 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Interpolation for Relative Positions Improves Long Context Transformers
Oct 06, 2023Preventing the performance decay of Transformers on inputs longer than those used for training has been an important challenge in extending the context length of these models. Though the Transformer architecture has fundamentally no limits on the input sequence lengths it can process, the choice of position encoding used during training can limit the performance of these models on longer inputs. We propose a novel functional relative position encoding with progressive interpolation, FIRE, to improve Transformer generalization to longer contexts. We theoretically prove that this can represent some of the popular relative position encodings, such as T5's RPE, Alibi, and Kerple. We next empirically show that FIRE models have better generalization to longer contexts on both zero-shot language modeling and long text benchmarks.
Multi-Task End-to-End Training Improves Conversational Recommendation
May 08, 2023



In this paper, we analyze the performance of a multitask end-to-end transformer model on the task of conversational recommendations, which aim to provide recommendations based on a user's explicit preferences expressed in dialogue. While previous works in this area adopt complex multi-component approaches where the dialogue management and entity recommendation tasks are handled by separate components, we show that a unified transformer model, based on the T5 text-to-text transformer model, can perform competitively in both recommending relevant items and generating conversation dialogue. We fine-tune our model on the ReDIAL conversational movie recommendation dataset, and create additional training tasks derived from MovieLens (such as the prediction of movie attributes and related movies based on an input movie), in a multitask learning setting. Using a series of probe studies, we demonstrate that the learned knowledge in the additional tasks is transferred to the conversational setting, where each task leads to a 9%-52% increase in its related probe score.
LogicInference: A New Dataset for Teaching Logical Inference to seq2seq Models
Apr 11, 2022
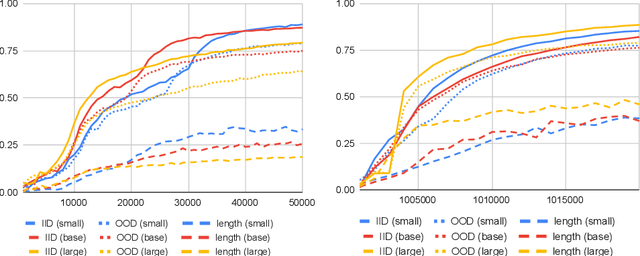
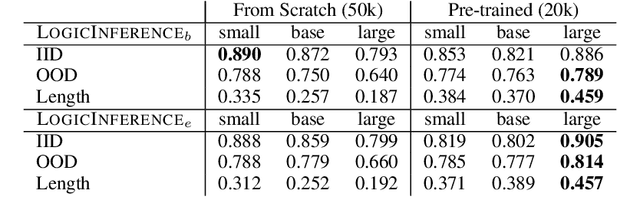
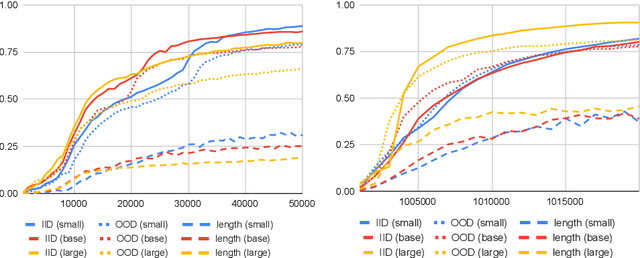
Machine learning models such as Transformers or LSTMs struggle with tasks that are compositional in nature such as those involving reasoning/inference. Although many datasets exist to evaluate compositional generalization, when it comes to evaluating inference abilities, options are more limited. This paper presents LogicInference, a new dataset to evaluate the ability of models to perform logical inference. The dataset focuses on inference using propositional logic and a small subset of first-order logic, represented both in semi-formal logical notation, as well as in natural language. We also report initial results using a collection of machine learning models to establish an initial baseline in this dataset.
