 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Dice: Disentangling Knowledge Updates via Geometric Consensus for Agent Continual Learning
Jan 08, 2026Large Language Model (LLM)-based agents significantly extend the utility of LLMs by interacting with dynamic environments. However, enabling agents to continually learn new tasks without catastrophic forgetting remains a critical challenge, known as the stability-plasticity dilemma. In this work, we argue that this dilemma fundamentally arises from the failure to explicitly distinguish between common knowledge shared across tasks and conflicting knowledge introduced by task-specific interference. To address this, we propose Agent-Dice, a parameter fusion framework based on directional consensus evaluation. Concretely, Agent-Dice disentangles knowledge updates through a two-stage process: geometric consensus filtering to prune conflicting gradients, and curvature-based importance weighting to amplify shared semantics. We provide a rigorous theoretical analysis that establishes the validity of the proposed fusion scheme and offers insight into the origins of the stability-plasticity dilemma. Extensive experiments on GUI agents and tool-use agent domains demonstrate that Agent-Dice exhibits outstanding continual learning performance with minimal computational overhead and parameter updates. The codes are available at https://github.com/Wuzheng02/Agent-Dice.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
From Black Box to Insight: Explainable AI for Extreme Event Preparedness
Nov 17, 2025



As climate change accelerates the frequency and severity of extreme events such as wildfires, the need for accurate, explainable, and actionable forecasting becomes increasingly urgent. While artificial intelligence (AI) models have shown promise in predicting such events, their adoption in real-world decision-making remains limited due to their black-box nature, which limits trust, explainability, and operational readiness. This paper investigates the role of explainable AI (XAI) in bridging the gap between predictive accuracy and actionable insight for extreme event forecasting. Using wildfire prediction as a case study, we evaluate various AI models and employ SHapley Additive exPlanations (SHAP) to uncover key features, decision pathways, and potential biases in model behavior. Our analysis demonstrates how XAI not only clarifies model reasoning but also supports critical decision-making by domain experts and response teams. In addition, we provide supporting visualizations that enhance the interpretability of XAI outputs by contextualizing feature importance and temporal patterns in seasonality and geospatial characteristics. This approach enhances the usability of AI explanations for practitioners and policymakers. Our findings highlight the need for AI systems that are not only accurate but also interpretable, accessible, and trustworthy, essential for effective use in disaster preparedness, risk mitigation, and climate resilience planning.
ColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
Say One Thing, Do Another? Diagnosing Reasoning-Execution Gaps in VLM-Powered Mobile-Use Agents
Oct 02, 2025Mobile-use agents powered by vision-language models (VLMs) have shown great potential in interpreting natural language instructions and generating corresponding actions based on mobile graphical user interface. Recent studies suggest that incorporating chain-of-thought (CoT) reasoning tends to improve the execution accuracy. However, existing evaluations emphasize execution accuracy while neglecting whether CoT reasoning aligns with ground-truth actions. This oversight fails to assess potential reasoning-execution gaps, which in turn foster over-trust: users relying on seemingly plausible CoTs may unknowingly authorize harmful actions, potentially resulting in financial loss or trust crisis. In this work, we introduce a new evaluation framework to diagnose reasoning-execution gaps. At its core lies Ground-Truth Alignment (GTA), which measures whether the action implied by a CoT matches the ground-truth action. By combining GTA with the standard Exact Match (EM) metric, we jointly assess both the reasoning accuracy and execution accuracy. This joint perspective reveals two types of reasoning-execution gaps: (i) Execution Gap (EG), where the reasoning correctly identifies the correct action but execution fails, and (ii) Reasoning Gap (RG), where execution succeeds but reasoning process conflicts with the actual execution. Experimental results across a wide range of mobile interaction tasks reveal that reasoning-execution gaps are prevalent, with execution gaps occurring more frequently than reasoning gaps. Moreover, while scaling up model size reduces the overall gap, sizable execution gaps persist even in the largest models. Further analysis shows that our framework reliably reflects systematic EG/RG patterns in state-of-the-art models. These findings offer concrete diagnostics and support the development of more trustworthy mobile-use agents.
