 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccordion-Thinking: Self-Regulated Step Summaries for Efficient and Readable LLM Reasoning
Feb 03, 2026Scaling test-time compute via long Chain-ofThought unlocks remarkable gains in reasoning capabilities, yet it faces practical limits due to the linear growth of KV cache and quadratic attention complexity. In this paper, we introduce Accordion-Thinking, an end-to-end framework where LLMs learn to self-regulate the granularity of the reasoning steps through dynamic summarization. This mechanism enables a Fold inference mode, where the model periodically summarizes its thought process and discards former thoughts to reduce dependency on historical tokens. We apply reinforcement learning to incentivize this capability further, uncovering a critical insight: the accuracy gap between the highly efficient Fold mode and the exhaustive Unfold mode progressively narrows and eventually vanishes over the course of training. This phenomenon demonstrates that the model learns to encode essential reasoning information into compact summaries, achieving effective compression of the reasoning context. Our Accordion-Thinker demonstrates that with learned self-compression, LLMs can tackle complex reasoning tasks with minimal dependency token overhead without compromising solution quality, and it achieves a 3x throughput while maintaining accuracy on a 48GB GPU memory configuration, while the structured step summaries provide a human-readable account of the reasoning process.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025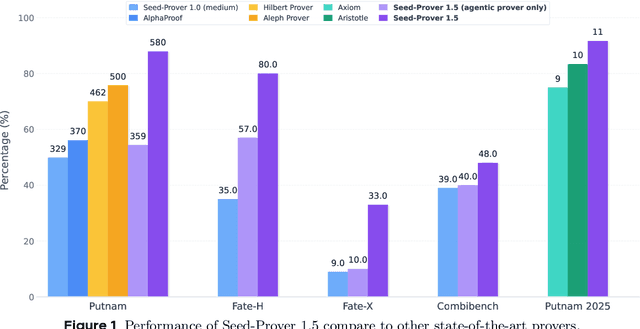

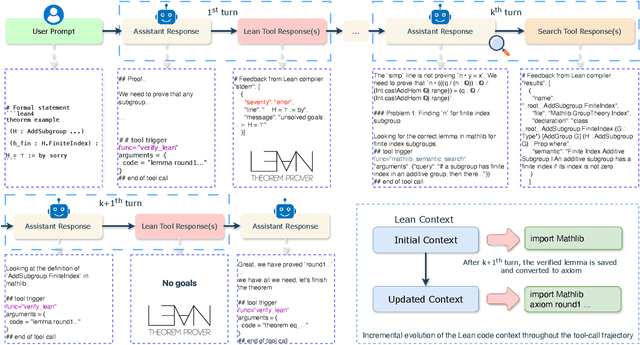

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Heimdall: test-time scaling on the generative verification
Apr 16, 2025An AI system can create and maintain knowledge only to the extent that it can verify that knowledge itself. Recent work on long Chain-of-Thought reasoning has demonstrated great potential of LLMs on solving competitive problems, but their verification ability remains to be weak and not sufficiently investigated. In this paper, we propose Heimdall, the long CoT verification LLM that can accurately judge the correctness of solutions. With pure reinforcement learning, we boost the verification accuracy from 62.5% to 94.5% on competitive math problems. By scaling with repeated sampling, the accuracy further increases to 97.5%. Through human evaluation, Heimdall demonstrates impressive generalization capabilities, successfully detecting most issues in challenging math proofs, the type of which is not included during training. Furthermore, we propose Pessimistic Verification to extend the functionality of Heimdall to scaling up the problem solving. It calls Heimdall to judge the solutions from a solver model and based on the pessimistic principle, selects the most likely correct solution with the least uncertainty. Taking DeepSeek-R1-Distill-Qwen-32B as the solver model, Pessimistic Verification improves the solution accuracy on AIME2025 from 54.2% to 70.0% with 16x compute budget and to 83.3% with more compute budget. With the stronger solver Gemini 2.5 Pro, the score reaches 93.0%. Finally, we prototype an automatic knowledge discovery system, a ternary system where one poses questions, another provides solutions, and the third verifies the solutions. Using the data synthesis work NuminaMath for the first two components, Heimdall effectively identifies problematic records within the dataset and reveals that nearly half of the data is flawed, which interestingly aligns with the recent ablation studies from NuminaMath.
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
Oct 28, 2024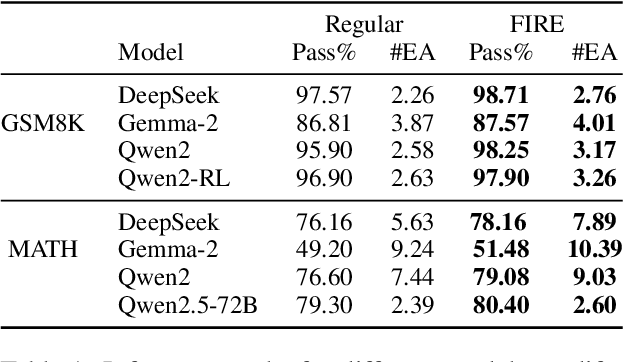