LongT5: Efficient Text-To-Text Transformer for Long Sequences
Dec 15, 2021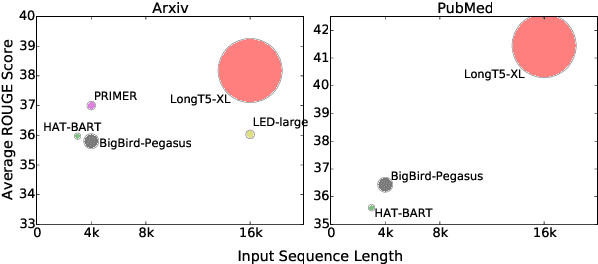
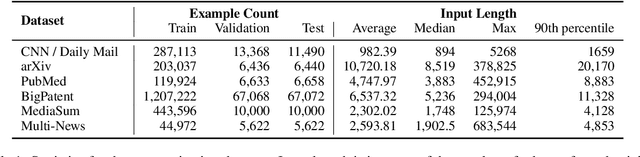
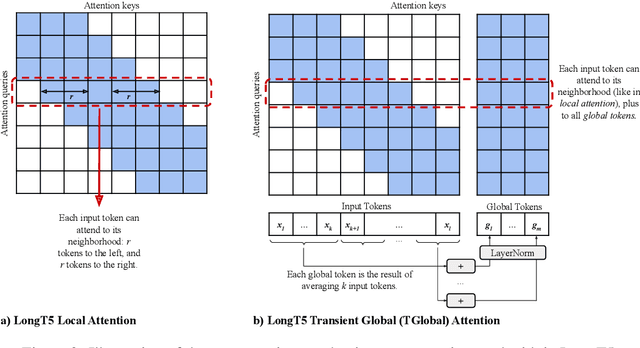
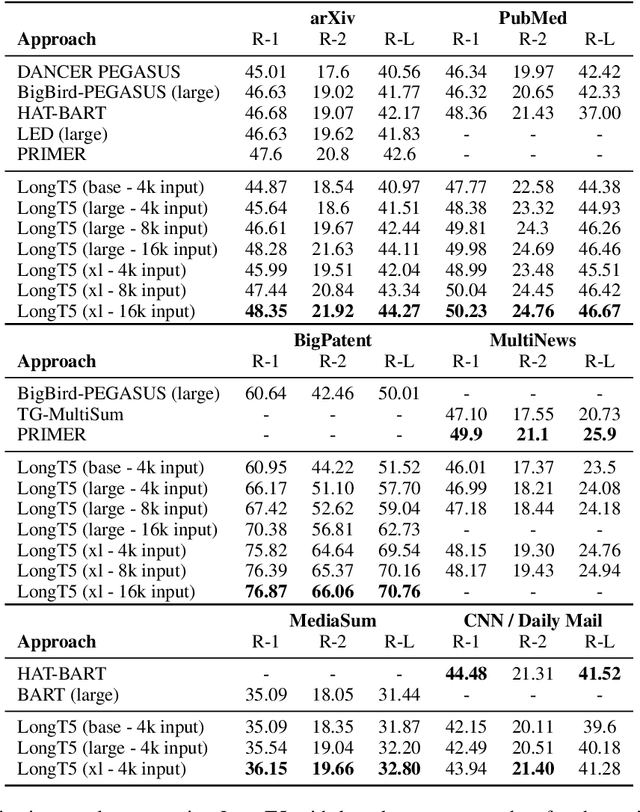
Recent work has shown that either (1) increasing the input length or (2) increasing model size can improve the performance of Transformer-based neural models. In this paper, we present a new model, called LongT5, with which we explore the effects of scaling both the input length and model size at the same time. Specifically, we integrated attention ideas from long-input transformers (ETC), and adopted pre-training strategies from summarization pre-training (PEGASUS) into the scalable T5 architecture. The result is a new attention mechanism we call {\em Transient Global} (TGlobal), which mimics ETC's local/global attention mechanism, but without requiring additional side-inputs. We are able to achieve state-of-the-art results on several summarization tasks and outperform the original T5 models on question answering tasks.