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Sep 09, 2025With the rapid progress of multimodal large language models, operating system (OS) agents become increasingly capable of automating tasks through on-device graphical user interfaces (GUIs). However, most existing OS agents are designed for idealized settings, whereas real-world environments often present untrustworthy conditions. To mitigate risks of over-execution in such scenarios, we propose a query-driven human-agent-GUI interaction framework that enables OS agents to decide when to query humans for more reliable task completion. Built upon this framework, we introduce VeriOS-Agent, a trustworthy OS agent trained with a two-stage learning paradigm that falicitate the decoupling and utilization of meta-knowledge. Concretely, VeriOS-Agent autonomously executes actions in normal conditions while proactively querying humans in untrustworthy scenarios. Experiments show that VeriOS-Agent improves the average step-wise success rate by 20.64\% in untrustworthy scenarios over the state-of-the-art, without compromising normal performance. Analysis highlights VeriOS-Agent's rationality, generalizability, and scalability. The codes, datasets and models are available at https://github.com/Wuzheng02/VeriOS.
Quick on the Uptake: Eliciting Implicit Intents from Human Demonstrations for Personalized Mobile-Use Agents
Aug 12, 2025


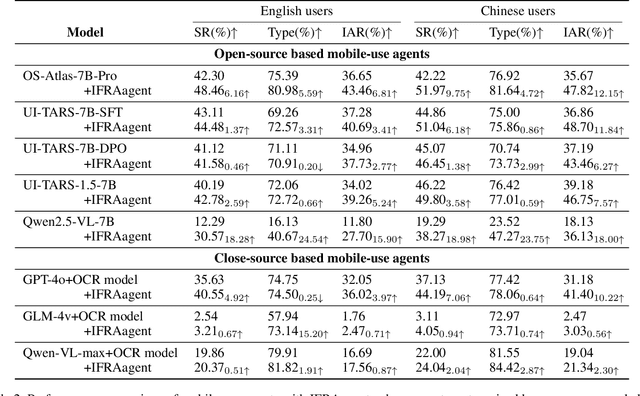
As multimodal large language models advance rapidly, the automation of mobile tasks has become increasingly feasible through the use of mobile-use agents that mimic human interactions from graphical user interface. To further enhance mobile-use agents, previous studies employ demonstration learning to improve mobile-use agents from human demonstrations. However, these methods focus solely on the explicit intention flows of humans (e.g., step sequences) while neglecting implicit intention flows (e.g., personal preferences), which makes it difficult to construct personalized mobile-use agents. In this work, to evaluate the \textbf{I}ntention \textbf{A}lignment \textbf{R}ate between mobile-use agents and humans, we first collect \textbf{MobileIAR}, a dataset containing human-intent-aligned actions and ground-truth actions. This enables a comprehensive assessment of the agents' understanding of human intent. Then we propose \textbf{IFRAgent}, a framework built upon \textbf{I}ntention \textbf{F}low \textbf{R}ecognition from human demonstrations. IFRAgent analyzes explicit intention flows from human demonstrations to construct a query-level vector library of standard operating procedures (SOP), and analyzes implicit intention flows to build a user-level habit repository. IFRAgent then leverages a SOP extractor combined with retrieval-augmented generation and a query rewriter to generate personalized query and SOP from a raw ambiguous query, enhancing the alignment between mobile-use agents and human intent. Experimental results demonstrate that IFRAgent outperforms baselines by an average of 6.79\% (32.06\% relative improvement) in human intention alignment rate and improves step completion rates by an average of 5.30\% (26.34\% relative improvement). The codes are available at https://github.com/MadeAgents/Quick-on-the-Uptake.
Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
Jun 10, 2025Autonomous agents powered by multimodal large language models have been developed to facilitate task execution on mobile devices. However, prior work has predominantly focused on atomic tasks -- such as shot-chain execution tasks and single-screen grounding tasks -- while overlooking the generalization to compositional tasks, which are indispensable for real-world applications. This work introduces UI-NEXUS, a comprehensive benchmark designed to evaluate mobile agents on three categories of compositional operations: Simple Concatenation, Context Transition, and Deep Dive. UI-NEXUS supports interactive evaluation in 20 fully controllable local utility app environments, as well as 30 online Chinese and English service apps. It comprises 100 interactive task templates with an average optimal step count of 14.05. Experimental results across a range of mobile agents with agentic workflow or agent-as-a-model show that UI-NEXUS presents significant challenges. Specifically, existing agents generally struggle to balance performance and efficiency, exhibiting representative failure modes such as under-execution, over-execution, and attention drift, causing visible atomic-to-compositional generalization gap. Inspired by these findings, we propose AGENT-NEXUS, a lightweight and efficient scheduling system to tackle compositional mobile tasks. AGENT-NEXUS extrapolates the abilities of existing mobile agents by dynamically decomposing long-horizon tasks to a series of self-contained atomic subtasks. AGENT-NEXUS achieves 24% to 40% task success rate improvement for existing mobile agents on compositional operation tasks within the UI-NEXUS benchmark without significantly sacrificing inference overhead. The demo video, dataset, and code are available on the project page at https://ui-nexus.github.io.
Hidden Ghost Hand: Unveiling Backdoor Vulnerabilities in MLLM-Powered Mobile GUI Agents
May 20, 2025Graphical user interface (GUI) agents powered by multimodal large language models (MLLMs) have shown greater promise for human-interaction. However, due to the high fine-tuning cost, users often rely on open-source GUI agents or APIs offered by AI providers, which introduces a critical but underexplored supply chain threat: backdoor attacks. In this work, we first unveil that MLLM-powered GUI agents naturally expose multiple interaction-level triggers, such as historical steps, environment states, and task progress. Based on this observation, we introduce AgentGhost, an effective and stealthy framework for red-teaming backdoor attacks. Specifically, we first construct composite triggers by combining goal and interaction levels, allowing GUI agents to unintentionally activate backdoors while ensuring task utility. Then, we formulate backdoor injection as a Min-Max optimization problem that uses supervised contrastive learning to maximize the feature difference across sample classes at the representation space, improving flexibility of the backdoor. Meanwhile, it adopts supervised fine-tuning to minimize the discrepancy between backdoor and clean behavior generation, enhancing effectiveness and utility. Extensive evaluations of various agent models in two established mobile benchmarks show that AgentGhost is effective and generic, with attack accuracy that reaches 99.7\% on three attack objectives, and shows stealthiness with only 1\% utility degradation. Furthermore, we tailor a defense method against AgentGhost that reduces the attack accuracy to 22.1\%. Our code is available at \texttt{anonymous}.
GEM: Gaussian Embedding Modeling for Out-of-Distribution Detection in GUI Agents
May 19, 2025Graphical user interface (GUI) agents have recently emerged as an intriguing paradigm for human-computer interaction, capable of automatically executing user instructions to operate intelligent terminal devices. However, when encountering out-of-distribution (OOD) instructions that violate environmental constraints or exceed the current capabilities of agents, GUI agents may suffer task breakdowns or even pose security threats. Therefore, effective OOD detection for GUI agents is essential. Traditional OOD detection methods perform suboptimally in this domain due to the complex embedding space and evolving GUI environments. In this work, we observe that the in-distribution input semantic space of GUI agents exhibits a clustering pattern with respect to the distance from the centroid. Based on the finding, we propose GEM, a novel method based on fitting a Gaussian mixture model over input embedding distances extracted from the GUI Agent that reflect its capability boundary. Evaluated on eight datasets spanning smartphones, computers, and web browsers, our method achieves an average accuracy improvement of 23.70\% over the best-performing baseline. Analysis verifies the generalization ability of our method through experiments on nine different backbones. The codes are available at https://github.com/Wuzheng02/GEM-OODforGUIagents.