 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Gems from Roman RAPIDly
Jun 03, 2026The Nancy Grace Roman Space Telescope (Roman), set for launch as early as September 2026, will conduct wide-field infrared imaging surveys with unprecedented spatial resolution and cadence, enabling the discovery of millions of astronomical transients. Hence, it is necessary to have automated pipelines for generating alerts in place so that the telescope can begin discovering reliable transients and variable objects soon after it is launched. However, no real Roman data currently exist, making the development of such pipelines difficult. In this work, we present a machine learning model $RuBR$ and a general methodology for distinguishing genuine transient and variable detections from spurious (bogus) detections within the RAPID pipeline. In particular, we present three models using this methodology: $RuBR_{comb}$ trained and tested on combined locally injected and OpenUniverse2024 transients, $RuBR_{loc}$ trained on locally injected transients and tested on OpenUniverse2024 transients, and $RuBR_{DA}$ that combines locally injected transients with a fraction of OpenUniverse2024 transients in domain-adaptation mode for training. This paves the way for strategies to adapt the $RuBR_{comb}$ model to real observations in the absence of any ground-truth labels during the early phases of the Roman mission. While the image differencing pipeline continues to be improved, our experimental results demonstrate the effectiveness of the proposed approach and its promise for robust real-bogus classification in the Roman era.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
PAG: Multi-Turn Reinforced LLM Self-Correction with Policy as Generative Verifier
Jun 12, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in complex reasoning tasks, yet they still struggle to reliably verify the correctness of their own outputs. Existing solutions to this verification challenge often depend on separate verifier models or require multi-stage self-correction training pipelines, which limit scalability. In this paper, we propose Policy as Generative Verifier (PAG), a simple and effective framework that empowers LLMs to self-correct by alternating between policy and verifier roles within a unified multi-turn reinforcement learning (RL) paradigm. Distinct from prior approaches that always generate a second attempt regardless of model confidence, PAG introduces a selective revision mechanism: the model revises its answer only when its own generative verification step detects an error. This verify-then-revise workflow not only alleviates model collapse but also jointly enhances both reasoning and verification abilities. Extensive experiments across diverse reasoning benchmarks highlight PAG's dual advancements: as a policy, it enhances direct generation and self-correction accuracy; as a verifier, its self-verification outperforms self-consistency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025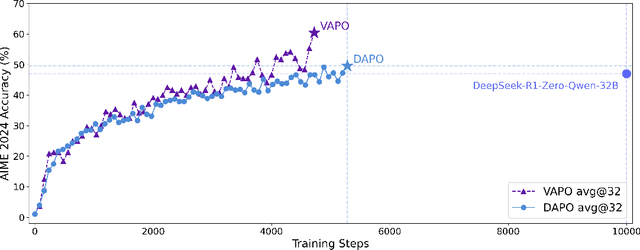

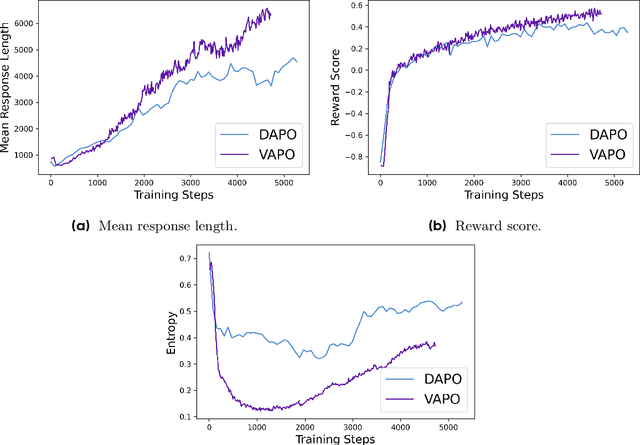
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
A Unified Pairwise Framework for RLHF: Bridging Generative Reward Modeling and Policy Optimization
Apr 07, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a important paradigm for aligning large language models (LLMs) with human preferences during post-training. This framework typically involves two stages: first, training a reward model on human preference data, followed by optimizing the language model using reinforcement learning algorithms. However, current RLHF approaches may constrained by two limitations. First, existing RLHF frameworks often rely on Bradley-Terry models to assign scalar rewards based on pairwise comparisons of individual responses. However, this approach imposes significant challenges on reward model (RM), as the inherent variability in prompt-response pairs across different contexts demands robust calibration capabilities from the RM. Second, reward models are typically initialized from generative foundation models, such as pre-trained or supervised fine-tuned models, despite the fact that reward models perform discriminative tasks, creating a mismatch. This paper introduces Pairwise-RL, a RLHF framework that addresses these challenges through a combination of generative reward modeling and a pairwise proximal policy optimization (PPO) algorithm. Pairwise-RL unifies reward model training and its application during reinforcement learning within a consistent pairwise paradigm, leveraging generative modeling techniques to enhance reward model performance and score calibration. Experimental evaluations demonstrate that Pairwise-RL outperforms traditional RLHF frameworks across both internal evaluation datasets and standard public benchmarks, underscoring its effectiveness in improving alignment and model behavior.
Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
Mar 31, 2025Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human preferences. While recent research has focused on algorithmic improvements, the importance of prompt-data construction has been overlooked. This paper addresses this gap by exploring data-driven bottlenecks in RLHF performance scaling, particularly reward hacking and decreasing response diversity. We introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. We also propose a novel prompt-selection method, Pre-PPO, to maintain response diversity and enhance learning effectiveness. Additionally, we find that prioritizing mathematical and coding tasks early in RLHF training significantly improves performance. Experiments across two model sizes validate our methods' effectiveness and scalability. Results show that RTV is most resistant to reward hacking, followed by GenRM with ground truth, and then GenRM with SFT Best-of-N responses. Our strategies enable rapid capture of subtle task-specific distinctions, leading to substantial improvements in overall RLHF performance. This work highlights the importance of careful data construction and provides practical methods to overcome performance barriers in RLHF.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025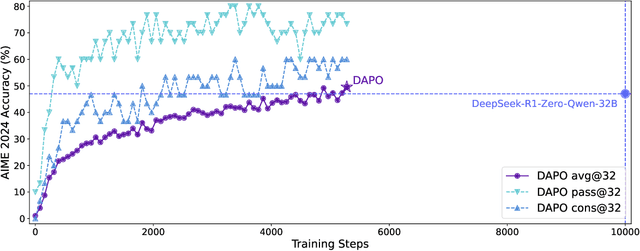

