 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM feedback enhance review quality? A randomized study of 20K reviews at ICLR 2025
Apr 13, 2025Peer review at AI conferences is stressed by rapidly rising submission volumes, leading to deteriorating review quality and increased author dissatisfaction. To address these issues, we developed Review Feedback Agent, a system leveraging multiple large language models (LLMs) to improve review clarity and actionability by providing automated feedback on vague comments, content misunderstandings, and unprofessional remarks to reviewers. Implemented at ICLR 2025 as a large randomized control study, our system provided optional feedback to more than 20,000 randomly selected reviews. To ensure high-quality feedback for reviewers at this scale, we also developed a suite of automated reliability tests powered by LLMs that acted as guardrails to ensure feedback quality, with feedback only being sent to reviewers if it passed all the tests. The results show that 27% of reviewers who received feedback updated their reviews, and over 12,000 feedback suggestions from the agent were incorporated by those reviewers. This suggests that many reviewers found the AI-generated feedback sufficiently helpful to merit updating their reviews. Incorporating AI feedback led to significantly longer reviews (an average increase of 80 words among those who updated after receiving feedback) and more informative reviews, as evaluated by blinded researchers. Moreover, reviewers who were selected to receive AI feedback were also more engaged during paper rebuttals, as seen in longer author-reviewer discussions. This work demonstrates that carefully designed LLM-generated review feedback can enhance peer review quality by making reviews more specific and actionable while increasing engagement between reviewers and authors. The Review Feedback Agent is publicly available at https://github.com/zou-group/review_feedback_agent.
Statistical Downscaling via High-Dimensional Distribution Matching with Generative Models
Dec 11, 2024Statistical downscaling is a technique used in climate modeling to increase the resolution of climate simulations. High-resolution climate information is essential for various high-impact applications, including natural hazard risk assessment. However, simulating climate at high resolution is intractable. Thus, climate simulations are often conducted at a coarse scale and then downscaled to the desired resolution. Existing downscaling techniques are either simulation-based methods with high computational costs, or statistical approaches with limitations in accuracy or application specificity. We introduce Generative Bias Correction and Super-Resolution (GenBCSR), a two-stage probabilistic framework for statistical downscaling that overcomes the limitations of previous methods. GenBCSR employs two transformations to match high-dimensional distributions at different resolutions: (i) the first stage, bias correction, aligns the distributions at coarse scale, (ii) the second stage, statistical super-resolution, lifts the corrected coarse distribution by introducing fine-grained details. Each stage is instantiated by a state-of-the-art generative model, resulting in an efficient and effective computational pipeline for the well-studied distribution matching problem. By framing the downscaling problem as distribution matching, GenBCSR relaxes the constraints of supervised learning, which requires samples to be aligned. Despite not requiring such correspondence, we show that GenBCSR surpasses standard approaches in predictive accuracy of critical impact variables, particularly in predicting the tails (99% percentile) of composite indexes composed of interacting variables, achieving up to 4-5 folds of error reduction.
Diff4Steer: Steerable Diffusion Prior for Generative Music Retrieval with Semantic Guidance
Dec 06, 2024Modern music retrieval systems often rely on fixed representations of user preferences, limiting their ability to capture users' diverse and uncertain retrieval needs. To address this limitation, we introduce Diff4Steer, a novel generative retrieval framework that employs lightweight diffusion models to synthesize diverse seed embeddings from user queries that represent potential directions for music exploration. Unlike deterministic methods that map user query to a single point in embedding space, Diff4Steer provides a statistical prior on the target modality (audio) for retrieval, effectively capturing the uncertainty and multi-faceted nature of user preferences. Furthermore, Diff4Steer can be steered by image or text inputs, enabling more flexible and controllable music discovery combined with nearest neighbor search. Our framework outperforms deterministic regression methods and LLM-based generative retrieval baseline in terms of retrieval and ranking metrics, demonstrating its effectiveness in capturing user preferences, leading to more diverse and relevant recommendations. Listening examples are available at tinyurl.com/diff4steer.
