 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Wild: Pareto-Optimal Visual Decision-Making in Image Space
Nov 11, 2025Navigating complex real-world environments requires semantic understanding and adaptive decision-making. Traditional reactive methods without maps often fail in cluttered settings, map-based approaches demand heavy mapping effort, and learning-based solutions rely on large datasets with limited generalization. To address these challenges, we present Pareto-Optimal Visual Navigation, a lightweight image-space framework that combines data-driven semantics, Pareto-optimal decision-making, and visual servoing for real-time navigation.
LSPO: Length-aware Dynamic Sampling for Policy Optimization in LLM Reasoning
Oct 01, 2025Since the release of Deepseek-R1, reinforcement learning with verifiable rewards (RLVR) has become a central approach for training large language models (LLMs) on reasoning tasks. Recent work has largely focused on modifying loss functions to make RLVR more efficient and effective. In this paper, motivated by studies of overthinking in LLMs, we propose Length-aware Sampling for Policy Optimization (LSPO), a novel meta-RLVR algorithm that dynamically selects training data at each step based on the average response length. We evaluate LSPO across multiple base models and datasets, demonstrating that it consistently improves learning effectiveness. In addition, we conduct a detailed ablation study to examine alternative ways of incorporating length signals into dynamic sampling, offering further insights and highlighting promising directions for future research.
Iterative Deepening Sampling for Large Language Models
Feb 08, 2025
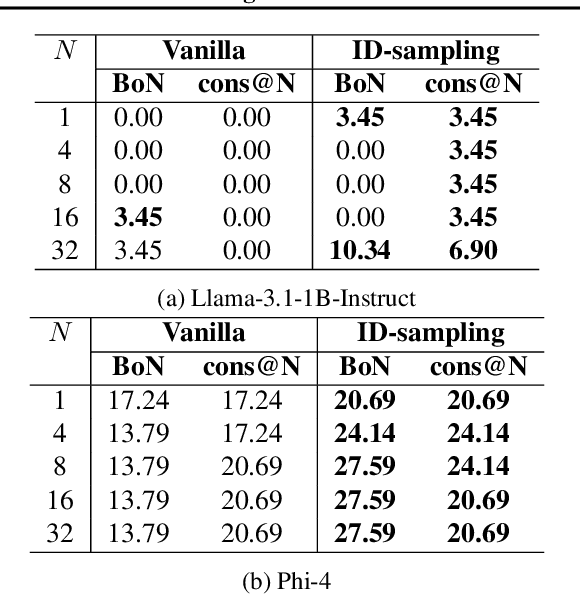
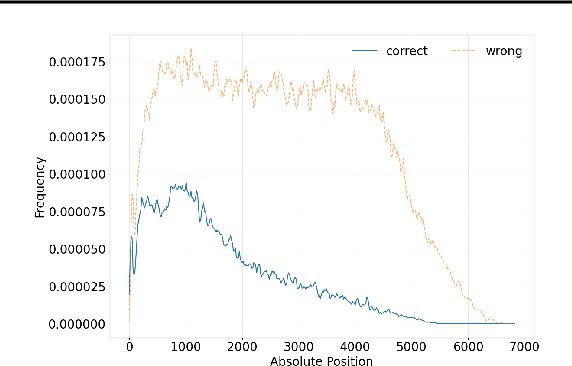
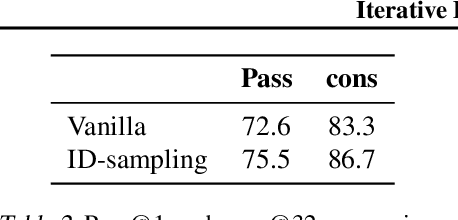
The recent release of OpenAI's o1 models and other similar frameworks showcasing test-time scaling laws has demonstrated their exceptional capability to tackle complex reasoning tasks. Inspired by this, subsequent research has revealed that such test-time scaling laws hinge on the model's ability to search both within a single response (intra-response) and across multiple responses (inter-response) during training. Crucially, beyond selecting a single optimal response, the model must also develop robust self-correction capabilities within its own outputs. However, training models to achieve effective self-evaluation and self-correction remains a significant challenge, heavily dependent on the quality of self-reflection data. In this paper, we address this challenge by focusing on enhancing the quality of self-reflection data generation for complex problem-solving, which can subsequently improve the training of next-generation large language models (LLMs). Specifically, we explore how manually triggering a model's self-correction mechanisms can improve performance on challenging reasoning tasks. To this end, we propose a novel iterative deepening sampling algorithm framework designed to enhance self-correction and generate higher-quality samples. Through extensive experiments on Math500 and AIME benchmarks, we demonstrate that our method achieves a higher success rate on difficult tasks and provide detailed ablation studies to analyze its effectiveness across diverse settings.
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
Oct 28, 2024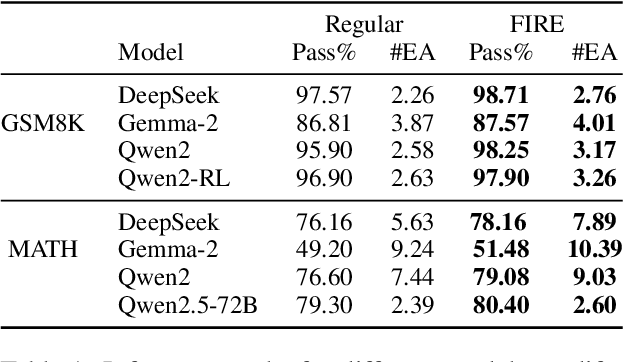


