 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContracting with a Learning Agent
Jan 29, 2024Many real-life contractual relations differ completely from the clean, static model at the heart of principal-agent theory. Typically, they involve repeated strategic interactions of the principal and agent, taking place under uncertainty and over time. While appealing in theory, players seldom use complex dynamic strategies in practice, often preferring to circumvent complexity and approach uncertainty through learning. We initiate the study of repeated contracts with a learning agent, focusing on agents who achieve no-regret outcomes. Optimizing against a no-regret agent is a known open problem in general games; we achieve an optimal solution to this problem for a canonical contract setting, in which the agent's choice among multiple actions leads to success/failure. The solution has a surprisingly simple structure: for some $\alpha > 0$, initially offer the agent a linear contract with scalar $\alpha$, then switch to offering a linear contract with scalar $0$. This switch causes the agent to ``free-fall'' through their action space and during this time provides the principal with non-zero reward at zero cost. Despite apparent exploitation of the agent, this dynamic contract can leave \emph{both} players better off compared to the best static contract. Our results generalize beyond success/failure, to arbitrary non-linear contracts which the principal rescales dynamically. Finally, we quantify the dependence of our results on knowledge of the time horizon, and are the first to address this consideration in the study of strategizing against learning agents.
Functional Interpolation for Relative Positions Improves Long Context Transformers
Oct 06, 2023Preventing the performance decay of Transformers on inputs longer than those used for training has been an important challenge in extending the context length of these models. Though the Transformer architecture has fundamentally no limits on the input sequence lengths it can process, the choice of position encoding used during training can limit the performance of these models on longer inputs. We propose a novel functional relative position encoding with progressive interpolation, FIRE, to improve Transformer generalization to longer contexts. We theoretically prove that this can represent some of the popular relative position encodings, such as T5's RPE, Alibi, and Kerple. We next empirically show that FIRE models have better generalization to longer contexts on both zero-shot language modeling and long text benchmarks.
A Fourier Approach to Mixture Learning
Oct 06, 2022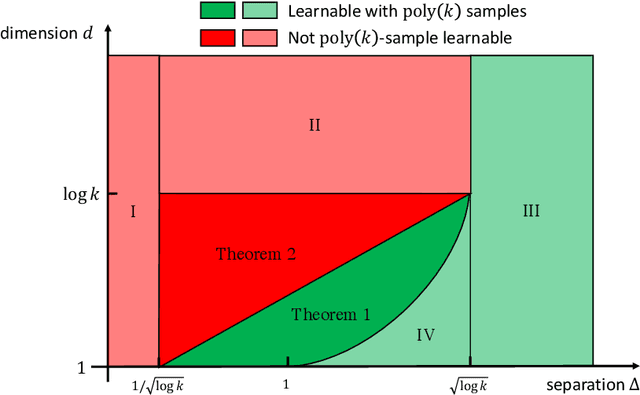

We revisit the problem of learning mixtures of spherical Gaussians. Given samples from mixture $\frac{1}{k}\sum_{j=1}^{k}\mathcal{N}(\mu_j, I_d)$, the goal is to estimate the means $\mu_1, \mu_2, \ldots, \mu_k \in \mathbb{R}^d$ up to a small error. The hardness of this learning problem can be measured by the separation $\Delta$ defined as the minimum distance between all pairs of means. Regev and Vijayaraghavan (2017) showed that with $\Delta = \Omega(\sqrt{\log k})$ separation, the means can be learned using $\mathrm{poly}(k, d)$ samples, whereas super-polynomially many samples are required if $\Delta = o(\sqrt{\log k})$ and $d = \Omega(\log k)$. This leaves open the low-dimensional regime where $d = o(\log k)$. In this work, we give an algorithm that efficiently learns the means in $d = O(\log k/\log\log k)$ dimensions under separation $d/\sqrt{\log k}$ (modulo doubly logarithmic factors). This separation is strictly smaller than $\sqrt{\log k}$, and is also shown to be necessary. Along with the results of Regev and Vijayaraghavan (2017), our work almost pins down the critical separation threshold at which efficient parameter learning becomes possible for spherical Gaussian mixtures. More generally, our algorithm runs in time $\mathrm{poly}(k)\cdot f(d, \Delta, \epsilon)$, and is thus fixed-parameter tractable in parameters $d$, $\Delta$ and $\epsilon$. Our approach is based on estimating the Fourier transform of the mixture at carefully chosen frequencies, and both the algorithm and its analysis are simple and elementary. Our positive results can be easily extended to learning mixtures of non-Gaussian distributions, under a mild condition on the Fourier spectrum of the distribution.
