 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-WiSense: A Blind-Spot-Free Respiration Sensing Framework for Single-Antenna Wi-Fi Devices
Jul 24, 2025Wi-Fi sensing offers a promising technique for contactless human respiration monitoring. A key challenge, however, is the blind spot problem caused by random phase offsets that corrupt the complementarity of respiratory signals. To address the challenge, we propose a single-antenna-Wi-Fi-sensing (SA-WiSense) framework to improve accuracy of human respiration monitoring, robust against random phase offsets. The proposed SA-WiSense framework is cost-efficient, as only a single antenna is used rather than multiple antennas as in the previous works. Therefore, the proposed framework is applicable to Internet of Thing (IoT), where most of sensors are equipped with a single antenna. On one hand, we propose a cross-subcarrier channel state information (CSI) ratio (CSCR) based blind spot mitigation approach for IoT, where the ratios of two values of CSI between subcarriers are leveraged to mitigate random phase offsets. We prove that the random phase offsets can be cancelled by the proposed CSCR approach, thereby restoring the inherent complementarity of signals for blind-spot-free sensing. On the other hand, we propose a genetic algorithm (GA) based subcarrier selection (GASS) approach by formulating an optimization problem in terms of the sensing-signal-to-noise ratio (SSNR) of CSCR between subcarriers. GA is utilized to solve the formulated optimization problem. We use commodity ESP32 microcontrollers to build an experiment test. The proposed works are validated to achieve an detection rate of 91.2% for respiration monitoring at distances up to 8.0 meters, substantially more accurate than the state-of-the-art methods with a single antenna.
RSSI-Based Localization Utilizing Antenna Radiation Pattern And Biased CRLB Analysis
Feb 25, 2025This paper presents a novel indoor positioning approach that leverages antenna radiation pattern characteristics through Received Signal Strength Indication (RSSI) measurements in a single-antenna system. By rotating the antenna or reconfiguring its radiation pattern, we derive a maximum likelihood estimation (MLE) algorithm that achieves near-optimal positioning accuracy approaching the Cramer-Rao lower bound (CRLB). Through theoretical analysis, we establish three fundamental theorems characterizing the estimation accuracy bounds and demonstrating how performance improves with increased signal-to-noise ratio, antenna rotation count, and radiation pattern variations. Additionally, we propose a two-position measurement strategy that eliminates dependence on receiving antenna patterns. Simulation results validate that our approach provides an effective solution for indoor robot tracking applications where both accuracy and system simplicity are essential considerations.
Compressed Support Vector Machines
Feb 02, 2015



Support vector machines (SVM) can classify data sets along highly non-linear decision boundaries because of the kernel-trick. This expressiveness comes at a price: During test-time, the SVM classifier needs to compute the kernel inner-product between a test sample and all support vectors. With large training data sets, the time required for this computation can be substantial. In this paper, we introduce a post-processing algorithm, which compresses the learned SVM model by reducing and optimizing support vectors. We evaluate our algorithm on several medium-scaled real-world data sets, demonstrating that it maintains high test accuracy while reducing the test-time evaluation cost by several orders of magnitude---in some cases from hours to seconds. It is fair to say that most of the work in this paper was previously been invented by Burges and Sch\"olkopf almost 20 years ago. For most of the time during which we conducted this research, we were unaware of this prior work. However, in the past two decades, computing power has increased drastically, and we can therefore provide empirical insights that were not possible in their original paper.
Cost-Sensitive Tree of Classifiers
Apr 22, 2013


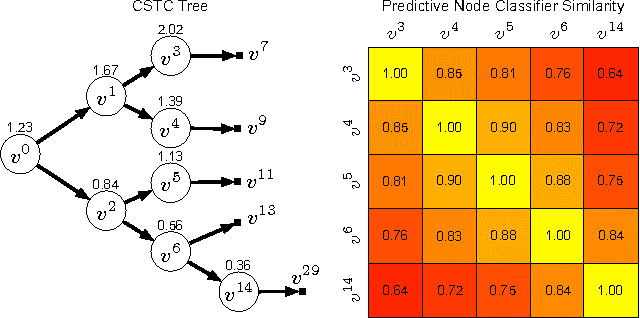
Recently, machine learning algorithms have successfully entered large-scale real-world industrial applications (e.g. search engines and email spam filters). Here, the CPU cost during test time must be budgeted and accounted for. In this paper, we address the challenge of balancing the test-time cost and the classifier accuracy in a principled fashion. The test-time cost of a classifier is often dominated by the computation required for feature extraction-which can vary drastically across eatures. We decrease this extraction time by constructing a tree of classifiers, through which test inputs traverse along individual paths. Each path extracts different features and is optimized for a specific sub-partition of the input space. By only computing features for inputs that benefit from them the most, our cost sensitive tree of classifiers can match the high accuracies of the current state-of-the-art at a small fraction of the computational cost.
