 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
OS-Themis: A Scalable Critic Framework for Generalist GUI Rewards
Mar 19, 2026Reinforcement Learning (RL) has the potential to improve the robustness of GUI agents in stochastic environments, yet training is highly sensitive to the quality of the reward function. Existing reward approaches struggle to achieve both scalability and performance. To address this, we propose OS-Themis, a scalable and accurate multi-agent critic framework. Unlike a single judge, OS-Themis decomposes trajectories into verifiable milestones to isolate critical evidence for decision making and employs a review mechanism to strictly audit the evidence chain before making the final verdict. To facilitate evaluation, we further introduce OmniGUIRewardBench (OGRBench), a holistic cross-platform benchmark for GUI outcome rewards, where all evaluated models achieve their best performance under OS-Themis. Extensive experiments on AndroidWorld show that OS-Themis yields a 10.3% improvement when used to support online RL training, and a 6.9% gain when used for trajectory validation and filtering in the self-training loop, highlighting its potential to drive agent evolution.
Visual-ERM: Reward Modeling for Visual Equivalence
Mar 13, 2026Vision-to-code tasks require models to reconstruct structured visual inputs, such as charts, tables, and SVGs, into executable or structured representations with high visual fidelity. While recent Large Vision Language Models (LVLMs) achieve strong results via supervised fine-tuning, reinforcement learning remains challenging due to misaligned reward signals. Existing rewards either rely on textual rules or coarse visual embedding similarity, both of which fail to capture fine-grained visual discrepancies and are vulnerable to reward hacking. We propose Visual Equivalence Reward Model (Visual-ERM), a multimodal generative reward model that provides fine-grained, interpretable, and task-agnostic feedback to evaluate vision-to-code quality directly in the rendered visual space. Integrated into RL, Visual-ERM improves Qwen3-VL-8B-Instruct by +8.4 on chart-to-code and yields consistent gains on table and SVG parsing (+2.7, +4.1 on average), and further strengthens test-time scaling via reflection and revision. We also introduce VisualCritic-RewardBench (VC-RewardBench), a benchmark for judging fine-grained image-to-image discrepancies on structured visual data, where Visual-ERM at 8B decisively outperforms Qwen3-VL-235B-Instruct and approaches leading closed-source models. Our results suggest that fine-grained visual reward supervision is both necessary and sufficient for vision-to-code RL, regardless of task specificity.
CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
Sep 26, 2025Image captioning is a fundamental task that bridges the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable data annotated by humans or proprietary models. This approach often leads to models that memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome the limitation of SFT, we propose applying the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm to the open-ended task of image captioning. A primary challenge, however, is designing an objective reward function for the inherently subjective nature of what constitutes a "good" caption. We introduce Captioning Reinforcement Learning (CapRL), a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image. CapRL employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. As the first study to apply RLVR to the subjective image captioning task, we demonstrate that CapRL significantly enhances multiple settings. Pretraining on the CapRL-5M caption dataset annotated by CapRL-3B results in substantial gains across 12 benchmarks. Moreover, within the Prism Framework for caption quality evaluation, CapRL achieves performance comparable to Qwen2.5-VL-72B, while exceeding the baseline by an average margin of 8.4%. Code is available here: https://github.com/InternLM/CapRL.
CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning
Aug 27, 2025Autonomous agents for Graphical User Interfaces (GUIs) face significant challenges in specialized domains such as scientific computing, where both long-horizon planning and precise execution are required. Existing approaches suffer from a trade-off: generalist agents excel at planning but perform poorly in execution, while specialized agents demonstrate the opposite weakness. Recent compositional frameworks attempt to bridge this gap by combining a planner and an actor, but they are typically static and non-trainable, which prevents adaptation from experience. This is a critical limitation given the scarcity of high-quality data in scientific domains. To address these limitations, we introduce CODA, a novel and trainable compositional framework that integrates a generalist planner (Cerebrum) with a specialist executor (Cerebellum), trained via a dedicated two-stage pipeline. In the first stage, Specialization, we apply a decoupled GRPO approach to train an expert planner for each scientific application individually, bootstrapping from a small set of task trajectories. In the second stage, Generalization, we aggregate all successful trajectories from the specialized experts to build a consolidated dataset, which is then used for supervised fine-tuning of the final planner. This equips CODA with both robust execution and cross-domain generalization. Evaluated on four challenging applications from the ScienceBoard benchmark, CODA significantly outperforms baselines and establishes a new state of the art among open-source models.
