in their pipeline. We instead propose a general method for event-based frame interpolation that performs deblurring ad-hoc and thus works both on sharp and blurry input videos. Our model consists in a bidirectional recurrent network that naturally incorporates the temporal dimension of interpolation and fuses information from the input frames and the events adaptively based on their temporal proximity. In addition, we introduce a novel real-world high-resolution dataset with events and color videos named HighREV, which provides a challenging evaluation setting for the examined task. Extensive experiments on the standard GoPro benchmark and on our dataset show that our network consistently outperforms previous state-of-the-art methods on frame interpolation, single image deblurring and the joint task of interpolation and deblurring. Our code and dataset will be made publicly available.
Practical Real Video Denoising with Realistic Degradation Model
Aug 25, 2022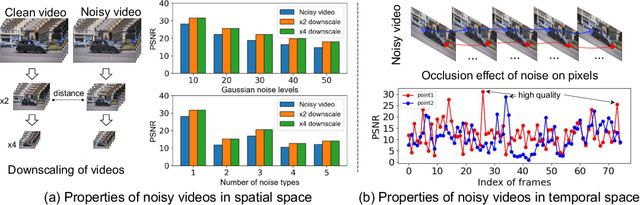
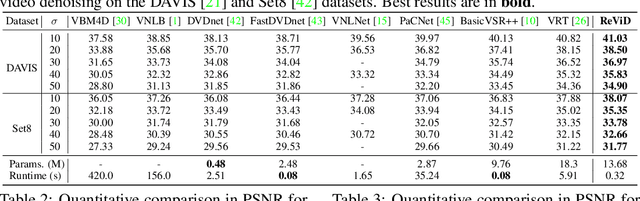
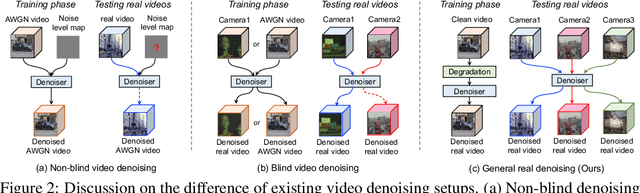
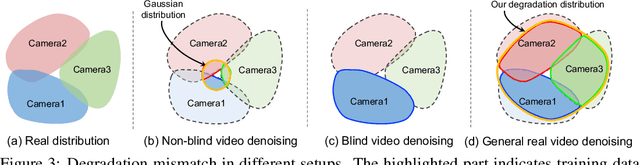
Existing video denoising methods typically assume noisy videos are degraded from clean videos by adding Gaussian noise. However, deep models trained on such a degradation assumption will inevitably give rise to poor performance for real videos due to degradation mismatch. Although some studies attempt to train deep models on noisy and noise-free video pairs captured by cameras, such models can only work well for specific cameras and do not generalize well for other videos. In this paper, we propose to lift this limitation and focus on the problem of general real video denoising with the aim to generalize well on unseen real-world videos. We tackle this problem by firstly investigating the common behaviors of video noises and observing two important characteristics: 1) downscaling helps to reduce the noise level in spatial space and 2) the information from the adjacent frames help to remove the noise of current frame in temporal space. Motivated by these two observations, we propose a multi-scale recurrent architecture by making full use of the above two characteristics. Secondly, we propose a synthetic real noise degradation model by randomly shuffling different noise types to train the denoising model. With a synthesized and enriched degradation space, our degradation model can help to bridge the distribution gap between training data and real-world data. Extensive experiments demonstrate that our proposed method achieves the state-of-the-art performance and better generalization ability than existing methods on both synthetic Gaussian denoising and practical real video denoising.