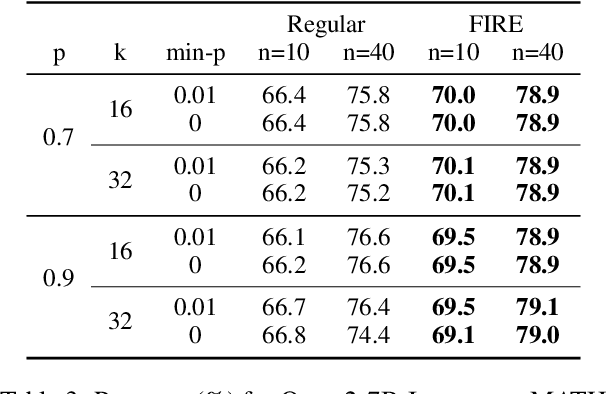
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
Can Language Model Understand Word Semantics as A Chatbot? An Empirical Study of Language Model Internal External Mismatch
Sep 21, 2024

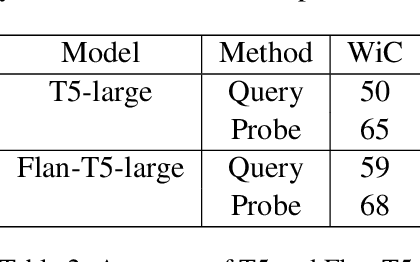

Current common interactions with language models is through full inference. This approach may not necessarily align with the model's internal knowledge. Studies show discrepancies between prompts and internal representations. Most focus on sentence understanding. We study the discrepancy of word semantics understanding in internal and external mismatch across Encoder-only, Decoder-only, and Encoder-Decoder pre-trained language models.
RePrompt: Planning by Automatic Prompt Engineering for Large Language Models Agents
Jun 17, 2024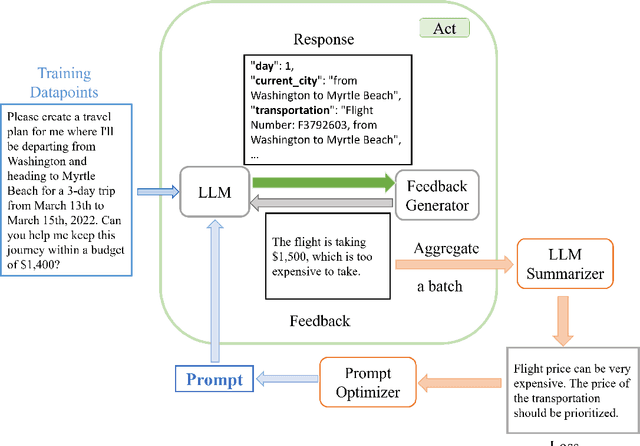

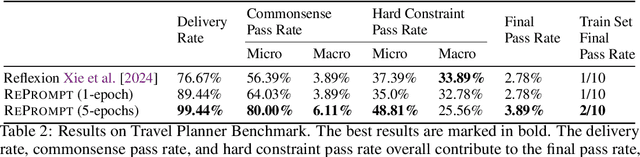

In this past year, large language models (LLMs) have had remarkable success in domains outside the traditional natural language processing, and people are starting to explore the usage of LLMs in more general and close to application domains like code generation, travel planning, and robot controls. Connecting these LLMs with great capacity and external tools, people are building the so-called LLM agents, which are supposed to help people do all kinds of work in everyday life. In all these domains, the prompt to the LLMs has been shown to make a big difference in what the LLM would generate and thus affect the performance of the LLM agents. Therefore, automatic prompt engineering has become an important question for many researchers and users of LLMs. In this paper, we propose a novel method, \textsc{RePrompt}, which does "gradient descent" to optimize the step-by-step instructions in the prompt of the LLM agents based on the chat history obtained from interactions with LLM agents. By optimizing the prompt, the LLM will learn how to plan in specific domains. We have used experiments in PDDL generation and travel planning to show that our method could generally improve the performance for different reasoning tasks when using the updated prompt as the initial prompt.
POAM: Probabilistic Online Attentive Mapping for Efficient Robotic Information Gathering
Jun 06, 2024



