 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff4Steer: Steerable Diffusion Prior for Generative Music Retrieval with Semantic Guidance
Dec 06, 2024Modern music retrieval systems often rely on fixed representations of user preferences, limiting their ability to capture users' diverse and uncertain retrieval needs. To address this limitation, we introduce Diff4Steer, a novel generative retrieval framework that employs lightweight diffusion models to synthesize diverse seed embeddings from user queries that represent potential directions for music exploration. Unlike deterministic methods that map user query to a single point in embedding space, Diff4Steer provides a statistical prior on the target modality (audio) for retrieval, effectively capturing the uncertainty and multi-faceted nature of user preferences. Furthermore, Diff4Steer can be steered by image or text inputs, enabling more flexible and controllable music discovery combined with nearest neighbor search. Our framework outperforms deterministic regression methods and LLM-based generative retrieval baseline in terms of retrieval and ranking metrics, demonstrating its effectiveness in capturing user preferences, leading to more diverse and relevant recommendations. Listening examples are available at tinyurl.com/diff4steer.
Item-Language Model for Conversational Recommendation
Jun 05, 2024Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
V2Meow: Meowing to the Visual Beat via Music Generation
May 11, 2023
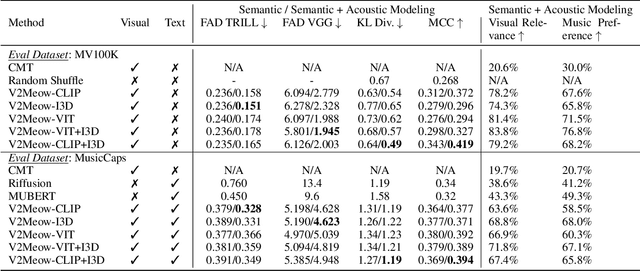

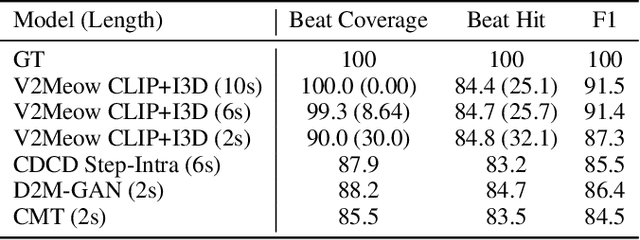
Generating high quality music that complements the visual content of a video is a challenging task. Most existing visual conditioned music generation systems generate symbolic music data, such as MIDI files, instead of raw audio waveform. Given the limited availability of symbolic music data, such methods can only generate music for a few instruments or for specific types of visual input. In this paper, we propose a novel approach called V2Meow that can generate high-quality music audio that aligns well with the visual semantics of a diverse range of video input types. Specifically, the proposed music generation system is a multi-stage autoregressive model which is trained with a number of O(100K) music audio clips paired with video frames, which are mined from in-the-wild music videos, and no parallel symbolic music data is involved. V2Meow is able to synthesize high-fidelity music audio waveform solely conditioned on pre-trained visual features extracted from an arbitrary silent video clip, and it also allows high-level control over the music style of generation examples via supporting text prompts in addition to the video frames conditioning. Through both qualitative and quantitative evaluations, we demonstrate that our model outperforms several existing music generation systems in terms of both visual-audio correspondence and audio quality.
Multi-Task End-to-End Training Improves Conversational Recommendation
May 08, 2023



