 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeItem-Language Model for Conversational Recommendation
Jun 05, 2024Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
Forecasting Solar Power Generation on the basis of Predictive and Corrective Maintenance Activities
May 17, 2022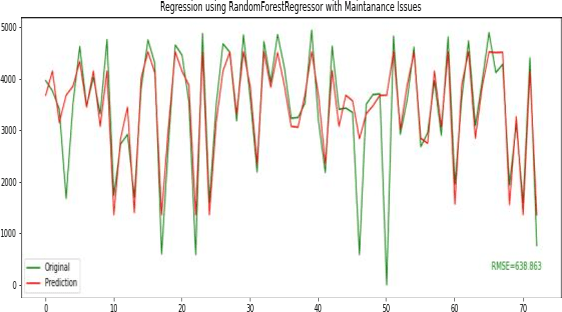

Solar energy forecasting has seen tremendous growth in the last decade using historical time series collected from a weather station, such as weather variables wind speed and direction, solar radiance, and temperature. It helps in the overall management of solar power plants. However, the solar power plant regularly requires preventive and corrective maintenance activities that further impact energy production. This paper presents a novel work for forecasting solar power energy production based on maintenance activities, problems observed at a power plant, and weather data. The results accomplished on the datasets obtained from the 1MW solar power plant of PDEU (our university) that has generated data set with 13 columns as daily entries from 2012 to 2020. There are 12 structured columns and one unstructured column with manual text entries about different maintenance activities, problems observed, and weather conditions daily. The unstructured column is used to create a new feature column vector using Hash Map, flag words, and stop words. The final dataset comprises five important feature vector columns based on correlation and causality analysis.