 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessive Halving with Learning Curve Prediction via Latent Kronecker Gaussian Processes
Aug 20, 2025Successive Halving is a popular algorithm for hyperparameter optimization which allocates exponentially more resources to promising candidates. However, the algorithm typically relies on intermediate performance values to make resource allocation decisions, which can cause it to prematurely prune slow starters that would eventually become the best candidate. We investigate whether guiding Successive Halving with learning curve predictions based on Latent Kronecker Gaussian Processes can overcome this limitation. In a large-scale empirical study involving different neural network architectures and a click prediction dataset, we compare this predictive approach to the standard approach based on current performance values. Our experiments show that, although the predictive approach achieves competitive performance, it is not Pareto optimal compared to investing more resources into the standard approach, because it requires fully observed learning curves as training data. However, this downside could be mitigated by leveraging existing learning curve data.
Diff4Steer: Steerable Diffusion Prior for Generative Music Retrieval with Semantic Guidance
Dec 06, 2024Modern music retrieval systems often rely on fixed representations of user preferences, limiting their ability to capture users' diverse and uncertain retrieval needs. To address this limitation, we introduce Diff4Steer, a novel generative retrieval framework that employs lightweight diffusion models to synthesize diverse seed embeddings from user queries that represent potential directions for music exploration. Unlike deterministic methods that map user query to a single point in embedding space, Diff4Steer provides a statistical prior on the target modality (audio) for retrieval, effectively capturing the uncertainty and multi-faceted nature of user preferences. Furthermore, Diff4Steer can be steered by image or text inputs, enabling more flexible and controllable music discovery combined with nearest neighbor search. Our framework outperforms deterministic regression methods and LLM-based generative retrieval baseline in terms of retrieval and ranking metrics, demonstrating its effectiveness in capturing user preferences, leading to more diverse and relevant recommendations. Listening examples are available at tinyurl.com/diff4steer.
PERSOMA: PERsonalized SOft ProMpt Adapter Architecture for Personalized Language Prompting
Aug 02, 2024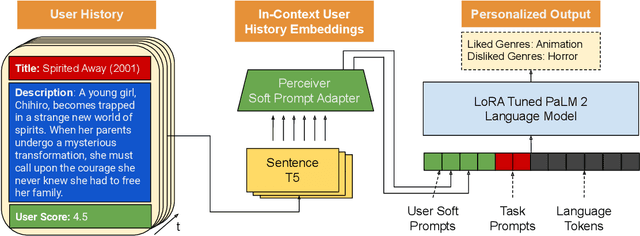



Understanding the nuances of a user's extensive interaction history is key to building accurate and personalized natural language systems that can adapt to evolving user preferences. To address this, we introduce PERSOMA, Personalized Soft Prompt Adapter architecture. Unlike previous personalized prompting methods for large language models, PERSOMA offers a novel approach to efficiently capture user history. It achieves this by resampling and compressing interactions as free form text into expressive soft prompt embeddings, building upon recent research utilizing embedding representations as input for LLMs. We rigorously validate our approach by evaluating various adapter architectures, first-stage sampling strategies, parameter-efficient tuning techniques like LoRA, and other personalization methods. Our results demonstrate PERSOMA's superior ability to handle large and complex user histories compared to existing embedding-based and text-prompt-based techniques.
User Embedding Model for Personalized Language Prompting
Jan 10, 2024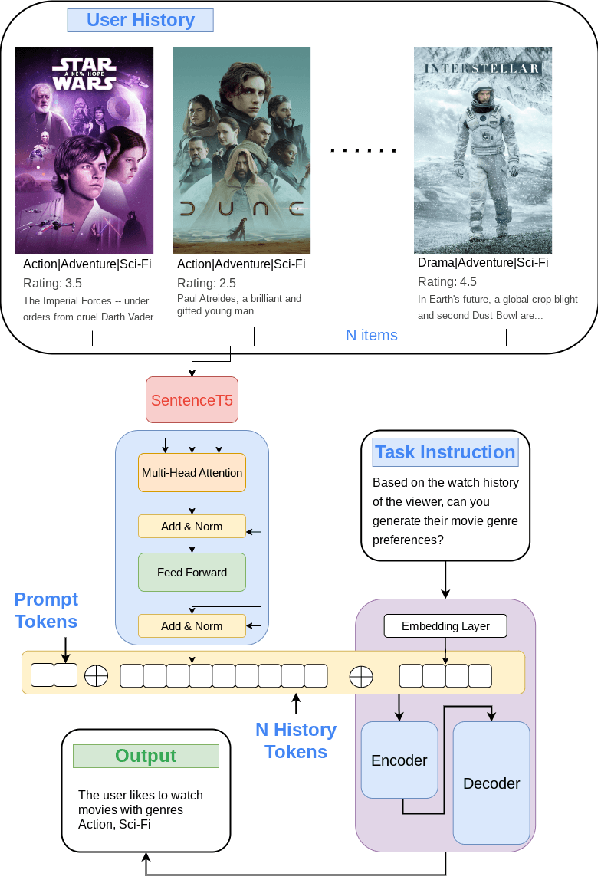

