Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETC: Encoding Long and Structured Data in Transformers
Paper and Code
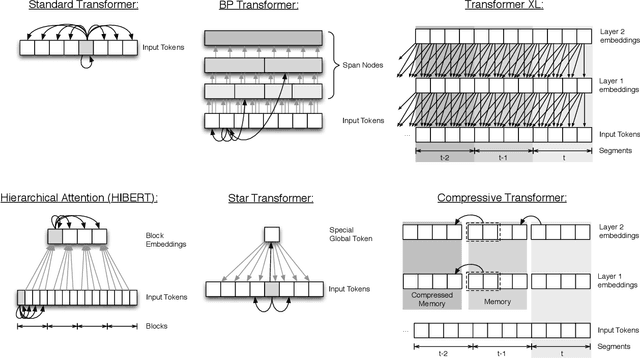
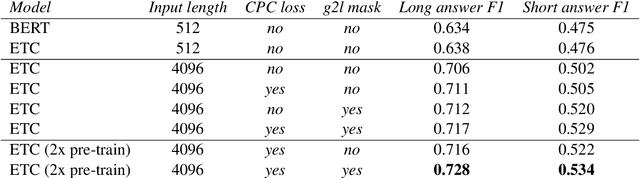
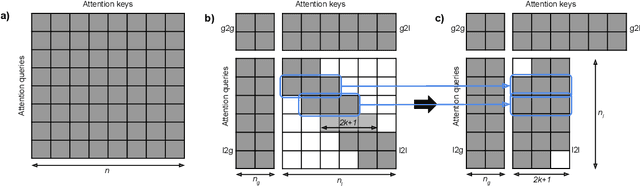
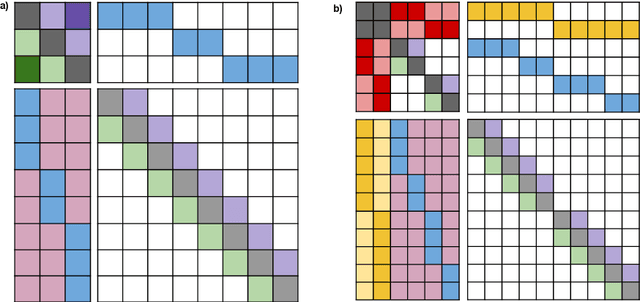
Transformer-based models have pushed the state of the art in many natural language processing tasks. However, one of their main limitations is the quadratic computational and memory cost of the standard attention mechanism. In this paper, we present a new family of Transformer models, which we call the Extended Transformer Construction (ETC), that allows for significant increases in input sequence length by introducing a new global-local attention mechanism between a global memory and the standard input tokens. We also show that combining global-local attention with relative position encodings allows ETC to handle structured data with ease. Empirical results on the Natural Questions data set show the promise of the approach.
* Updated ETC 512 results which mistakenly used a stale input format.
Paper has not been peer-reviewed. An extended version will be submitted for
review in the future
View paper on