FNet: Mixing Tokens with Fourier Transforms
May 09, 2021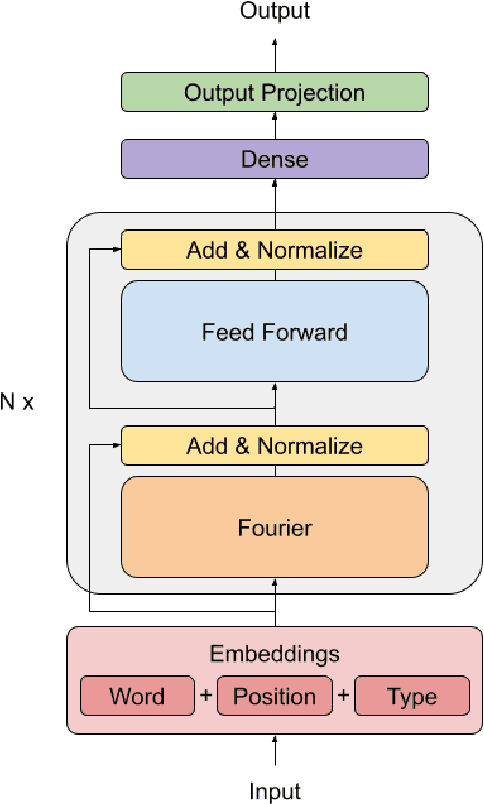

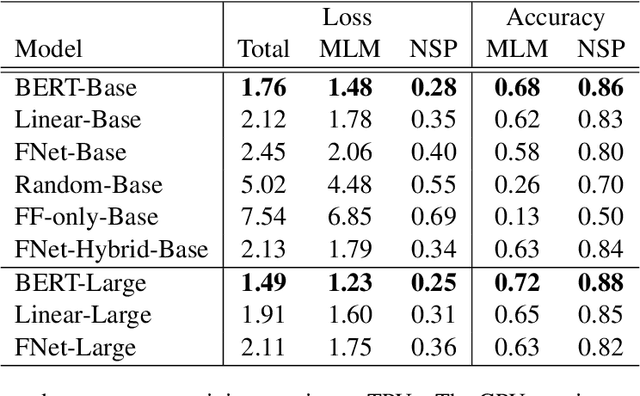
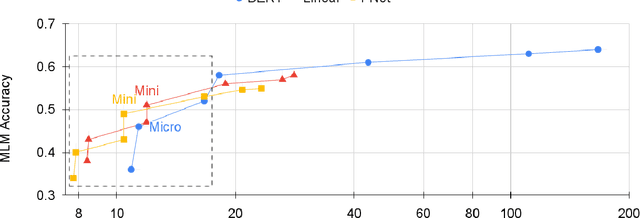
We show that Transformer encoder architectures can be massively sped up, with limited accuracy costs, by replacing the self-attention sublayers with simple linear transformations that "mix" input tokens. These linear transformations, along with simple nonlinearities in feed-forward layers, are sufficient to model semantic relationships in several text classification tasks. Perhaps most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder with a standard, unparameterized Fourier Transform achieves 92% of the accuracy of BERT on the GLUE benchmark, but pre-trains and runs up to seven times faster on GPUs and twice as fast on TPUs. The resulting model, which we name FNet, scales very efficiently to long inputs, matching the accuracy of the most accurate "efficient" Transformers on the Long Range Arena benchmark, but training and running faster across all sequence lengths on GPUs and relatively shorter sequence lengths on TPUs. Finally, FNet has a light memory footprint and is particularly efficient at smaller model sizes: for a fixed speed and accuracy budget, small FNet models outperform Transformer counterparts.