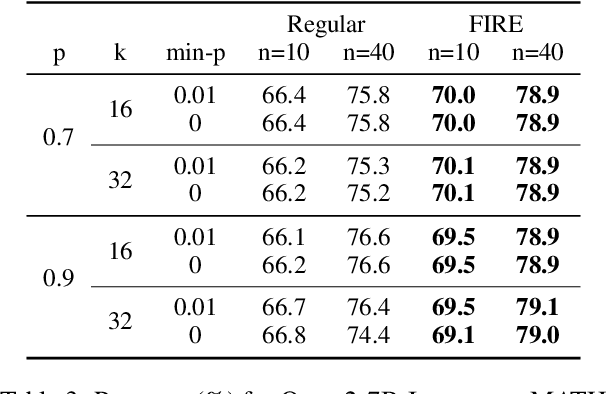
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024
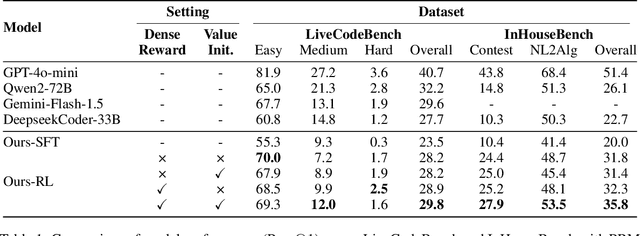

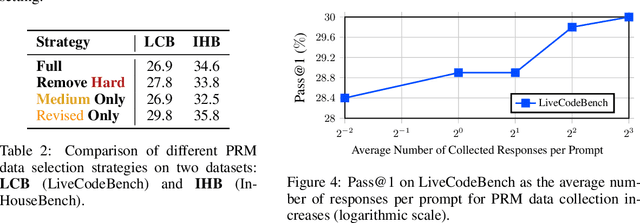
Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
NeuralStagger: accelerating physics-constrained neural PDE solver with spatial-temporal decomposition
Feb 20, 2023



Neural networks have shown great potential in accelerating the solution of partial differential equations (PDEs). Recently, there has been a growing interest in introducing physics constraints into training neural PDE solvers to reduce the use of costly data and improve the generalization ability. However, these physics constraints, based on certain finite dimensional approximations over the function space, must resolve the smallest scaled physics to ensure the accuracy and stability of the simulation, resulting in high computational costs from large input, output, and neural networks. This paper proposes a general acceleration methodology called NeuralStagger by spatially and temporally decomposing the original learning tasks into several coarser-resolution subtasks. We define a coarse-resolution neural solver for each subtask, which requires fewer computational resources, and jointly train them with the vanilla physics-constrained loss by simply arranging their outputs to reconstruct the original solution. Due to the perfect parallelism between them, the solution is achieved as fast as a coarse-resolution neural solver. In addition, the trained solvers bring the flexibility of simulating with multiple levels of resolution. We demonstrate the successful application of NeuralStagger on 2D and 3D fluid dynamics simulations, which leads to an additional $10\sim100\times$ speed-up. Moreover, the experiment also shows that the learned model could be well used for optimal control.
Monte Carlo Neural Operator for Learning PDEs via Probabilistic Representation
Feb 10, 2023



