 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning RNAs with Language Models
Feb 12, 2026RNA design, the task of finding a sequence that folds into a target secondary structure, has broad biological and biomedical impact but remains computationally challenging due to the exponentially large sequence space and exponentially many competing folds. Traditional approaches treat it as an optimization problem, relying on per-instance heuristics or constraint-based search. We instead reframe RNA design as conditional sequence generation and introduce a reusable neural approximator, instantiated as an autoregressive language model (LM), that maps target structures directly to sequences. We first train our model in a supervised setting on random-induced structure-sequence pairs, and then use reinforcement learning (RL) to optimize end-to-end metrics. We also propose methods to select a small subset for RL that greatly improves RL efficiency and quality. Across four datasets, our approach outperforms state-of-the-art systems on key metrics such as Boltzmann probability while being 1.7x faster, establishing conditional LM generation as a scalable, task-agnostic alternative to per-instance optimization for RNA design. Our code and data are available at https://github.com/KuNyaa/RNA-Design-LM.
Sampling-based Continuous Optimization with Coupled Variables for RNA Design
Dec 11, 2024The task of RNA design given a target structure aims to find a sequence that can fold into that structure. It is a computationally hard problem where some version(s) have been proven to be NP-hard. As a result, heuristic methods such as local search have been popular for this task, but by only exploring a fixed number of candidates. They can not keep up with the exponential growth of the design space, and often perform poorly on longer and harder-to-design structures. We instead formulate these discrete problems as continuous optimization, which starts with a distribution over all possible candidate sequences, and uses gradient descent to improve the expectation of an objective function. We define novel distributions based on coupled variables to rule out invalid sequences given the target structure and to model the correlation between nucleotides. To make it universally applicable to any objective function, we use sampling to approximate the expected objective function, to estimate the gradient, and to select the final candidate. Compared to the state-of-the-art methods, our work consistently outperforms them in key metrics such as Boltzmann probability, ensemble defect, and energy gap, especially on long and hard-to-design puzzles in the Eterna100 benchmark. Our code is available at: http://github.com/weiyutang1010/ncrna_design.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024
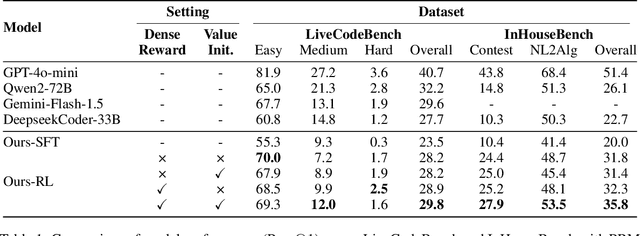

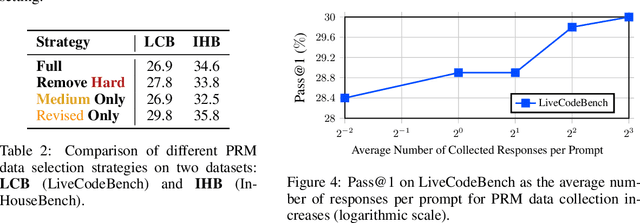
Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
Messenger and Non-Coding RNA Design via Expected Partition Function and Continuous Optimization
Dec 29, 2023



