 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterDeepResearch: Enabling Human-Agent Collaborative Information Seeking through Interactive Deep Research
Mar 13, 2026Deep research systems powered by LLM agents have transformed complex information seeking by automating the iterative retrieval, filtering, and synthesis of insights from massive-scale web sources. However, existing systems predominantly follow an autonomous "query-to-report" paradigm, limiting users to a passive role and failing to integrate their personal insights, contextual knowledge, and evolving research intents. This paper addresses the lack of human-in-the-loop collaboration in the agentic research process. Through a formative study, we identify that current systems hinder effective human-agent collaboration in terms of process observability, real-time steerability, and context navigation efficiency. Informed by these findings, we propose InterDeepResearch, an interactive deep research system backed by a dedicated research context management framework. The framework organizes research context into a hierarchical architecture with three levels (information, actions, and sessions), enabling dynamic context reduction to prevent LLM context exhaustion and cross-action backtracing for evidence provenance. Built upon this framework, the system interface integrates three coordinated views for visual sensemaking, and dedicated interaction mechanisms for interactive research context navigation. Evaluation on the Xbench-DeepSearch-v1 and Seal-0 benchmarks shows that InterDeepResearch achieves competitive performance compared to state-of-the-art deep research systems, while a formal user study demonstrates its effectiveness in supporting human-agent collaborative information seeking. Project page with system demo: https://github.com/bopan3/InterDeepResearch.
Towards Universal Computational Aberration Correction in Photographic Cameras: A Comprehensive Benchmark Analysis
Mar 12, 2026Prevalent Computational Aberration Correction (CAC) methods are typically tailored to specific optical systems, leading to poor generalization and labor-intensive re-training for new lenses. Developing CAC paradigms capable of generalizing across diverse photographic lenses offers a promising solution to these challenges. However, efforts to achieve such cross-lens universality within consumer photography are still in their early stages due to the lack of a comprehensive benchmark that encompasses a sufficiently wide range of optical aberrations. Furthermore, it remains unclear which specific factors influence existing CAC methods and how these factors affect their performance. In this paper, we present comprehensive experiments and evaluations involving 24 image restoration and CAC algorithms, utilizing our newly proposed UniCAC, a large-scale benchmark for photographic cameras constructed via automatic optical design. The Optical Degradation Evaluator (ODE) is introduced as a novel framework to objectively assess the difficulty of CAC tasks, offering credible quantification of optical aberrations and enabling reliable evaluation. Drawing on our comparative analysis, we identify three key factors -- prior utilization, network architecture, and training strategy -- that most significantly influence CAC performance, and further investigate their respective effects. We believe that our benchmark, dataset, and observations contribute foundational insights to related areas and lay the groundwork for future investigations. Benchmarks, codes, and Zemax files will be available at https://github.com/XiaolongQian/UniCAC.
UrbanMoE: A Sparse Multi-Modal Mixture-of-Experts Framework for Multi-Task Urban Region Profiling
Jan 30, 2026Urban region profiling, the task of characterizing geographical areas, is crucial for urban planning and resource allocation. However, existing research in this domain faces two significant limitations. First, most methods are confined to single-task prediction, failing to capture the interconnected, multi-faceted nature of urban environments where numerous indicators are deeply correlated. Second, the field lacks a standardized experimental benchmark, which severely impedes fair comparison and reproducible progress. To address these challenges, we first establish a comprehensive benchmark for multi-task urban region profiling, featuring multi-modal features and a diverse set of strong baselines to ensure a fair and rigorous evaluation environment. Concurrently, we propose UrbanMoE, the first sparse multi-modal, multi-expert framework specifically architected to solve the multi-task challenge. Leveraging a sparse Mixture-of-Experts architecture, it dynamically routes multi-modal features to specialized sub-networks, enabling the simultaneous prediction of diverse urban indicators. We conduct extensive experiments on three real-world datasets within our benchmark, where UrbanMoE consistently demonstrates superior performance over all baselines. Further in-depth analysis validates the efficacy and efficiency of our approach, setting a new state-of-the-art and providing the community with a valuable tool for future research in urban analytics
Towards Real-world Lens Active Alignment with Unlabeled Data via Domain Adaptation
Jan 08, 2026Active Alignment (AA) is a key technology for the large-scale automated assembly of high-precision optical systems. Compared with labor-intensive per-model on-device calibration, a digital-twin pipeline built on optical simulation offers a substantial advantage in generating large-scale labeled data. However, complex imaging conditions induce a domain gap between simulation and real-world images, limiting the generalization of simulation-trained models. To address this, we propose augmenting a simulation baseline with minimal unlabeled real-world images captured at random misalignment positions, mitigating the gap from a domain adaptation perspective. We introduce Domain Adaptive Active Alignment (DA3), which utilizes an autoregressive domain transformation generator and an adversarial-based feature alignment strategy to distill real-world domain information via self-supervised learning. This enables the extraction of domain-invariant image degradation features to facilitate robust misalignment prediction. Experiments on two lens types reveal that DA3 improves accuracy by 46% over a purely simulation pipeline. Notably, it approaches the performance achieved with precisely labeled real-world data collected on 3 lens samples, while reducing on-device data collection time by 98.7%. The results demonstrate that domain adaptation effectively endows simulation-trained models with robust real-world performance, validating the digital-twin pipeline as a practical solution to significantly enhance the efficiency of large-scale optical assembly.
Nondeterministic Polynomial-time Problem Challenge: An Ever-Scaling Reasoning Benchmark for LLMs
Apr 15, 2025Reasoning is the fundamental capability of large language models (LLMs). Due to the rapid progress of LLMs, there are two main issues of current benchmarks: i) these benchmarks can be crushed in a short time (less than 1 year), and ii) these benchmarks may be easily hacked. To handle these issues, we propose the ever-scalingness for building the benchmarks which are uncrushable, unhackable, auto-verifiable and general. This paper presents Nondeterministic Polynomial-time Problem Challenge (NPPC), an ever-scaling reasoning benchmark for LLMs. Specifically, the NPPC has three main modules: i) npgym, which provides a unified interface of 25 well-known NP-complete problems and can generate any number of instances with any levels of complexities, ii) npsolver: which provides a unified interface to evaluate the problem instances with both online and offline models via APIs and local deployments, respectively, and iii) npeval: which provides the comprehensive and ready-to-use tools to analyze the performances of LLMs over different problems, the number of tokens, the aha moments, the reasoning errors and the solution errors. Extensive experiments over widely-used LLMs demonstrate: i) NPPC can successfully decrease the performances of advanced LLMs' performances to below 10%, demonstrating that NPPC is uncrushable, ii) DeepSeek-R1, Claude-3.7-Sonnet, and o1/o3-mini are the most powerful LLMs, where DeepSeek-R1 outperforms Claude-3.7-Sonnet and o1/o3-mini in most NP-complete problems considered, and iii) the numbers of tokens, aha moments in the advanced LLMs, e.g., Claude-3.7-Sonnet and DeepSeek-R1, are observed first to increase and then decrease when the problem instances become more and more difficult. We believe that NPPC is the first ever-scaling reasoning benchmark, serving as the uncrushable and unhackable testbed for LLMs toward artificial general intelligence (AGI).
DexGrasp Anything: Towards Universal Robotic Dexterous Grasping with Physics Awareness
Mar 11, 2025



