 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing Where and What: Unified Word Block Pretraining for Document Understanding
Jul 29, 2022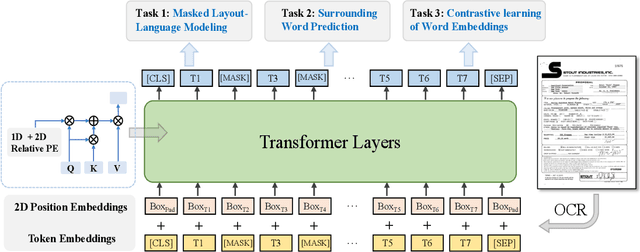
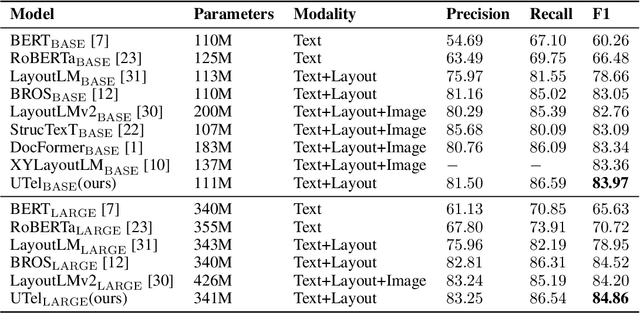
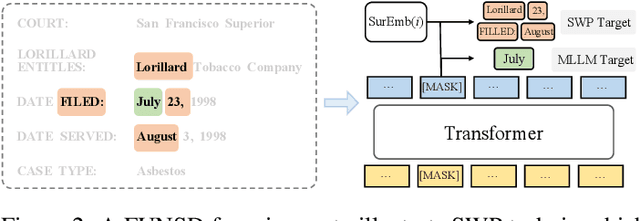

Due to the complex layouts of documents, it is challenging to extract information for documents. Most previous studies develop multimodal pre-trained models in a self-supervised way. In this paper, we focus on the embedding learning of word blocks containing text and layout information, and propose UTel, a language model with Unified TExt and Layout pre-training. Specifically, we propose two pre-training tasks: Surrounding Word Prediction (SWP) for the layout learning, and Contrastive learning of Word Embeddings (CWE) for identifying different word blocks. Moreover, we replace the commonly used 1D position embedding with a 1D clipped relative position embedding. In this way, the joint training of Masked Layout-Language Modeling (MLLM) and two newly proposed tasks enables the interaction between semantic and spatial features in a unified way. Additionally, the proposed UTel can process arbitrary-length sequences by removing the 1D position embedding, while maintaining competitive performance. Extensive experimental results show UTel learns better joint representations and achieves superior performance than previous methods on various downstream tasks, though requiring no image modality. Code is available at \url{https://github.com/taosong2019/UTel}.
Alleviation for Gradient Exploding in GANs: Fake Can Be Real
Dec 28, 2019



In order to alleviate the notorious mode collapse phenomenon in generative adversarial networks (GANs), we propose a novel training method of GANs in which certain fake samples are considered as real ones during the training process. This strategy can reduce the gradient value that generator receives in the region where gradient exploding happens. We show the process of an unbalanced generation and a vicious circle issue resulted from gradient exploding in practical training. We also theoretically prove that gradient exploding can be alleviated with difference penalization for discriminator and fake-as-real consideration for very close real and fake samples . Accordingly, Fake-as-Real GAN (FARGAN) is proposed with a more stable training process and a more faithful generated distribution. Experiments on different datasets verify our theoretical analysis.