 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
SA-WiSense: A Blind-Spot-Free Respiration Sensing Framework for Single-Antenna Wi-Fi Devices
Jul 24, 2025Wi-Fi sensing offers a promising technique for contactless human respiration monitoring. A key challenge, however, is the blind spot problem caused by random phase offsets that corrupt the complementarity of respiratory signals. To address the challenge, we propose a single-antenna-Wi-Fi-sensing (SA-WiSense) framework to improve accuracy of human respiration monitoring, robust against random phase offsets. The proposed SA-WiSense framework is cost-efficient, as only a single antenna is used rather than multiple antennas as in the previous works. Therefore, the proposed framework is applicable to Internet of Thing (IoT), where most of sensors are equipped with a single antenna. On one hand, we propose a cross-subcarrier channel state information (CSI) ratio (CSCR) based blind spot mitigation approach for IoT, where the ratios of two values of CSI between subcarriers are leveraged to mitigate random phase offsets. We prove that the random phase offsets can be cancelled by the proposed CSCR approach, thereby restoring the inherent complementarity of signals for blind-spot-free sensing. On the other hand, we propose a genetic algorithm (GA) based subcarrier selection (GASS) approach by formulating an optimization problem in terms of the sensing-signal-to-noise ratio (SSNR) of CSCR between subcarriers. GA is utilized to solve the formulated optimization problem. We use commodity ESP32 microcontrollers to build an experiment test. The proposed works are validated to achieve an detection rate of 91.2% for respiration monitoring at distances up to 8.0 meters, substantially more accurate than the state-of-the-art methods with a single antenna.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
PAG: Multi-Turn Reinforced LLM Self-Correction with Policy as Generative Verifier
Jun 12, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in complex reasoning tasks, yet they still struggle to reliably verify the correctness of their own outputs. Existing solutions to this verification challenge often depend on separate verifier models or require multi-stage self-correction training pipelines, which limit scalability. In this paper, we propose Policy as Generative Verifier (PAG), a simple and effective framework that empowers LLMs to self-correct by alternating between policy and verifier roles within a unified multi-turn reinforcement learning (RL) paradigm. Distinct from prior approaches that always generate a second attempt regardless of model confidence, PAG introduces a selective revision mechanism: the model revises its answer only when its own generative verification step detects an error. This verify-then-revise workflow not only alleviates model collapse but also jointly enhances both reasoning and verification abilities. Extensive experiments across diverse reasoning benchmarks highlight PAG's dual advancements: as a policy, it enhances direct generation and self-correction accuracy; as a verifier, its self-verification outperforms self-consistency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025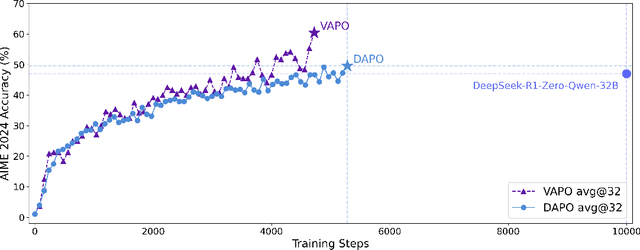

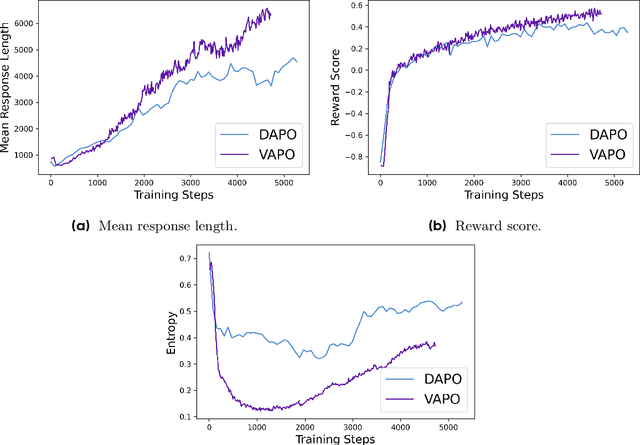
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025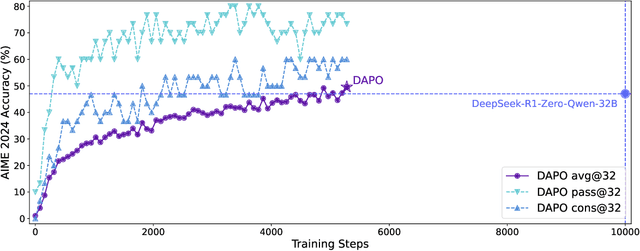

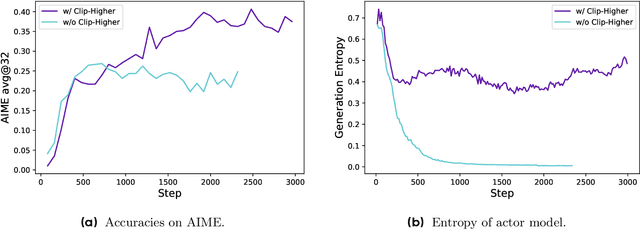

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
What's Behind PPO's Collapse in Long-CoT? Value Optimization Holds the Secret
Mar 03, 2025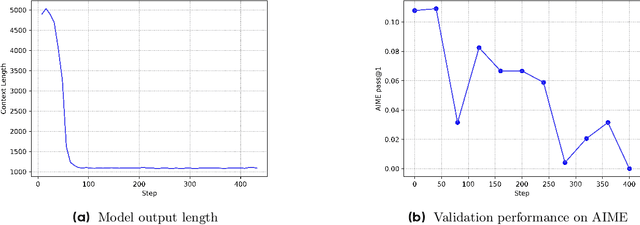