A dexterous hand capable of grasping any object is essential for the development of general-purpose embodied intelligent robots. However, due to the high degree of freedom in dexterous hands and the vast diversity of objects, generating high-quality, usable grasping poses in a robust manner is a significant challenge. In this paper, we introduce DexGrasp Anything, a method that effectively integrates physical constraints into both the training and sampling phases of a diffusion-based generative model, achieving state-of-the-art performance across nearly all open datasets. Additionally, we present a new dexterous grasping dataset containing over 3.4 million diverse grasping poses for more than 15k different objects, demonstrating its potential to advance universal dexterous grasping. The code of our method and our dataset will be publicly released soon.
Benchmarking the Robustness of Optical Flow Estimation to Corruptions
Nov 22, 2024



Optical flow estimation is extensively used in autonomous driving and video editing. While existing models demonstrate state-of-the-art performance across various benchmarks, the robustness of these methods has been infrequently investigated. Despite some research focusing on the robustness of optical flow models against adversarial attacks, there has been a lack of studies investigating their robustness to common corruptions. Taking into account the unique temporal characteristics of optical flow, we introduce 7 temporal corruptions specifically designed for benchmarking the robustness of optical flow models, in addition to 17 classical single-image corruptions, in which advanced PSF Blur simulation method is performed. Two robustness benchmarks, KITTI-FC and GoPro-FC, are subsequently established as the first corruption robustness benchmark for optical flow estimation, with Out-Of-Domain (OOD) and In-Domain (ID) settings to facilitate comprehensive studies. Robustness metrics, Corruption Robustness Error (CRE), Corruption Robustness Error ratio (CREr), and Relative Corruption Robustness Error (RCRE) are further introduced to quantify the optical flow estimation robustness. 29 model variants from 15 optical flow methods are evaluated, yielding 10 intriguing observations, such as 1) the absolute robustness of the model is heavily dependent on the estimation performance; 2) the corruptions that diminish local information are more serious than that reduce visual effects. We also give suggestions for the design and application of optical flow models. We anticipate that our benchmark will serve as a foundational resource for advancing research in robust optical flow estimation. The benchmarks and source code will be released at https://github.com/ZhonghuaYi/optical_flow_robustness_benchmark.
EI-Nexus: Towards Unmediated and Flexible Inter-Modality Local Feature Extraction and Matching for Event-Image Data
Oct 29, 2024