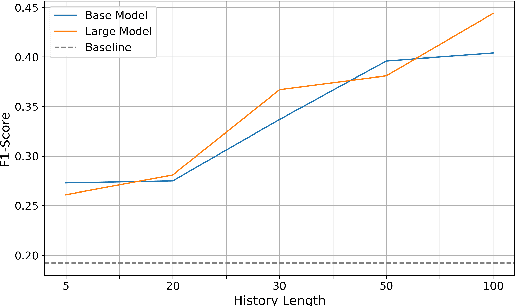

Modeling long histories plays a pivotal role in enhancing recommendation systems, allowing to capture user's evolving preferences, resulting in more precise and personalized recommendations. In this study we tackle the challenges of modeling long user histories for preference understanding in natural language. Specifically, we introduce a new User Embedding Module (UEM) that efficiently processes user history in free-form text by compressing and representing them as embeddings, to use them as soft prompts to a LM. Our experiments demonstrate the superior capability of this approach in handling significantly longer histories compared to conventional text based prompting methods, yielding substantial improvements in predictive performance. The main contribution of this research is to demonstrate the ability to bias language models with user signals represented as embeddings.
V2Meow: Meowing to the Visual Beat via Music Generation
May 11, 2023
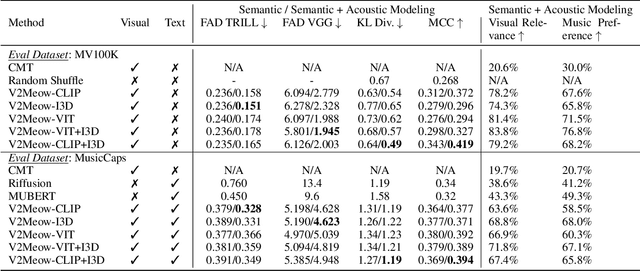

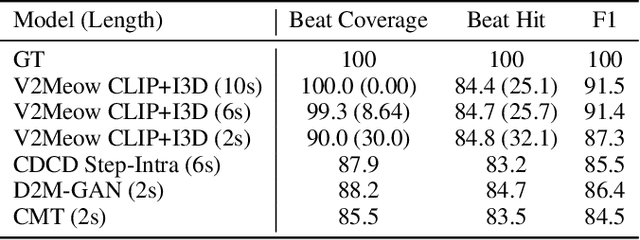
Generating high quality music that complements the visual content of a video is a challenging task. Most existing visual conditioned music generation systems generate symbolic music data, such as MIDI files, instead of raw audio waveform. Given the limited availability of symbolic music data, such methods can only generate music for a few instruments or for specific types of visual input. In this paper, we propose a novel approach called V2Meow that can generate high-quality music audio that aligns well with the visual semantics of a diverse range of video input types. Specifically, the proposed music generation system is a multi-stage autoregressive model which is trained with a number of O(100K) music audio clips paired with video frames, which are mined from in-the-wild music videos, and no parallel symbolic music data is involved. V2Meow is able to synthesize high-fidelity music audio waveform solely conditioned on pre-trained visual features extracted from an arbitrary silent video clip, and it also allows high-level control over the music style of generation examples via supporting text prompts in addition to the video frames conditioning. Through both qualitative and quantitative evaluations, we demonstrate that our model outperforms several existing music generation systems in terms of both visual-audio correspondence and audio quality.
Multi-Task End-to-End Training Improves Conversational Recommendation
May 08, 2023