In this paper, we analyze the performance of a multitask end-to-end transformer model on the task of conversational recommendations, which aim to provide recommendations based on a user's explicit preferences expressed in dialogue. While previous works in this area adopt complex multi-component approaches where the dialogue management and entity recommendation tasks are handled by separate components, we show that a unified transformer model, based on the T5 text-to-text transformer model, can perform competitively in both recommending relevant items and generating conversation dialogue. We fine-tune our model on the ReDIAL conversational movie recommendation dataset, and create additional training tasks derived from MovieLens (such as the prediction of movie attributes and related movies based on an input movie), in a multitask learning setting. Using a series of probe studies, we demonstrate that the learned knowledge in the additional tasks is transferred to the conversational setting, where each task leads to a 9%-52% increase in its related probe score.
MAQA: A Multimodal QA Benchmark for Negation
Jan 09, 2023
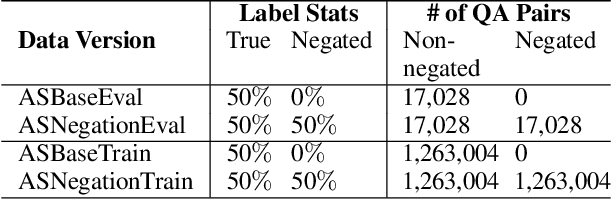
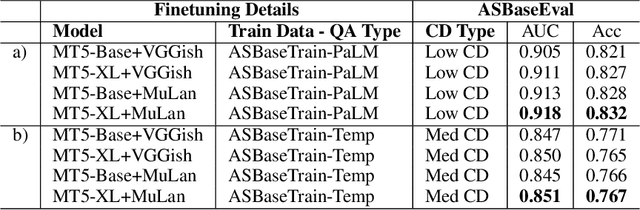
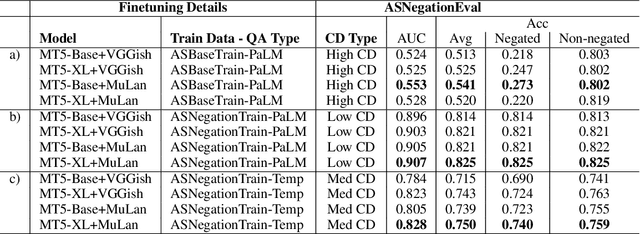
Multimodal learning can benefit from the representation power of pretrained Large Language Models (LLMs). However, state-of-the-art transformer based LLMs often ignore negations in natural language and there is no existing benchmark to quantitatively evaluate whether multimodal transformers inherit this weakness. In this study, we present a new multimodal question answering (QA) benchmark adapted from labeled music videos in AudioSet (Gemmeke et al., 2017) with the goal of systematically evaluating if multimodal transformers can perform complex reasoning to recognize new concepts as negation of previously learned concepts. We show that with standard fine-tuning approach multimodal transformers are still incapable of correctly interpreting negation irrespective of model size. However, our experiments demonstrate that augmenting the original training task distributions with negated QA examples allow the model to reliably reason with negation. To do this, we describe a novel data generation procedure that prompts the 540B-parameter PaLM model to automatically generate negated QA examples as compositions of easily accessible video tags. The generated examples contain more natural linguistic patterns and the gains compared to template-based task augmentation approach are significant.
MuLan: A Joint Embedding of Music Audio and Natural Language
Aug 26, 2022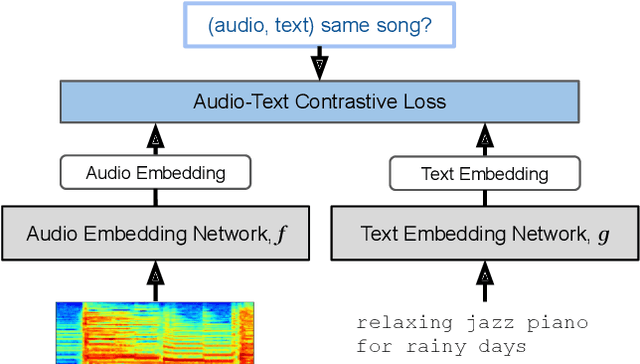


Music tagging and content-based retrieval systems have traditionally been constructed using pre-defined ontologies covering a rigid set of music attributes or text queries. This paper presents MuLan: a first attempt at a new generation of acoustic models that link music audio directly to unconstrained natural language music descriptions. MuLan takes the form of a two-tower, joint audio-text embedding model trained using 44 million music recordings (370K hours) and weakly-associated, free-form text annotations. Through its compatibility with a wide range of music genres and text styles (including conventional music tags), the resulting audio-text representation subsumes existing ontologies while graduating to true zero-shot functionalities. We demonstrate the versatility of the MuLan embeddings with a range of experiments including transfer learning, zero-shot music tagging, language understanding in the music domain, and cross-modal retrieval applications.