Event cameras, with high temporal resolution and high dynamic range, have limited research on the inter-modality local feature extraction and matching of event-image data. We propose EI-Nexus, an unmediated and flexible framework that integrates two modality-specific keypoint extractors and a feature matcher. To achieve keypoint extraction across viewpoint and modality changes, we bring Local Feature Distillation (LFD), which transfers the viewpoint consistency from a well-learned image extractor to the event extractor, ensuring robust feature correspondence. Furthermore, with the help of Context Aggregation (CA), a remarkable enhancement is observed in feature matching. We further establish the first two inter-modality feature matching benchmarks, MVSEC-RPE and EC-RPE, to assess relative pose estimation on event-image data. Our approach outperforms traditional methods that rely on explicit modal transformation, offering more unmediated and adaptable feature extraction and matching, achieving better keypoint similarity and state-of-the-art results on the MVSEC-RPE and EC-RPE benchmarks. The source code and benchmarks will be made publicly available at https://github.com/ZhonghuaYi/EI-Nexus_official.
EEPNet: Efficient Edge Pixel-based Matching Network for Cross-Modal Dynamic Registration between LiDAR and Camera
Sep 28, 2024


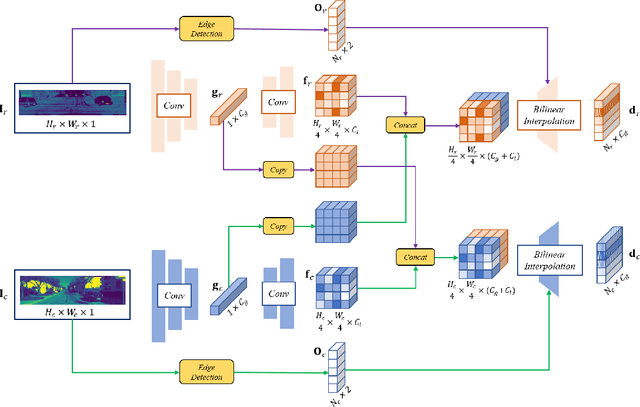
Multisensor fusion is essential for autonomous vehicles to accurately perceive, analyze, and plan their trajectories within complex environments. This typically involves the integration of data from LiDAR sensors and cameras, which necessitates high-precision and real-time registration. Current methods for registering LiDAR point clouds with images face significant challenges due to inherent modality differences and computational overhead. To address these issues, we propose EEPNet, an advanced network that leverages reflectance maps obtained from point cloud projections to enhance registration accuracy. The introduction of point cloud projections substantially mitigates cross-modality differences at the network input level, while the inclusion of reflectance data improves performance in scenarios with limited spatial information of point cloud within the camera's field of view. Furthermore, by employing edge pixels for feature matching and incorporating an efficient matching optimization layer, EEPNet markedly accelerates real-time registration tasks. Experimental validation demonstrates that EEPNet achieves superior accuracy and efficiency compared to state-of-the-art methods. Our contributions offer significant advancements in autonomous perception systems, paving the way for robust and efficient sensor fusion in real-world applications.
Towards Single-Lens Controllable Depth-of-Field Imaging via All-in-Focus Aberration Correction and Monocular Depth Estimation
Sep 15, 2024



Controllable Depth-of-Field (DoF) imaging commonly produces amazing visual effects based on heavy and expensive high-end lenses. However, confronted with the increasing demand for mobile scenarios, it is desirable to achieve a lightweight solution with Minimalist Optical Systems (MOS). This work centers around two major limitations of MOS, i.e., the severe optical aberrations and uncontrollable DoF, for achieving single-lens controllable DoF imaging via computational methods. A Depth-aware Controllable DoF Imaging (DCDI) framework is proposed equipped with All-in-Focus (AiF) aberration correction and monocular depth estimation, where the recovered image and corresponding depth map are utilized to produce imaging results under diverse DoFs of any high-end lens via patch-wise convolution. To address the depth-varying optical degradation, we introduce a Depth-aware Degradation-adaptive Training (DA2T) scheme. At the dataset level, a Depth-aware Aberration MOS (DAMOS) dataset is established based on the simulation of Point Spread Functions (PSFs) under different object distances. Additionally, we design two plug-and-play depth-aware mechanisms to embed depth information into the aberration image recovery for better tackling depth-aware degradation. Furthermore, we propose a storage-efficient Omni-Lens-Field model to represent the 4D PSF library of various lenses. With the predicted depth map, recovered image, and depth-aware PSF map inferred by Omni-Lens-Field, single-lens controllable DoF imaging is achieved. Comprehensive experimental results demonstrate that the proposed framework enhances the recovery performance, and attains impressive single-lens controllable DoF imaging results, providing a seminal baseline for this field. The source code and the established dataset will be publicly available at https://github.com/XiaolongQian/DCDI.