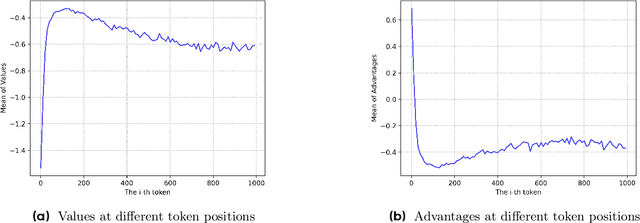
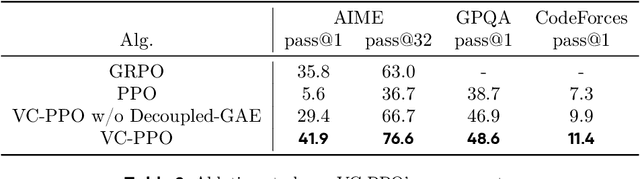
Reinforcement learning (RL) is pivotal for enabling large language models (LLMs) to generate long chains of thought (CoT) for complex tasks like math and reasoning. However, Proximal Policy Optimization (PPO), effective in many RL scenarios, fails in long CoT tasks. This paper identifies that value initialization bias and reward signal decay are the root causes of PPO's failure. We propose Value-Calibrated PPO (VC-PPO) to address these issues. In VC-PPO, the value model is pretrained to tackle initialization bias, and the Generalized Advantage Estimation (GAE) computation is decoupled between the actor and critic to mitigate reward signal decay. Experiments on the American Invitational Mathematics Examination (AIME) show that VC-PPO significantly boosts PPO performance. Ablation studies show that techniques in VC-PPO are essential in enhancing PPO for long CoT tasks.
Asynchronous Reinforcement Learning for Real-Time Control of Physical Robots
Mar 31, 2022
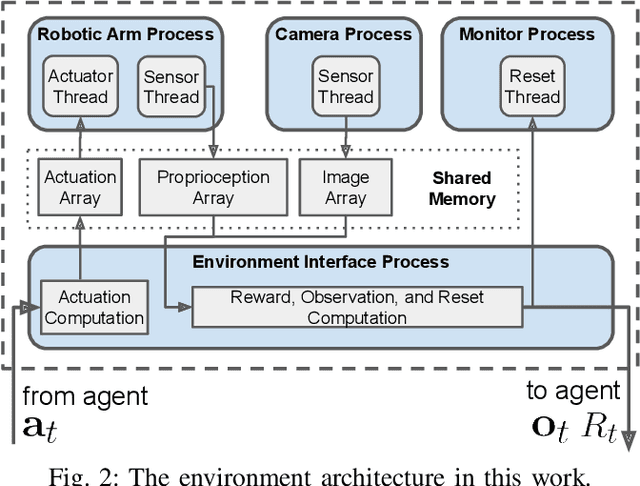
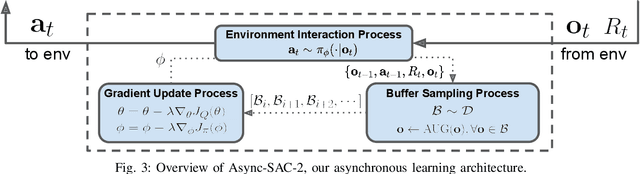
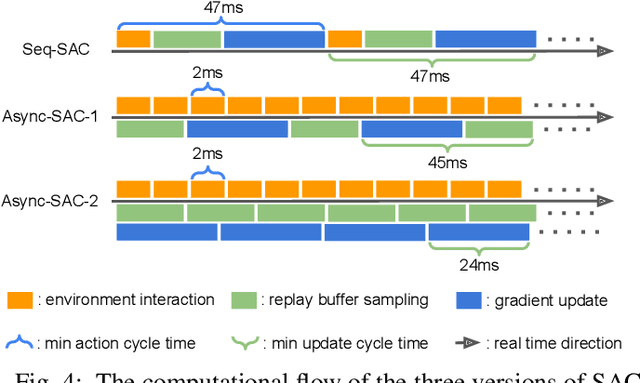
An oft-ignored challenge of real-world reinforcement learning is that the real world does not pause when agents make learning updates. As standard simulated environments do not address this real-time aspect of learning, most available implementations of RL algorithms process environment interactions and learning updates sequentially. As a consequence, when such implementations are deployed in the real world, they may make decisions based on significantly delayed observations and not act responsively. Asynchronous learning has been proposed to solve this issue, but no systematic comparison between sequential and asynchronous reinforcement learning was conducted using real-world environments. In this work, we set up two vision-based tasks with a robotic arm, implement an asynchronous learning system that extends a previous architecture, and compare sequential and asynchronous reinforcement learning across different action cycle times, sensory data dimensions, and mini-batch sizes. Our experiments show that when the time cost of learning updates increases, the action cycle time in sequential implementation could grow excessively long, while the asynchronous implementation can always maintain an appropriate action cycle time. Consequently, when learning updates are expensive, the performance of sequential learning diminishes and is outperformed by asynchronous learning by a substantial margin. Our system learns in real-time to reach and track visual targets from pixels within two hours of experience and does so directly using real robots, learning completely from scratch.