In this paper, we analyze the performance of a multitask end-to-end transformer model on the task of conversational recommendations, which aim to provide recommendations based on a user's explicit preferences expressed in dialogue. While previous works in this area adopt complex multi-component approaches where the dialogue management and entity recommendation tasks are handled by separate components, we show that a unified transformer model, based on the T5 text-to-text transformer model, can perform competitively in both recommending relevant items and generating conversation dialogue. We fine-tune our model on the ReDIAL conversational movie recommendation dataset, and create additional training tasks derived from MovieLens (such as the prediction of movie attributes and related movies based on an input movie), in a multitask learning setting. Using a series of probe studies, we demonstrate that the learned knowledge in the additional tasks is transferred to the conversational setting, where each task leads to a 9%-52% increase in its related probe score.
MAQA: A Multimodal QA Benchmark for Negation
Jan 09, 2023
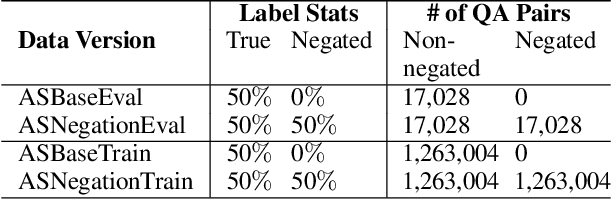
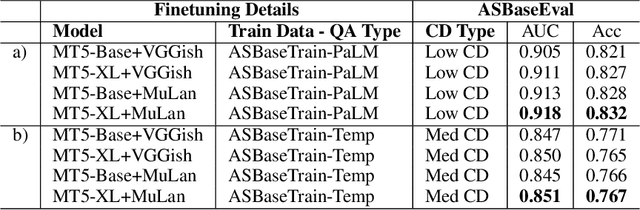
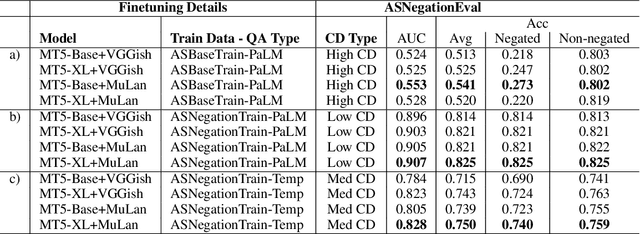
Multimodal learning can benefit from the representation power of pretrained Large Language Models (LLMs). However, state-of-the-art transformer based LLMs often ignore negations in natural language and there is no existing benchmark to quantitatively evaluate whether multimodal transformers inherit this weakness. In this study, we present a new multimodal question answering (QA) benchmark adapted from labeled music videos in AudioSet (Gemmeke et al., 2017) with the goal of systematically evaluating if multimodal transformers can perform complex reasoning to recognize new concepts as negation of previously learned concepts. We show that with standard fine-tuning approach multimodal transformers are still incapable of correctly interpreting negation irrespective of model size. However, our experiments demonstrate that augmenting the original training task distributions with negated QA examples allow the model to reliably reason with negation. To do this, we describe a novel data generation procedure that prompts the 540B-parameter PaLM model to automatically generate negated QA examples as compositions of easily accessible video tags. The generated examples contain more natural linguistic patterns and the gains compared to template-based task augmentation approach are significant.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021
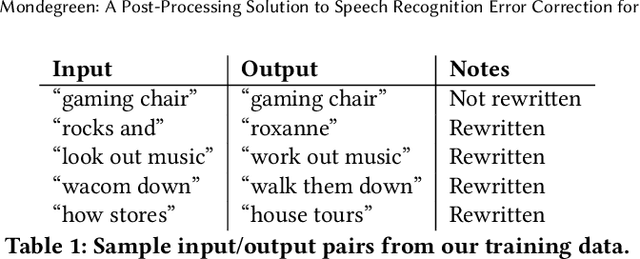