Distance Metric Learning for Kernel Machines
Jan 08, 2013
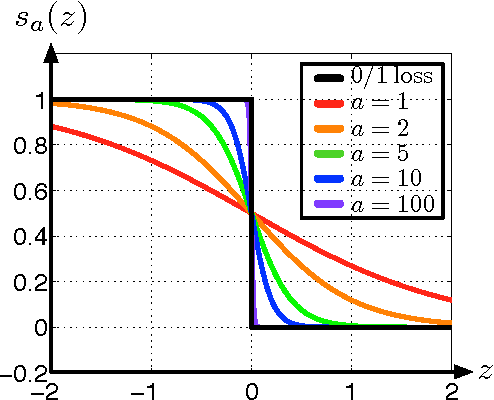

Recent work in metric learning has significantly improved the state-of-the-art in k-nearest neighbor classification. Support vector machines (SVM), particularly with RBF kernels, are amongst the most popular classification algorithms that uses distance metrics to compare examples. This paper provides an empirical analysis of the efficacy of three of the most popular Mahalanobis metric learning algorithms as pre-processing for SVM training. We show that none of these algorithms generate metrics that lead to particularly satisfying improvements for SVM-RBF classification. As a remedy we introduce support vector metric learning (SVML), a novel algorithm that seamlessly combines the learning of a Mahalanobis metric with the training of the RBF-SVM parameters. We demonstrate the capabilities of SVML on nine benchmark data sets of varying sizes and difficulties. In our study, SVML outperforms all alternative state-of-the-art metric learning algorithms in terms of accuracy and establishes itself as a serious alternative to the standard Euclidean metric with model selection by cross validation.
The Greedy Miser: Learning under Test-time Budgets
Jun 27, 2012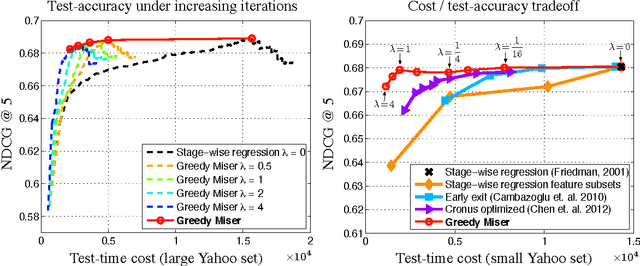
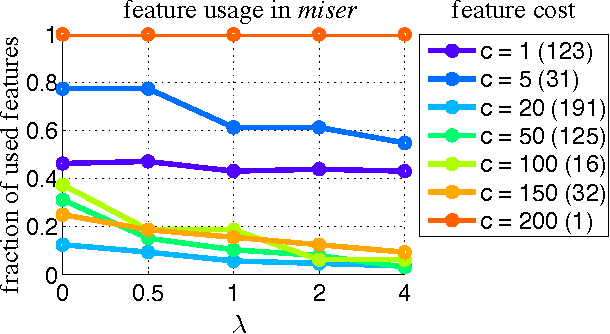
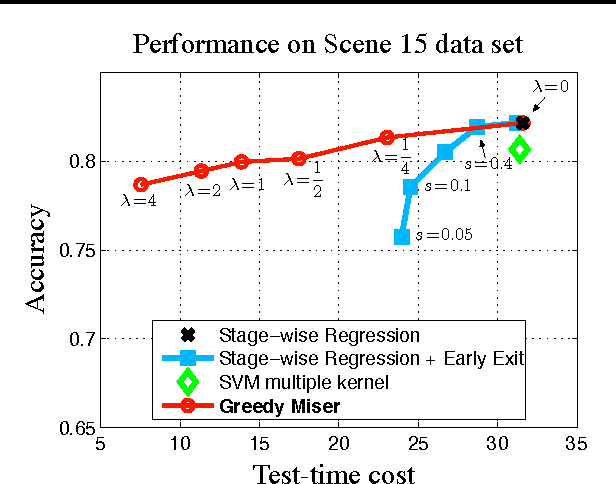

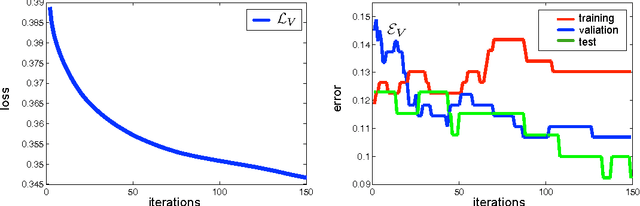
As machine learning algorithms enter applications in industrial settings, there is increased interest in controlling their cpu-time during testing. The cpu-time consists of the running time of the algorithm and the extraction time of the features. The latter can vary