Big Bird: Transformers for Longer Sequences
Jul 28, 2020
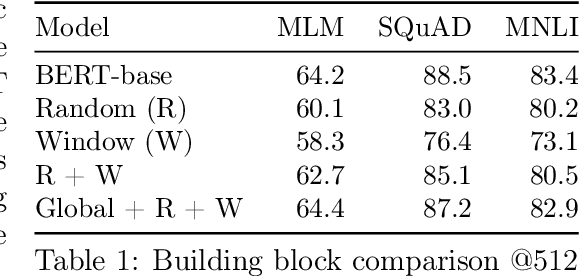

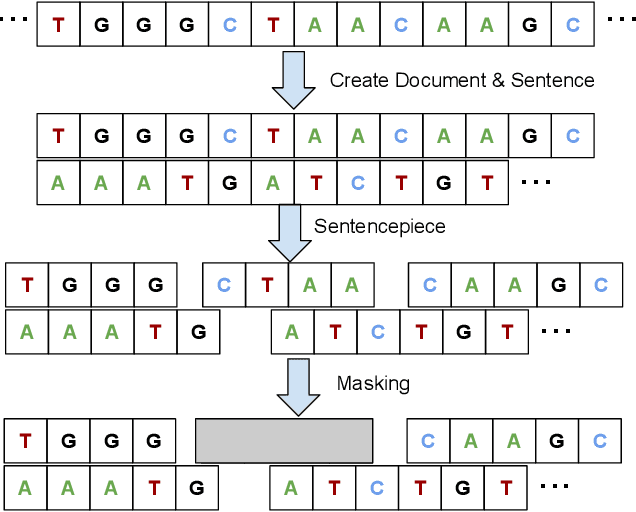
Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having $O(1)$ global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.
ETC: Encoding Long and Structured Data in Transformers
Apr 21, 2020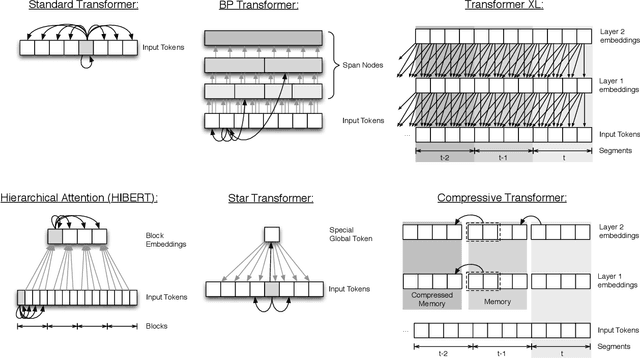
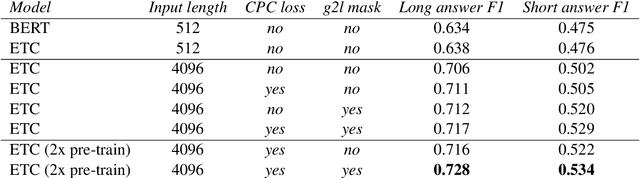
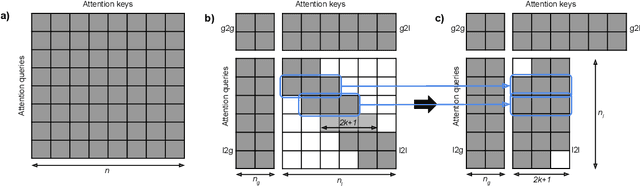
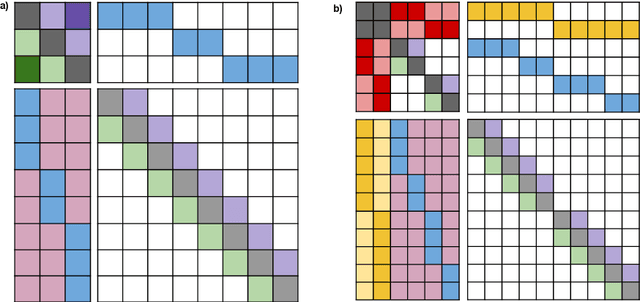
Transformer-based models have pushed the state of the art in many natural language processing tasks. However, one of their main limitations is the quadratic computational and memory cost of the standard attention mechanism. In this paper, we present a new family of Transformer models, which we call the Extended Transformer Construction (ETC), that allows for significant increases in input sequence length by introducing a new global-local attention mechanism between a global memory and the standard input tokens. We also show that combining global-local attention with relative position encodings allows ETC to handle structured data with ease. Empirical results on the Natural Questions data set show the promise of the approach.