Neural operators, which use deep neural networks to approximate the solution mappings of partial differential equation (PDE) systems, are emerging as a new paradigm for PDE simulation. The neural operators could be trained in supervised or unsupervised ways, i.e., by using the generated data or the PDE information. The unsupervised training approach is essential when data generation is costly or the data is less qualified (e.g., insufficient and noisy). However, its performance and efficiency have plenty of room for improvement. To this end, we design a new loss function based on the Feynman-Kac formula and call the developed neural operator Monte-Carlo Neural Operator (MCNO), which can allow larger temporal steps and efficiently handle fractional diffusion operators. Our analyses show that MCNO has advantages in handling complex spatial conditions and larger temporal steps compared with other unsupervised methods. Furthermore, MCNO is more robust with the perturbation raised by the numerical scheme and operator approximation. Numerical experiments on the diffusion equation and Navier-Stokes equation show significant accuracy improvement compared with other unsupervised baselines, especially for the vibrated initial condition and long-time simulation settings.
LordNet: Learning to Solve Parametric Partial Differential Equations without Simulated Data
Jun 19, 2022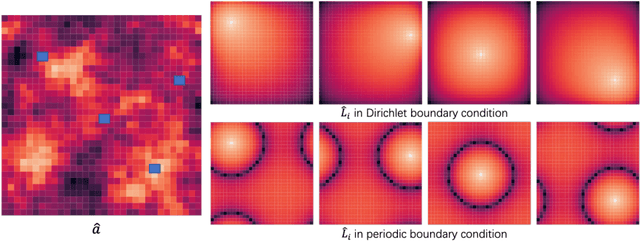
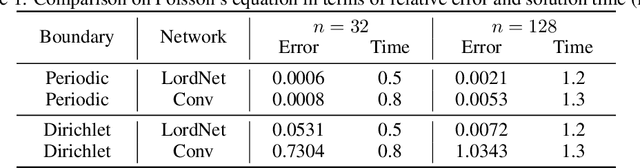
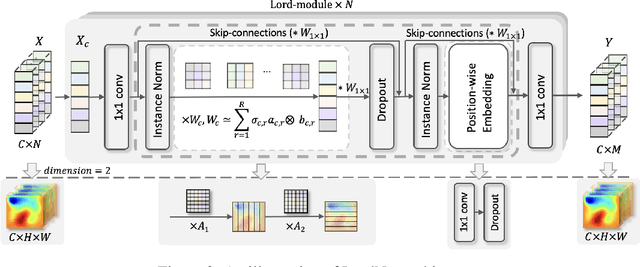
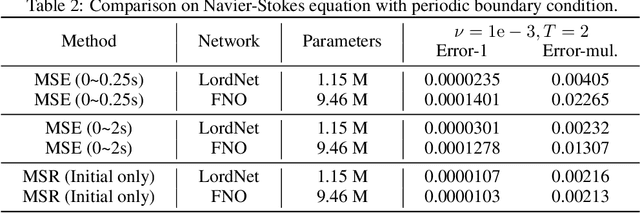
Neural operators, as a powerful approximation to the non-linear operators between infinite-dimensional function spaces, have proved to be promising in accelerating the solution of partial differential equations (PDE). However, it requires a large amount of simulated data which can be costly to collect, resulting in a chicken-egg dilemma and limiting its usage in solving PDEs. To jump out of the dilemma, we propose a general data-free paradigm where the neural network directly learns physics from the mean squared residual (MSR) loss constructed by the discretized PDE. We investigate the physical information in the MSR loss and identify the challenge that the neural network must have the capacity to model the long range entanglements in the spatial domain of the PDE, whose patterns vary in different PDEs. Therefore, we propose the low-rank decomposition network (LordNet) which is tunable and also efficient to model various entanglements. Specifically, LordNet learns a low-rank approximation to the global entanglements with simple fully connected layers, which extracts the dominant pattern with reduced computational cost. The experiments on solving Poisson's equation and Navier-Stokes equation demonstrate that the physical constraints by the MSR loss can lead to better accuracy and generalization ability of the neural network. In addition, LordNet outperforms other modern neural network architectures in both PDEs with the fewest parameters and the fastest inference speed. For Navier-Stokes equation, the learned operator is over 50 times faster than the finite difference solution with the same computational resources.
Learning Physics-Informed Neural Networks without Stacked Back-propagation
Feb 18, 2022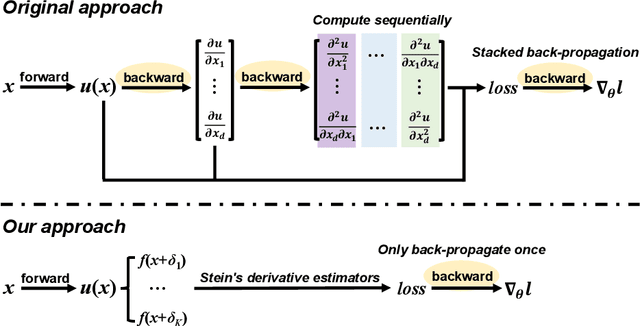
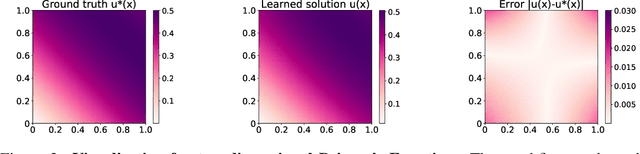
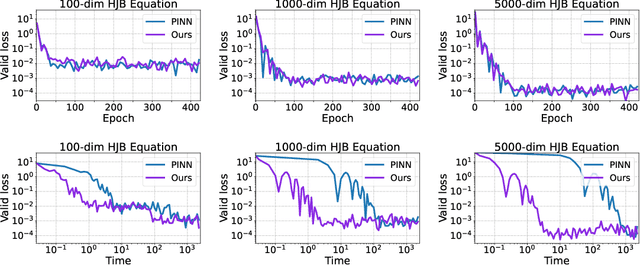
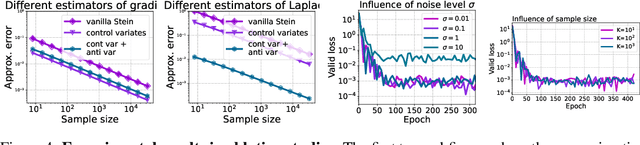
Physics-Informed Neural Network (PINN) has become a commonly used machine learning approach to solve partial differential equations (PDE). But, facing high-dimensional second-order PDE problems, PINN will suffer from severe scalability issues since its loss includes second-order derivatives, the computational cost of which will grow along with the dimension during stacked back-propagation. In this paper, we develop a novel approach that can significantly accelerate the training of Physics-Informed Neural Networks. In particular, we parameterize the PDE solution by the Gaussian smoothed model and show that, derived from Stein's Identity, the second-order derivatives can be efficiently calculated without back-propagation. We further discuss the model capacity and provide variance reduction methods to address key limitations in the derivative estimation. Experimental results show that our proposed method can achieve competitive error compared to standard PINN training but is two orders of magnitude faster.