drastically when the feature set is diverse. In this paper, we propose an algorithm, the Greedy Miser, that incorporates the feature extraction cost during training to explicitly minimize the cpu-time during testing. The algorithm is a straightforward extension of stage-wise regression and is equally suitable for regression or multi-class classification. Compared to prior work, it is significantly more cost-effective and scales to larger data sets.
Marginalized Denoising Autoencoders for Domain Adaptation
Jun 18, 2012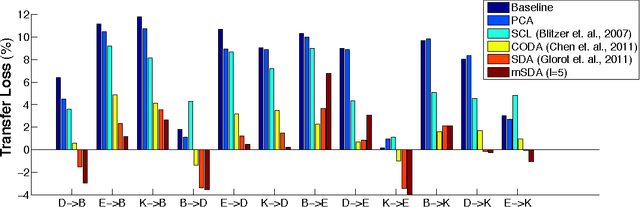
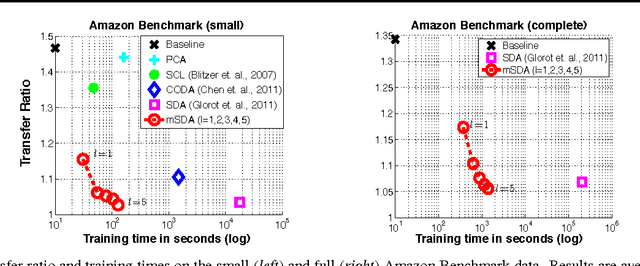
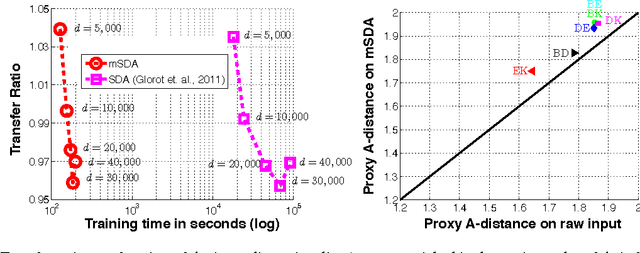
Stacked denoising autoencoders (SDAs) have been successfully used to learn new representations for domain adaptation. Recently, they have attained record accuracy on standard benchmark tasks of sentiment analysis across different text domains. SDAs learn robust data representations by reconstruction, recovering original features from data that are artificially corrupted with noise. In this paper, we propose marginalized SDA (mSDA) that addresses two crucial limitations of SDAs: high computational cost and lack of scalability to high-dimensional features. In contrast to SDAs, our approach of mSDA marginalizes noise and thus does not require stochastic gradient descent or other optimization algorithms to learn parameters ? in fact, they are computed in closed-form. Consequently, mSDA, which can be implemented in only 20 lines of MATLAB^{TM}, significantly speeds up SDAs by two orders of magnitude. Furthermore, the representations learnt by mSDA are as effective as the traditional SDAs, attaining almost identical accuracies in benchmark tasks.