A semantic network-based evolutionary algorithm for computational creativity
Jul 14, 2014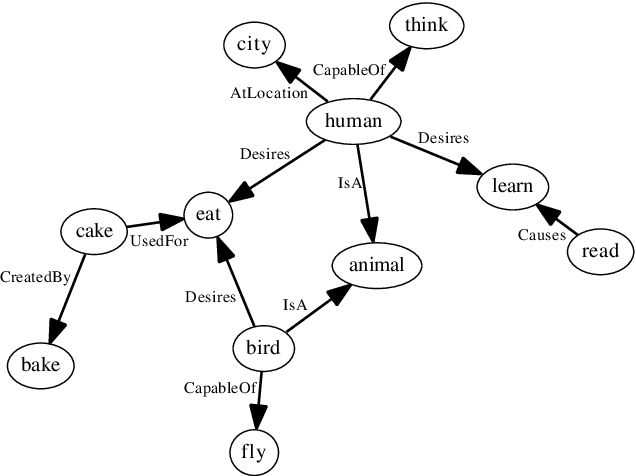

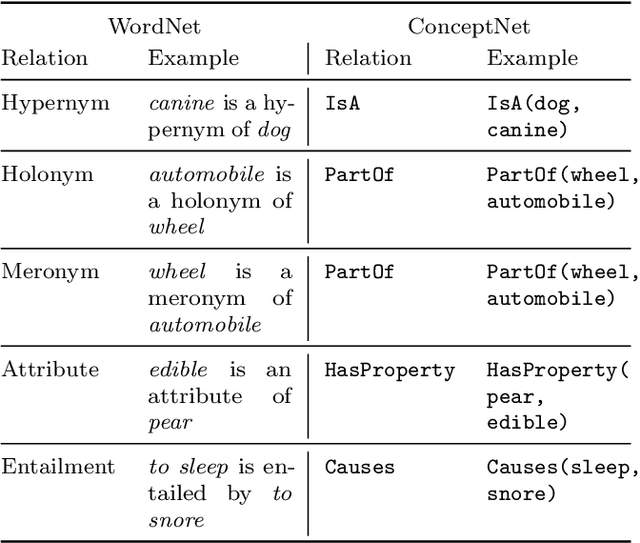
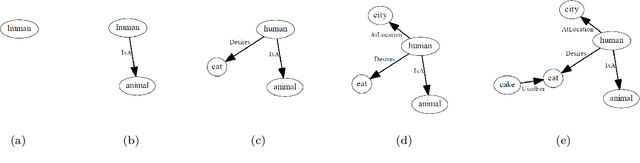
We introduce a novel evolutionary algorithm (EA) with a semantic network-based representation. For enabling this, we establish new formulations of EA variation operators, crossover and mutation, that we adapt to work on semantic networks. The algorithm employs commonsense reasoning to ensure all operations preserve the meaningfulness of the networks, using ConceptNet and WordNet knowledge bases. The algorithm can be interpreted as a novel memetic algorithm (MA), given that (1) individuals represent pieces of information that undergo evolution, as in the original sense of memetics as it was introduced by Dawkins; and (2) this is different from existing MA, where the word "memetic" has been used as a synonym for local refinement after global optimization. For evaluating the approach, we introduce an analogical similarity-based fitness measure that is computed through structure mapping. This setup enables the open-ended generation of networks analogous to a given base network.