The tasks of designing messenger RNAs and non-coding RNAs are discrete optimization problems, and several versions of these problems are NP-hard. As an alternative to commonly used local search methods, we formulate these problems as continuous optimization and develop a general framework for this optimization based on a new concept of "expected partition function". The basic idea is to start with a distribution over all possible candidate sequences, and extend the objective function from a sequence to a distribution. We then use gradient descent-based optimization methods to improve the extended objective function, and the distribution will gradually shrink towards a one-hot sequence (i.e., a single sequence). We consider two important case studies within this framework, the mRNA design problem optimizing for partition function (i.e., ensemble free energy) and the non-coding RNA design problem optimizing for conditional (i.e., Boltzmann) probability. In both cases, our approach demonstrate promising preliminary results. We make our code available at https://github.com/KuNyaa/RNA_Design_codebase.
Pre-trained Models for Natural Language Processing: A Survey
Apr 24, 2020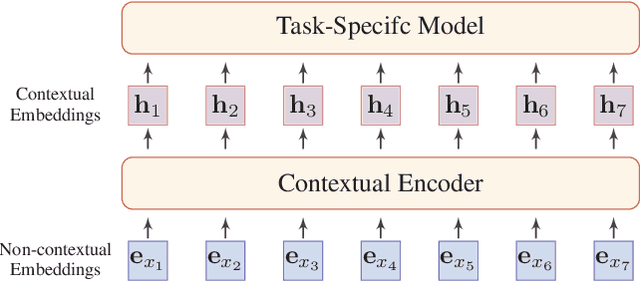
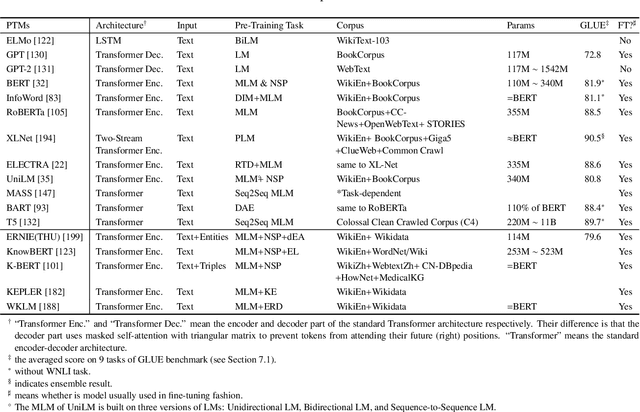

Recently, the emergence of pre-trained models (PTMs) has brought natural language processing (NLP) to a new era. In this survey, we provide a comprehensive review of PTMs for NLP. We first briefly introduce language representation learning and its research progress. Then we systematically categorize existing PTMs based on a taxonomy with four perspectives. Next, we describe how to adapt the knowledge of PTMs to the downstream tasks. Finally, we outline some potential directions of PTMs for future research. This survey is purposed to be a hands-on guide for understanding, using, and developing PTMs for various NLP tasks.
Style Transformer: Unpaired Text Style Transfer without Disentangled Latent Representation
May 14, 2019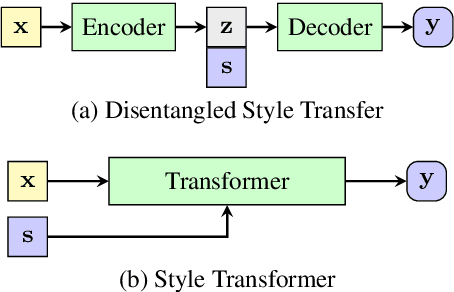
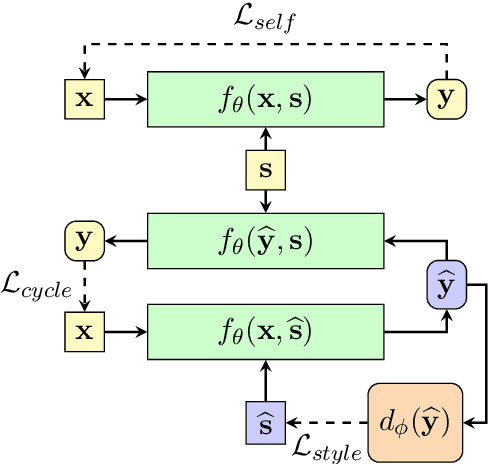
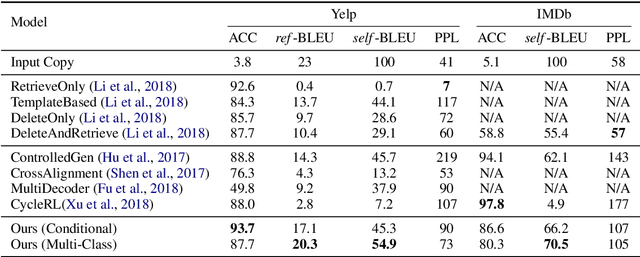
Disentangling the content and style in the latent space is prevalent in unpaired text style transfer. However, two major issues exist in most of the current neural models. 1) It is difficult to completely strip the style information from the semantics for a sentence. 2) The recurrent neural network (RNN) based encoder and decoder, mediated by the latent representation, cannot well deal with the issue of the long-term dependency, resulting in poor preservation of non-stylistic semantic content.In this paper, we propose the Style Transformer, which makes no assumption about the latent representation of source sentence and equips the power of attention mechanism in Transformer to achieve better style transfer and better content preservation.