 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025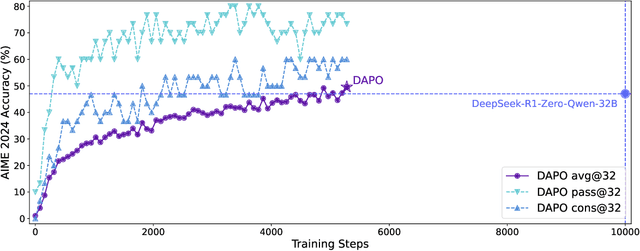

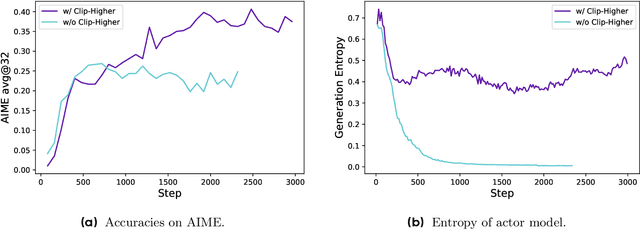

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
What's Behind PPO's Collapse in Long-CoT? Value Optimization Holds the Secret
Mar 03, 2025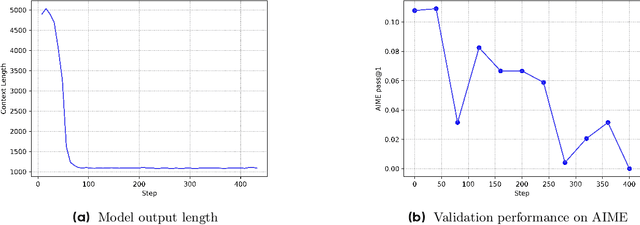

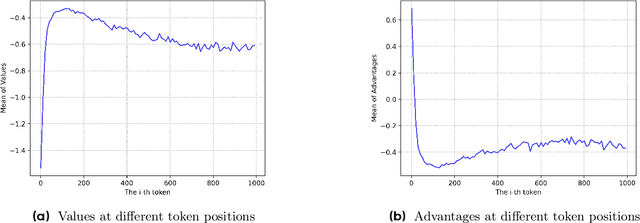
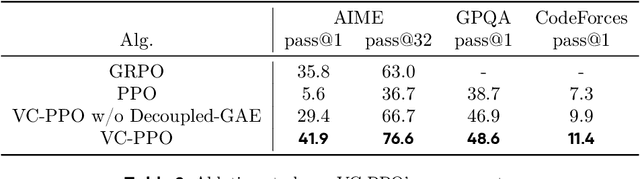
Reinforcement learning (RL) is pivotal for enabling large language models (LLMs) to generate long chains of thought (CoT) for complex tasks like math and reasoning. However, Proximal Policy Optimization (PPO), effective in many RL scenarios, fails in long CoT tasks. This paper identifies that value initialization bias and reward signal decay are the root causes of PPO's failure. We propose Value-Calibrated PPO (VC-PPO) to address these issues. In VC-PPO, the value model is pretrained to tackle initialization bias, and the Generalized Advantage Estimation (GAE) computation is decoupled between the actor and critic to mitigate reward signal decay. Experiments on the American Invitational Mathematics Examination (AIME) show that VC-PPO significantly boosts PPO performance. Ablation studies show that techniques in VC-PPO are essential in enhancing PPO for long CoT tasks.
Knowing Where and What: Unified Word Block Pretraining for Document Understanding
Jul 29, 2022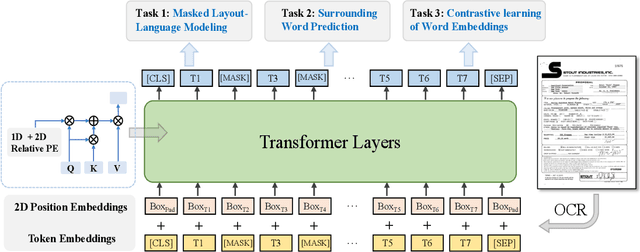
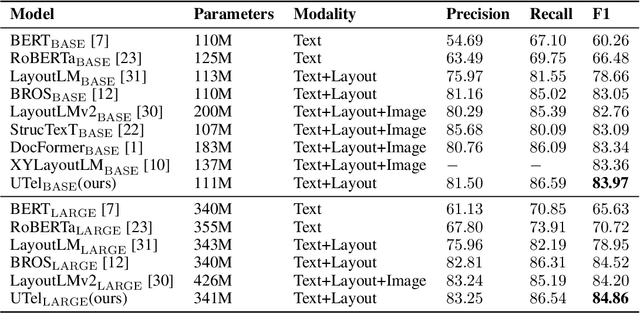
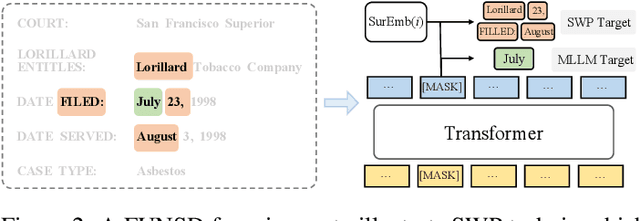

Due to the complex layouts of documents, it is challenging to extract information for documents. Most previous studies develop multimodal pre-trained models in a self-supervised way. In this paper, we focus on the embedding learning of word blocks containing text and layout information, and propose UTel, a language model with Unified TExt and Layout pre-training. Specifically, we propose two pre-training tasks: Surrounding Word Prediction (SWP) for the layout learning, and Contrastive learning of Word Embeddings (CWE) for identifying different word blocks. Moreover, we replace the commonly used 1D position embedding with a 1D clipped relative position embedding. In this way, the joint training of Masked Layout-Language Modeling (MLLM) and two newly proposed tasks enables the interaction between semantic and spatial features in a unified way. Additionally, the proposed UTel can process arbitrary-length sequences by removing the 1D position embedding, while maintaining competitive performance. Extensive experimental results show UTel learns better joint representations and achieves superior performance than previous methods on various downstream tasks, though requiring no image modality. Code is available at \url{https://github.com/taosong2019/UTel}.