Dynamical-generative downscaling of climate model ensembles
Oct 02, 2024



Regional high-resolution climate projections are crucial for many applications, such as agriculture, hydrology, and natural hazard risk assessment. Dynamical downscaling, the state-of-the-art method to produce localized future climate information, involves running a regional climate model (RCM) driven by an Earth System Model (ESM), but it is too computationally expensive to apply to large climate projection ensembles. We propose a novel approach combining dynamical downscaling with generative artificial intelligence to reduce the cost and improve the uncertainty estimates of downscaled climate projections. In our framework, an RCM dynamically downscales ESM output to an intermediate resolution, followed by a generative diffusion model that further refines the resolution to the target scale. This approach leverages the generalizability of physics-based models and the sampling efficiency of diffusion models, enabling the downscaling of large multi-model ensembles. We evaluate our method against dynamically-downscaled climate projections from the CMIP6 ensemble. Our results demonstrate its ability to provide more accurate uncertainty bounds on future regional climate than alternatives such as dynamical downscaling of smaller ensembles, or traditional empirical statistical downscaling methods. We also show that dynamical-generative downscaling results in significantly lower errors than bias correction and spatial disaggregation (BCSD), and captures more accurately the spectra and multivariate correlations of meteorological fields. These characteristics make the dynamical-generative framework a flexible, accurate, and efficient way to downscale large ensembles of climate projections, currently out of reach for pure dynamical downscaling.
Generative AI for fast and accurate Statistical Computation of Fluids
Sep 27, 2024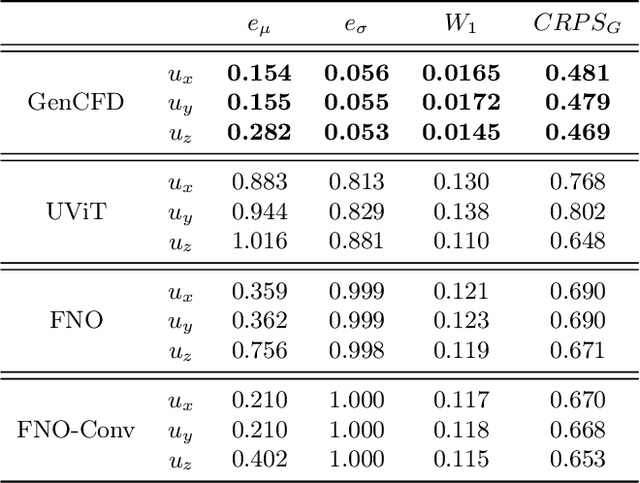
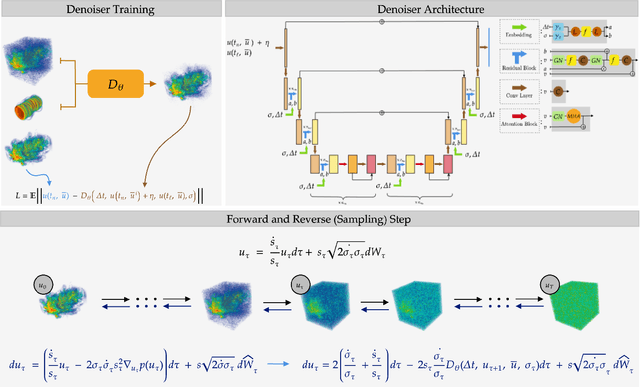
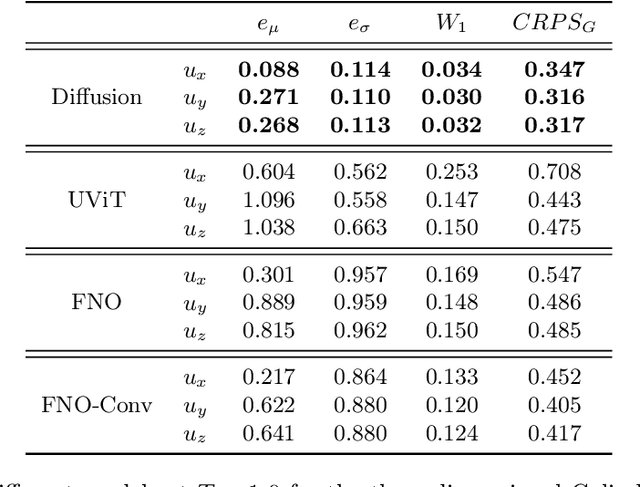

We present a generative AI algorithm for addressing the challenging task of fast, accurate and robust statistical computation of three-dimensional turbulent fluid flows. Our algorithm, termed as GenCFD, is based on a conditional score-based diffusion model. Through extensive numerical experimentation with both incompressible and compressible fluid flows, we demonstrate that GenCFD provides very accurate approximation of statistical quantities of interest such as mean, variance, point pdfs, higher-order moments, while also generating high quality realistic samples of turbulent fluid flows and ensuring excellent spectral resolution. In contrast, ensembles of operator learning baselines which are trained to minimize mean (absolute) square errors regress to the mean flow. We present rigorous theoretical results uncovering the surprising mechanisms through which diffusion models accurately generate fluid flows. These mechanisms are illustrated with solvable toy models that exhibit the relevant features of turbulent fluid flows while being amenable to explicit analytical formulas.
Rational-WENO: A lightweight, physically-consistent three-point weighted essentially non-oscillatory scheme
Sep 13, 2024