Gaussian Process (GP) models are widely used for Robotic Information Gathering (RIG) in exploring unknown environments due to their ability to model complex phenomena with non-parametric flexibility and accurately quantify prediction uncertainty. Previous work has developed informative planners and adaptive GP models to enhance the data efficiency of RIG by improving the robot's sampling strategy to focus on informative regions in non-stationary environments. However, computational efficiency becomes a bottleneck when using GP models in large-scale environments with limited computational resources. We propose a framework -- Probabilistic Online Attentive Mapping (POAM) -- that leverages the modeling strengths of the non-stationary Attentive Kernel while achieving constant-time computational complexity for online decision-making. POAM guides the optimization process via variational Expectation Maximization, providing constant-time update rules for inducing inputs, variational parameters, and hyperparameters. Extensive experiments in active bathymetric mapping tasks demonstrate that POAM significantly improves computational efficiency, model accuracy, and uncertainty quantification capability compared to existing online sparse GP models.
MARL-LNS: Cooperative Multi-agent Reinforcement Learning via Large Neighborhoods Search
Apr 03, 2024



Cooperative multi-agent reinforcement learning (MARL) has been an increasingly important research topic in the last half-decade because of its great potential for real-world applications. Because of the curse of dimensionality, the popular "centralized training decentralized execution" framework requires a long time in training, yet still cannot converge efficiently. In this paper, we propose a general training framework, MARL-LNS, to algorithmically address these issues by training on alternating subsets of agents using existing deep MARL algorithms as low-level trainers, while not involving any additional parameters to be trained. Based on this framework, we provide three algorithm variants based on the framework: random large neighborhood search (RLNS), batch large neighborhood search (BLNS), and adaptive large neighborhood search (ALNS), which alternate the subsets of agents differently. We test our algorithms on both the StarCraft Multi-Agent Challenge and Google Research Football, showing that our algorithms can automatically reduce at least 10% of training time while reaching the same final skill level as the original algorithm.
Why Solving Multi-agent Path Finding with Large Language Model has not Succeeded Yet
Jan 08, 2024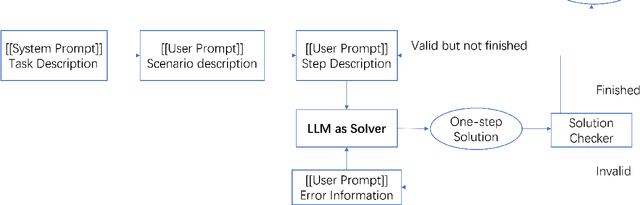
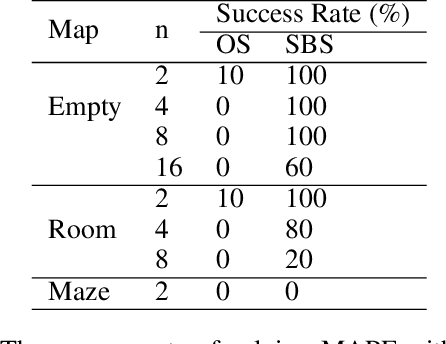
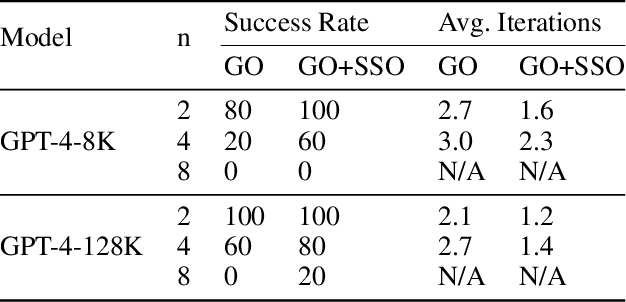

With the explosive influence caused by the success of large language models (LLM) like ChatGPT and GPT-4, there has been an extensive amount of recent work showing that foundation models can be used to solve a large variety of tasks. However, there is very limited work that shares insights on multi-agent planning. Multi-agent planning is different from other domains by combining the difficulty of multi-agent coordination and planning, and making it hard to leverage external tools to facilitate the reasoning needed. In this paper, we focus on the problem of multi-agent path finding (MAPF), which is also known as multi-robot route planning, and study how to solve MAPF with LLMs. We first show the motivating success on an empty room map without obstacles, then the failure to plan on a slightly harder room map. We present our hypothesis of why directly solving MAPF with LLMs has not been successful yet, and we use various experiments to support our hypothesis.
Multi-Objective and Model-Predictive Tree Search for Spatiotemporal Informative Planning
Jun 16, 2023Adaptive sampling and planning in robotic environmental monitoring are challenging when the target environmental process varies over space and time. The underlying environmental dynamics require the planning module to integrate future environmental changes so that action decisions made earlier do not quickly become outdated. We propose a Monte Carlo tree search method which not only well balances the environment exploration and exploitation in space, but also catches up to the temporal environmental dynamics. This is achieved by incorporating multi-objective optimization and a look-ahead model-predictive rewarding mechanism. We show that by allowing the robot to leverage the simulated and predicted spatiotemporal environmental process, the proposed informative planning approach achieves a superior performance after comparing with other baseline methods in terms of the root mean square error of the environment model and the distance to the ground truth.