 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: Enhanced Generalizability for Local Visuomotor Policies via Perception Alignment
Jan 27, 2026Generalizing beyond the training domain in image-based behavior cloning remains challenging. Existing methods address individual axes of generalization, workspace shifts, viewpoint changes, and cross-embodiment transfer, yet they are typically developed in isolation and often rely on complex pipelines. We introduce PALM (Perception Alignment for Local Manipulation), which leverages the invariance of local action distributions between out-of-distribution (OOD) and demonstrated domains to address these OOD shifts concurrently, without additional input modalities, model changes, or data collection. PALM modularizes the manipulation policy into coarse global components and a local policy for fine-grained actions. We reduce the discrepancy between in-domain and OOD inputs at the local policy level by enforcing local visual focus and consistent proprioceptive representation, allowing the policy to retrieve invariant local actions under OOD conditions. Experiments show that PALM limits OOD performance drops to 8% in simulation and 24% in the real world, compared to 45% and 77% for baselines.
Thinking with Blueprints: Assisting Vision-Language Models in Spatial Reasoning via Structured Object Representation
Jan 05, 2026Spatial reasoning -- the ability to perceive and reason about relationships in space -- advances vision-language models (VLMs) from visual perception toward spatial semantic understanding. Existing approaches either revisit local image patches, improving fine-grained perception but weakening global spatial awareness, or mark isolated coordinates, which capture object locations but overlook their overall organization. In this work, we integrate the cognitive concept of an object-centric blueprint into VLMs to enhance spatial reasoning. Given an image and a question, the model first constructs a JSON-style blueprint that records the positions, sizes, and attributes of relevant objects, and then reasons over this structured representation to produce the final answer. To achieve this, we introduce three key techniques: (1) blueprint-embedded reasoning traces for supervised fine-tuning to elicit basic reasoning skills; (2) blueprint-aware rewards in reinforcement learning to encourage the blueprint to include an appropriate number of objects and to align final answers with this causal reasoning; and (3) anti-shortcut data augmentation that applies targeted perturbations to images and questions, discouraging reliance on superficial visual or linguistic cues. Experiments show that our method consistently outperforms existing VLMs and specialized spatial reasoning models.
CADMorph: Geometry-Driven Parametric CAD Editing via a Plan-Generate-Verify Loop
Dec 12, 2025A Computer-Aided Design (CAD) model encodes an object in two coupled forms: a parametric construction sequence and its resulting visible geometric shape. During iterative design, adjustments to the geometric shape inevitably require synchronized edits to the underlying parametric sequence, called geometry-driven parametric CAD editing. The task calls for 1) preserving the original sequence's structure, 2) ensuring each edit's semantic validity, and 3) maintaining high shape fidelity to the target shape, all under scarce editing data triplets. We present CADMorph, an iterative plan-generate-verify framework that orchestrates pretrained domain-specific foundation models during inference: a parameter-to-shape (P2S) latent diffusion model and a masked-parameter-prediction (MPP) model. In the planning stage, cross-attention maps from the P2S model pinpoint the segments that need modification and offer editing masks. The MPP model then infills these masks with semantically valid edits in the generation stage. During verification, the P2S model embeds each candidate sequence in shape-latent space, measures its distance to the target shape, and selects the closest one. The three stages leverage the inherent geometric consciousness and design knowledge in pretrained priors, and thus tackle structure preservation, semantic validity, and shape fidelity respectively. Besides, both P2S and MPP models are trained without triplet data, bypassing the data-scarcity bottleneck. CADMorph surpasses GPT-4o and specialized CAD baselines, and supports downstream applications such as iterative editing and reverse-engineering enhancement.
BioMedJImpact: A Comprehensive Dataset and LLM Pipeline for AI Engagement and Scientific Impact Analysis of Biomedical Journals
Nov 16, 2025Assessing journal impact is central to scholarly communication, yet existing open resources rarely capture how collaboration structures and artificial intelligence (AI) research jointly shape venue prestige in biomedicine. We present BioMedJImpact, a large-scale, biomedical-oriented dataset designed to advance journal-level analysis of scientific impact and AI engagement. Built from 1.74 million PubMed Central articles across 2,744 journals, BioMedJImpact integrates bibliometric indicators, collaboration features, and LLM-derived semantic indicators for AI engagement. Specifically, the AI engagement feature is extracted through a reproducible three-stage LLM pipeline that we propose. Using this dataset, we analyze how collaboration intensity and AI engagement jointly influence scientific impact across pre- and post-pandemic periods (2016-2019, 2020-2023). Two consistent trends emerge: journals with higher collaboration intensity, particularly those with larger and more diverse author teams, tend to achieve greater citation impact, and AI engagement has become an increasingly strong correlate of journal prestige, especially in quartile rankings. To further validate the three-stage LLM pipeline we proposed for deriving the AI engagement feature, we conduct human evaluation, confirming substantial agreement in AI relevance detection and consistent subfield classification. Together, these contributions demonstrate that BioMedJImpact serves as both a comprehensive dataset capturing the intersection of biomedicine and AI, and a validated methodological framework enabling scalable, content-aware scientometric analysis of scientific impact and innovation dynamics. Code is available at https://github.com/JonathanWry/BioMedJImpact.