Conventional WENO3 methods are known to be highly dissipative at lower resolutions, introducing significant errors in the pre-asymptotic regime. In this paper, we employ a rational neural network to accurately estimate the local smoothness of the solution, dynamically adapting the stencil weights based on local solution features. As rational neural networks can represent fast transitions between smooth and sharp regimes, this approach achieves a granular reconstruction with significantly reduced dissipation, improving the accuracy of the simulation. The network is trained offline on a carefully chosen dataset of analytical functions, bypassing the need for differentiable solvers. We also propose a robust model selection criterion based on estimates of the interpolation's convergence order on a set of test functions, which correlates better with the model performance in downstream tasks. We demonstrate the effectiveness of our approach on several one-, two-, and three-dimensional fluid flow problems: our scheme generalizes across grid resolutions while handling smooth and discontinuous solutions. In most cases, our rational network-based scheme achieves higher accuracy than conventional WENO3 with the same stencil size, and in a few of them, it achieves accuracy comparable to WENO5, which uses a larger stencil.
A probabilistic framework for learning non-intrusive corrections to long-time climate simulations from short-time training data
Aug 02, 2024Chaotic systems, such as turbulent flows, are ubiquitous in science and engineering. However, their study remains a challenge due to the large range scales, and the strong interaction with other, often not fully understood, physics. As a consequence, the spatiotemporal resolution required for accurate simulation of these systems is typically computationally infeasible, particularly for applications of long-term risk assessment, such as the quantification of extreme weather risk due to climate change. While data-driven modeling offers some promise of alleviating these obstacles, the scarcity of high-quality simulations results in limited available data to train such models, which is often compounded by the lack of stability for long-horizon simulations. As such, the computational, algorithmic, and data restrictions generally imply that the probability of rare extreme events is not accurately captured. In this work we present a general strategy for training neural network models to non-intrusively correct under-resolved long-time simulations of chaotic systems. The approach is based on training a post-processing correction operator on under-resolved simulations nudged towards a high-fidelity reference. This enables us to learn the dynamics of the underlying system directly, which allows us to use very little training data, even when the statistics thereof are far from converged. Additionally, through the use of probabilistic network architectures we are able to leverage the uncertainty due to the limited training data to further improve extrapolation capabilities. We apply our framework to severely under-resolved simulations of quasi-geostrophic flow and demonstrate its ability to accurately predict the anisotropic statistics over time horizons more than 30 times longer than the data seen in training.