Finding Sparse Structure for Domain Specific Neural Machine Translation
Dec 19, 2020

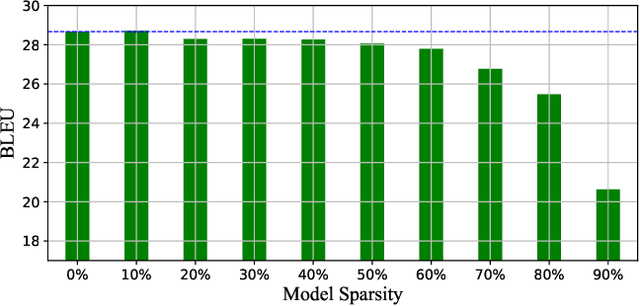

Fine-tuning is a major approach for domain adaptation in Neural Machine Translation (NMT). However, unconstrained fine-tuning requires very careful hyper-parameter tuning otherwise it is easy to fall into over-fitting on the target domain and degradation on the general domain. To mitigate it, we propose PRUNE-TUNE, a novel domain adaptation method via gradual pruning. It learns tiny domain-specific subnetworks for tuning. During adaptation to a new domain, we only tune its corresponding subnetwork. PRUNE-TUNE alleviates the over-fitting and the degradation problem without model modification. Additionally, with no overlapping between domain-specific subnetworks, PRUNE-TUNE is also capable of sequential multi-domain learning. Empirical experiment results show that PRUNE-TUNE outperforms several strong competitors in the target domain test set without the quality degradation of the general domain in both single and multiple domain settings.
Style Transformer: Unpaired Text Style Transfer without Disentangled Latent Representation
May 14, 2019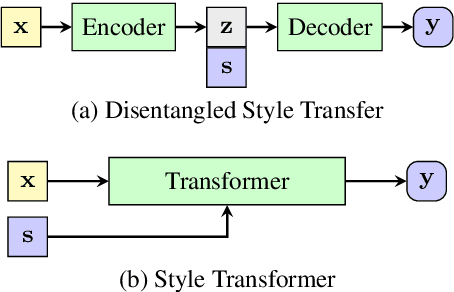
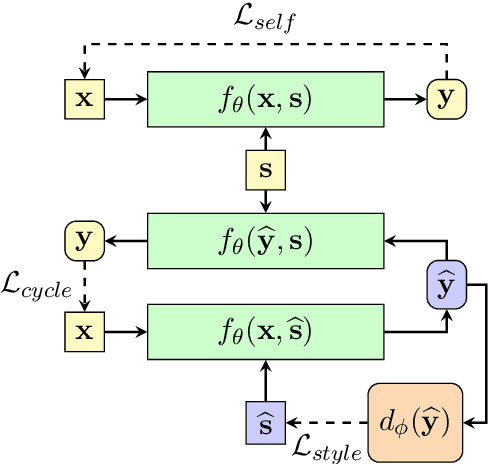
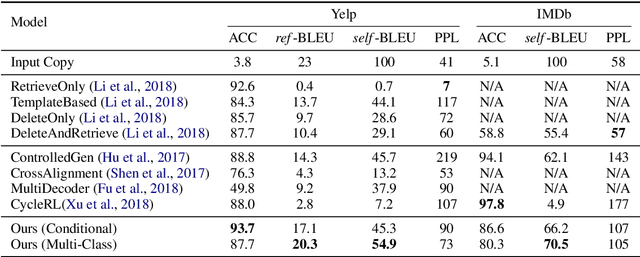
Disentangling the content and style in the latent space is prevalent in unpaired text style transfer. However, two major issues exist in most of the current neural models. 1) It is difficult to completely strip the style information from the semantics for a sentence. 2) The recurrent neural network (RNN) based encoder and decoder, mediated by the latent representation, cannot well deal with the issue of the long-term dependency, resulting in poor preservation of non-stylistic semantic content.In this paper, we propose the Style Transformer, which makes no assumption about the latent representation of source sentence and equips the power of attention mechanism in Transformer to achieve better style transfer and better content preservation.