 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Model Understand Word Semantics as A Chatbot? An Empirical Study of Language Model Internal External Mismatch
Sep 21, 2024

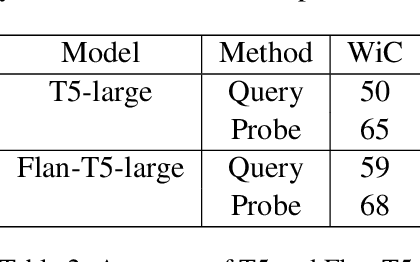

Current common interactions with language models is through full inference. This approach may not necessarily align with the model's internal knowledge. Studies show discrepancies between prompts and internal representations. Most focus on sentence understanding. We study the discrepancy of word semantics understanding in internal and external mismatch across Encoder-only, Decoder-only, and Encoder-Decoder pre-trained language models.
Bias and Toxicity in Role-Play Reasoning
Sep 21, 2024



Role-play in the Large Language Model (LLM) is a crucial technique that enables models to adopt specific perspectives, enhancing their ability to generate contextually relevant and accurate responses. By simulating different roles, theis approach improves reasoning capabilities across various NLP benchmarks, making the model's output more aligned with diverse scenarios. However, in this work, we demonstrate that role-play also carries potential risks. We systematically evaluate the impact of role-play by asking the language model to adopt different roles and testing it on multiple benchmarks that contain stereotypical and harmful questions. Despite the significant fluctuations in the benchmark results in different experiments, we find that applying role-play often increases the overall likelihood of generating stereotypical and harmful outputs.
Gender Bias in Large Language Models across Multiple Languages
Mar 01, 2024



With the growing deployment of large language models (LLMs) across various applications, assessing the influence of gender biases embedded in LLMs becomes crucial. The topic of gender bias within the realm of natural language processing (NLP) has gained considerable focus, particularly in the context of English. Nonetheless, the investigation of gender bias in languages other than English is still relatively under-explored and insufficiently analyzed. In this work, We examine gender bias in LLMs-generated outputs for different languages. We use three measurements: 1) gender bias in selecting descriptive words given the gender-related context. 2) gender bias in selecting gender-related pronouns (she/he) given the descriptive words. 3) gender bias in the topics of LLM-generated dialogues. We investigate the outputs of the GPT series of LLMs in various languages using our three measurement methods. Our findings revealed significant gender biases across all the languages we examined.