* 20 pages, 14 figures, revision after reviews, changed title
Experiments with Game Tree Search in Real-Time Strategy Games
Aug 09, 2012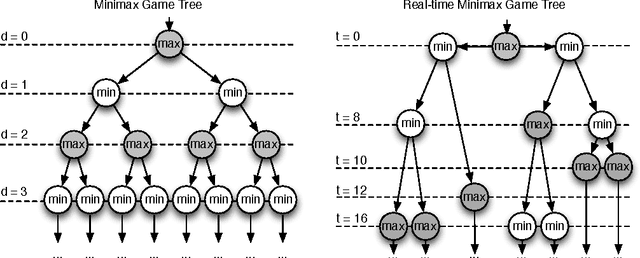
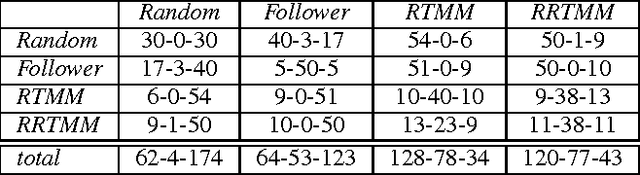
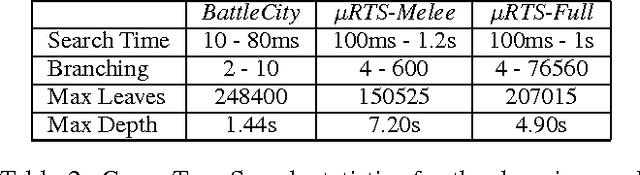

Game tree search algorithms such as minimax have been used with enormous success in turn-based adversarial games such as Chess or Checkers. However, such algorithms cannot be directly applied to real-time strategy (RTS) games because a number of reasons. For example, minimax assumes a turn-taking game mechanics, not present in RTS games. In this paper we present RTMM, a real-time variant of the standard minimax algorithm, and discuss its applicability in the context of RTS games. We discuss its strengths and weaknesses, and evaluate it in two real-time games.
Automated Generation of Cross-Domain Analogies via Evolutionary Computation
Apr 11, 2012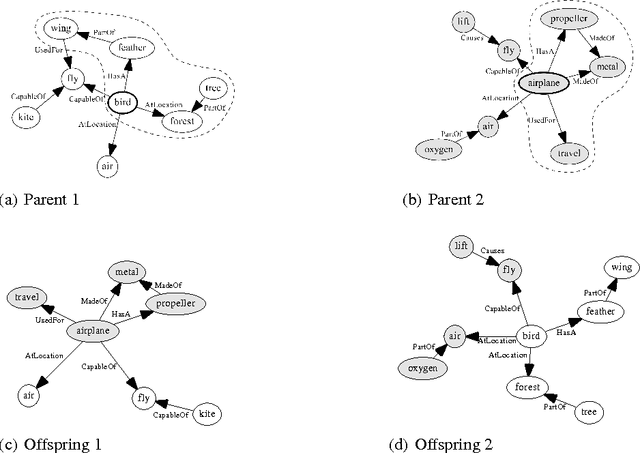

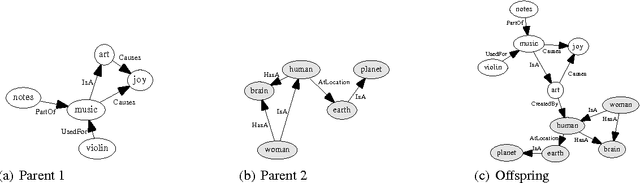
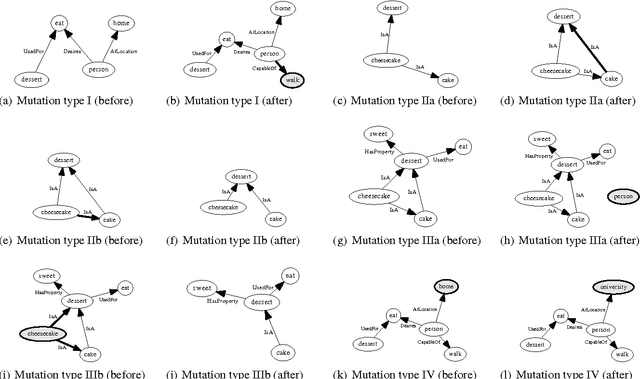
Analogy plays an important role in creativity, and is extensively used in science as well as art. In this paper we introduce a technique for the automated generation of cross-domain analogies based on a novel evolutionary algorithm (EA). Unlike existing work in computational analogy-making restricted to creating analogies between two given cases, our approach, for a given case, is capable of creating an analogy along with the novel analogous case itself. Our algorithm is based on the concept of "memes", which are units of culture, or knowledge, undergoing variation and selection under a fitness measure, and represents evolving pieces of knowledge as semantic networks. Using a fitness function based on Gentner's structure mapping theory of analogies, we demonstrate the feasibility of spontaneously generating semantic networks that are analogous to a given base network.
* Conference submission, International Conference on Computational Creativity 2012 (8 pages, 6 figures)