DySLIM: Dynamics Stable Learning by Invariant Measure for Chaotic Systems
Feb 06, 2024



Learning dynamics from dissipative chaotic systems is notoriously difficult due to their inherent instability, as formalized by their positive Lyapunov exponents, which exponentially amplify errors in the learned dynamics. However, many of these systems exhibit ergodicity and an attractor: a compact and highly complex manifold, to which trajectories converge in finite-time, that supports an invariant measure, i.e., a probability distribution that is invariant under the action of the dynamics, which dictates the long-term statistical behavior of the system. In this work, we leverage this structure to propose a new framework that targets learning the invariant measure as well as the dynamics, in contrast with typical methods that only target the misfit between trajectories, which often leads to divergence as the trajectories' length increases. We use our framework to propose a tractable and sample efficient objective that can be used with any existing learning objectives. Our Dynamics Stable Learning by Invariant Measures (DySLIM) objective enables model training that achieves better point-wise tracking and long-term statistical accuracy relative to other learning objectives. By targeting the distribution with a scalable regularization term, we hope that this approach can be extended to more complex systems exhibiting slowly-variant distributions, such as weather and climate models.
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Nov 01, 2023



A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate these biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises, which have been studied extensively in psychology -- we show that larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases such as ordering effects and logical fallacies. Overall, we find that language models mimic the human biases included in their training data, but are able to overcome them in some cases.
The Impact of Depth and Width on Transformer Language Model Generalization
Oct 30, 2023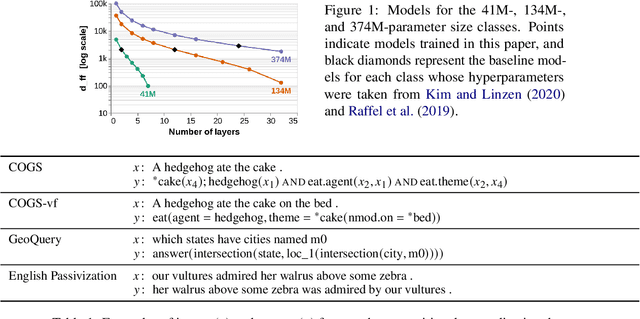
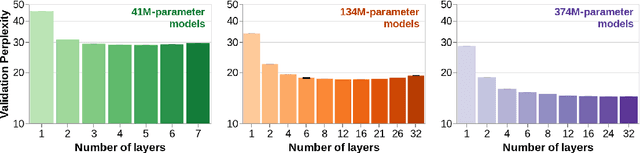

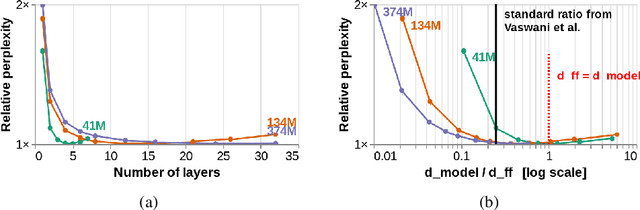
To process novel sentences, language models (LMs) must generalize compositionally -- combine familiar elements in new ways. What aspects of a model's structure promote compositional generalization? Focusing on transformers, we test the hypothesis, motivated by recent theoretical and empirical work, that transformers generalize more compositionally when they are deeper (have more layers). Because simply adding layers increases the total number of parameters, confounding depth and size, we construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters). We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions: (1) after fine-tuning, deeper models generalize better out-of-distribution than shallower models do, but the relative benefit of additional layers diminishes rapidly; (2) within each family, deeper models show better language modeling performance, but returns are similarly diminishing; (3) the benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling or on in-distribution data.