Nondeterministic Polynomial-time Problem Challenge: An Ever-Scaling Reasoning Benchmark for LLMs
Apr 15, 2025Reasoning is the fundamental capability of large language models (LLMs). Due to the rapid progress of LLMs, there are two main issues of current benchmarks: i) these benchmarks can be crushed in a short time (less than 1 year), and ii) these benchmarks may be easily hacked. To handle these issues, we propose the ever-scalingness for building the benchmarks which are uncrushable, unhackable, auto-verifiable and general. This paper presents Nondeterministic Polynomial-time Problem Challenge (NPPC), an ever-scaling reasoning benchmark for LLMs. Specifically, the NPPC has three main modules: i) npgym, which provides a unified interface of 25 well-known NP-complete problems and can generate any number of instances with any levels of complexities, ii) npsolver: which provides a unified interface to evaluate the problem instances with both online and offline models via APIs and local deployments, respectively, and iii) npeval: which provides the comprehensive and ready-to-use tools to analyze the performances of LLMs over different problems, the number of tokens, the aha moments, the reasoning errors and the solution errors. Extensive experiments over widely-used LLMs demonstrate: i) NPPC can successfully decrease the performances of advanced LLMs' performances to below 10%, demonstrating that NPPC is uncrushable, ii) DeepSeek-R1, Claude-3.7-Sonnet, and o1/o3-mini are the most powerful LLMs, where DeepSeek-R1 outperforms Claude-3.7-Sonnet and o1/o3-mini in most NP-complete problems considered, and iii) the numbers of tokens, aha moments in the advanced LLMs, e.g., Claude-3.7-Sonnet and DeepSeek-R1, are observed first to increase and then decrease when the problem instances become more and more difficult. We believe that NPPC is the first ever-scaling reasoning benchmark, serving as the uncrushable and unhackable testbed for LLMs toward artificial general intelligence (AGI).
Can Visuo-motor Policies Benefit from Random Exploration Data? A Case Study on Stacking
Mar 30, 2025Human demonstrations have been key to recent advancements in robotic manipulation, but their scalability is hampered by the substantial cost of the required human labor. In this paper, we focus on random exploration data-video sequences and actions produced autonomously via motions to randomly sampled positions in the workspace-as an often overlooked resource for training visuo-motor policies in robotic manipulation. Within the scope of imitation learning, we examine random exploration data through two paradigms: (a) by investigating the use of random exploration video frames with three self-supervised learning objectives-reconstruction, contrastive, and distillation losses-and evaluating their applicability to visual pre-training; and (b) by analyzing random motor commands in the context of a staged learning framework to assess their effectiveness in autonomous data collection. Towards this goal, we present a large-scale experimental study based on over 750 hours of robot data collection, comprising 400 successful and 12,000 failed episodes. Our results indicate that: (a) among the three self-supervised learning objectives, contrastive loss appears most effective for visual pre-training while leveraging random exploration video frames; (b) data collected with random motor commands may play a crucial role in balancing the training data distribution and improving success rates in autonomous data collection within this study. The source code and dataset will be made publicly available at https://cloudgripper.org.
Lifelong Learning with Task-Specific Adaptation: Addressing the Stability-Plasticity Dilemma
Mar 08, 2025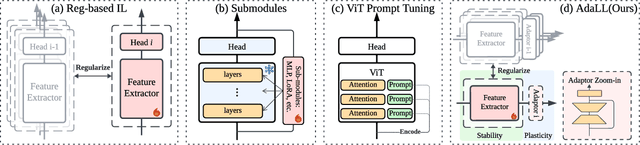
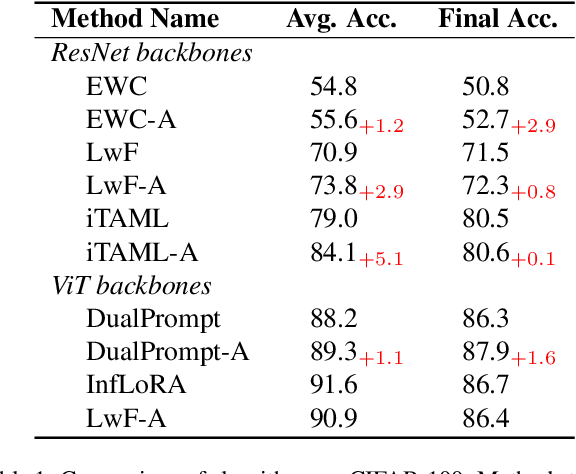
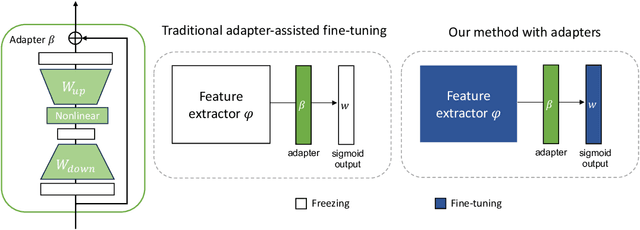

Lifelong learning (LL) aims to continuously acquire new knowledge while retaining previously learned knowledge. A central challenge in LL is the stability-plasticity dilemma, which requires models to balance the preservation of previous knowledge (stability) with the ability to learn new tasks (plasticity). While parameter-efficient fine-tuning (PEFT) has been widely adopted in large language models, its application to lifelong learning remains underexplored. To bridge this gap, this paper proposes AdaLL, an adapter-based framework designed to address the dilemma through a simple, universal, and effective strategy. AdaLL co-trains the backbone network and adapters under regularization constraints, enabling the backbone to capture task-invariant features while allowing the adapters to specialize in task-specific information. Unlike methods that freeze the backbone network, AdaLL incrementally enhances the backbone's capabilities across tasks while minimizing interference through backbone regularization. This architectural design significantly improves both stability and plasticity, effectively eliminating the stability-plasticity dilemma. Extensive experiments demonstrate that AdaLL consistently outperforms existing methods across various configurations, including dataset choices, task sequences, and task scales.