As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
Zero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020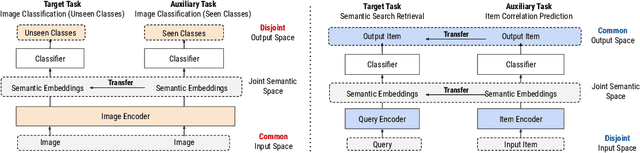

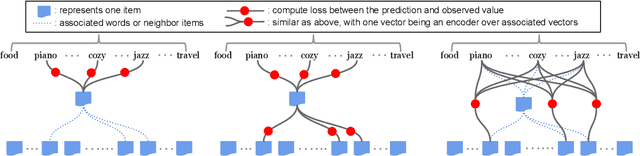
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.
A Bayesian Probability Calculus for Density Matrices
Aug 09, 2014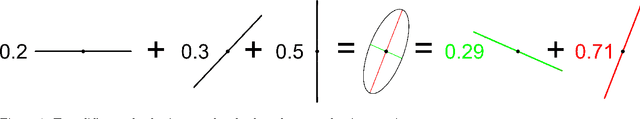
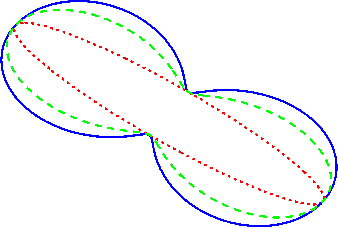
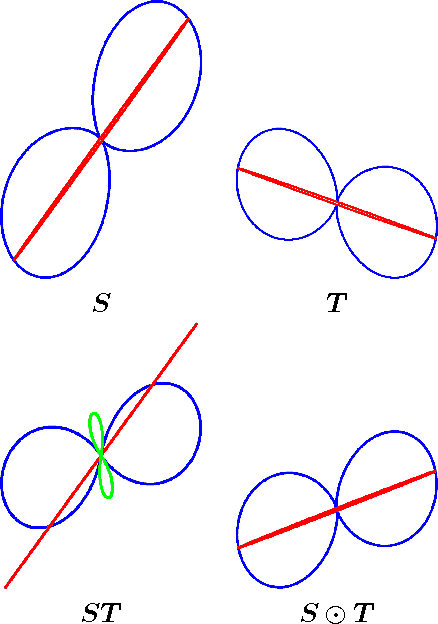
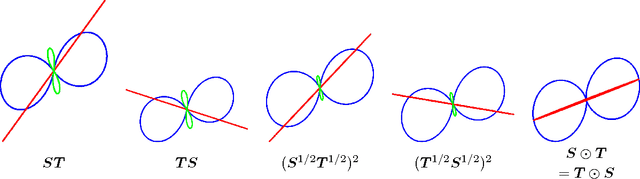
One of the main concepts in quantum physics is a density matrix, which is a symmetric positive definite matrix of trace one. Finite probability distributions are a special case where the density matrix is restricted to be diagonal. Density matrices are mixtures of dyads, where a dyad has the form uu' for any any unit column vector u. These unit vectors are the elementary events of the generalized probability space. Perhaps the simplest case to see that something unusual is going on is the case of uniform density matrix, i.e. 1/n times identity. This matrix assigns probability 1/n to every unit vector, but of course there are infinitely many of them. The new normalization rule thus says that sum of probabilities over any orthonormal basis of directions is one. We develop a probability calculus based on these more general distributions that includes definitions of joints, conditionals and formulas that relate these, i.e. analogs of the theorem of total probability, various Bayes rules for the calculation of posterior density matrices, etc. The resulting calculus parallels the familiar 'classical' probability calculus and always retains the latter as a special case when all matrices are diagonal. Whereas the classical Bayesian methods maintain uncertainty about which model is 'best', the generalization maintains uncertainty about which unit direction has the largest variance. Surprisingly the bounds also generalize: as in the classical setting we bound the negative log likelihood of the data by the negative log likelihood of the MAP estimator.