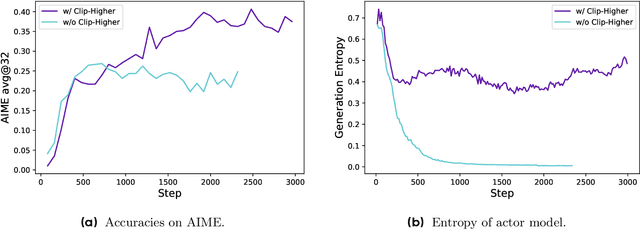

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
What's Behind PPO's Collapse in Long-CoT? Value Optimization Holds the Secret
Mar 03, 2025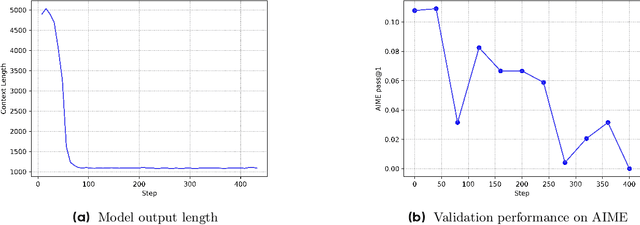

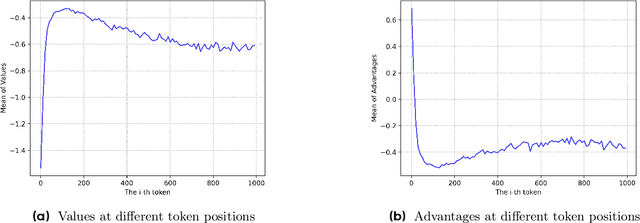
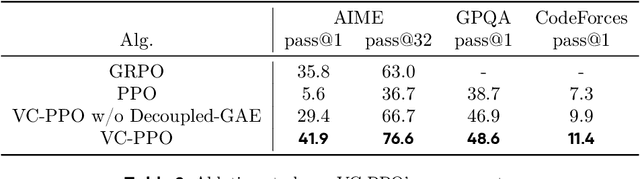
Reinforcement learning (RL) is pivotal for enabling large language models (LLMs) to generate long chains of thought (CoT) for complex tasks like math and reasoning. However, Proximal Policy Optimization (PPO), effective in many RL scenarios, fails in long CoT tasks. This paper identifies that value initialization bias and reward signal decay are the root causes of PPO's failure. We propose Value-Calibrated PPO (VC-PPO) to address these issues. In VC-PPO, the value model is pretrained to tackle initialization bias, and the Generalized Advantage Estimation (GAE) computation is decoupled between the actor and critic to mitigate reward signal decay. Experiments on the American Invitational Mathematics Examination (AIME) show that VC-PPO significantly boosts PPO performance. Ablation studies show that techniques in VC-PPO are essential in enhancing PPO for long CoT tasks.