Text-to-CAD Generation Through Infusing Visual Feedback in Large Language Models
Jan 31, 2025



Creating Computer-Aided Design (CAD) models requires significant expertise and effort. Text-to-CAD, which converts textual descriptions into CAD parametric sequences, is crucial in streamlining this process. Recent studies have utilized ground-truth parametric sequences, known as sequential signals, as supervision to achieve this goal. However, CAD models are inherently multimodal, comprising parametric sequences and corresponding rendered visual objects. Besides,the rendering process from parametric sequences to visual objects is many-to-one. Therefore, both sequential and visual signals are critical for effective training. In this work, we introduce CADFusion, a framework that uses Large Language Models (LLMs) as the backbone and alternates between two training stages: the sequential learning (SL) stage and the visual feedback (VF) stage. In the SL stage, we train LLMs using ground-truth parametric sequences, enabling the generation of logically coherent parametric sequences. In the VF stage, we reward parametric sequences that render into visually preferred objects and penalize those that do not, allowing LLMs to learn how rendered visual objects are perceived and evaluated. These two stages alternate throughout the training, ensuring balanced learning and preserving benefits of both signals. Experiments demonstrate that CADFusion significantly improves performance, both qualitatively and quantitatively.
PACA: Perspective-Aware Cross-Attention Representation for Zero-Shot Scene Rearrangement
Oct 29, 2024



Scene rearrangement, like table tidying, is a challenging task in robotic manipulation due to the complexity of predicting diverse object arrangements. Web-scale trained generative models such as Stable Diffusion can aid by generating natural scenes as goals. To facilitate robot execution, object-level representations must be extracted to match the real scenes with the generated goals and to calculate object pose transformations. Current methods typically use a multi-step design that involves separate models for generation, segmentation, and feature encoding, which can lead to a low success rate due to error accumulation. Furthermore, they lack control over the viewing perspectives of the generated goals, restricting the tasks to 3-DoF settings. In this paper, we propose PACA, a zero-shot pipeline for scene rearrangement that leverages perspective-aware cross-attention representation derived from Stable Diffusion. Specifically, we develop a representation that integrates generation, segmentation, and feature encoding into a single step to produce object-level representations. Additionally, we introduce perspective control, thus enabling the matching of 6-DoF camera views and extending past approaches that were limited to 3-DoF top-down views. The efficacy of our method is demonstrated through its zero-shot performance in real robot experiments across various scenes, achieving an average matching accuracy and execution success rate of 87% and 67%, respectively.
Double Oracle Neural Architecture Search for Game Theoretic Deep Learning Models
Oct 07, 2024



In this paper, we propose a new approach to train deep learning models using game theory concepts including Generative Adversarial Networks (GANs) and Adversarial Training (AT) where we deploy a double-oracle framework using best response oracles. GAN is essentially a two-player zero-sum game between the generator and the discriminator. The same concept can be applied to AT with attacker and classifier as players. Training these models is challenging as a pure Nash equilibrium may not exist and even finding the mixed Nash equilibrium is difficult as training algorithms for both GAN and AT have a large-scale strategy space. Extending our preliminary model DO-GAN, we propose the methods to apply the double oracle framework concept to Adversarial Neural Architecture Search (NAS for GAN) and Adversarial Training (NAS for AT) algorithms. We first generalize the players' strategies as the trained models of generator and discriminator from the best response oracles. We then compute the meta-strategies using a linear program. For scalability of the framework where multiple network models of best responses are stored in the memory, we prune the weakly-dominated players' strategies to keep the oracles from becoming intractable. Finally, we conduct experiments on MNIST, CIFAR-10 and TinyImageNet for DONAS-GAN. We also evaluate the robustness under FGSM and PGD attacks on CIFAR-10, SVHN and TinyImageNet for DONAS-AT. We show that all our variants have significant improvements in both subjective qualitative evaluation and quantitative metrics, compared with their respective base architectures.