Margin-Independent Online Multiclass Learning via Convex Geometry
Nov 15, 2021
We consider the problem of multi-class classification, where a stream of adversarially chosen queries arrive and must be assigned a label online. Unlike traditional bounds which seek to minimize the misclassification rate, we minimize the total distance from each query to the region corresponding to its correct label. When the true labels are determined via a nearest neighbor partition -- i.e. the label of a point is given by which of $k$ centers it is closest to in Euclidean distance -- we show that one can achieve a loss that is independent of the total number of queries. We complement this result by showing that learning general convex sets requires an almost linear loss per query. Our results build off of regret guarantees for the geometric problem of contextual search. In addition, we develop a novel reduction technique from multiclass classification to binary classification which may be of independent interest.
Learning to Bid in Contextual First Price Auctions
Sep 07, 2021In this paper, we investigate the problem about how to bid in repeated contextual first price auctions. We consider a single bidder (learner) who repeatedly bids in the first price auctions: at each time $t$, the learner observes a context $x_t\in \mathbb{R}^d$ and decides the bid based on historical information and $x_t$. We assume a structured linear model of the maximum bid of all the others $m_t = \alpha_0\cdot x_t + z_t$, where $\alpha_0\in \mathbb{R}^d$ is unknown to the learner and $z_t$ is randomly sampled from a noise distribution $\mathcal{F}$ with log-concave density function $f$. We consider both \emph{binary feedback} (the learner can only observe whether she wins or not) and \emph{full information feedback} (the learner can observe $m_t$) at the end of each time $t$. For binary feedback, when the noise distribution $\mathcal{F}$ is known, we propose a bidding algorithm, by using maximum likelihood estimation (MLE) method to achieve at most $\widetilde{O}(\sqrt{\log(d) T})$ regret. Moreover, we generalize this algorithm to the setting with binary feedback and the noise distribution is unknown but belongs to a parametrized family of distributions. For the full information feedback with \emph{unknown} noise distribution, we provide an algorithm that achieves regret at most $\widetilde{O}(\sqrt{dT})$. Our approach combines an estimator for log-concave density functions and then MLE method to learn the noise distribution $\mathcal{F}$ and linear weight $\alpha_0$ simultaneously. We also provide a lower bound result such that any bidding policy in a broad class must achieve regret at least $\Omega(\sqrt{T})$, even when the learner receives the full information feedback and $\mathcal{F}$ is known.
Contextual Recommendations and Low-Regret Cutting-Plane Algorithms
Jun 09, 2021We consider the following variant of contextual linear bandits motivated by routing applications in navigational engines and recommendation systems. We wish to learn a hidden $d$-dimensional value $w^*$. Every round, we are presented with a subset $\mathcal{X}_t \subseteq \mathbb{R}^d$ of possible actions. If we choose (i.e. recommend to the user) action $x_t$, we obtain utility $\langle x_t, w^* \rangle$ but only learn the identity of the best action $\arg\max_{x \in \mathcal{X}_t} \langle x, w^* \rangle$. We design algorithms for this problem which achieve regret $O(d\log T)$ and $\exp(O(d \log d))$. To accomplish this, we design novel cutting-plane algorithms with low "regret" -- the total distance between the true point $w^*$ and the hyperplanes the separation oracle returns. We also consider the variant where we are allowed to provide a list of several recommendations. In this variant, we give an algorithm with $O(d^2 \log d)$ regret and list size $\mathrm{poly}(d)$. Finally, we construct nearly tight algorithms for a weaker variant of this problem where the learner only learns the identity of an action that is better than the recommendation. Our results rely on new algorithmic techniques in convex geometry (including a variant of Steiner's formula for the centroid of a convex set) which may be of independent interest.
Scalable Bottom-Up Hierarchical Clustering
Nov 04, 2020
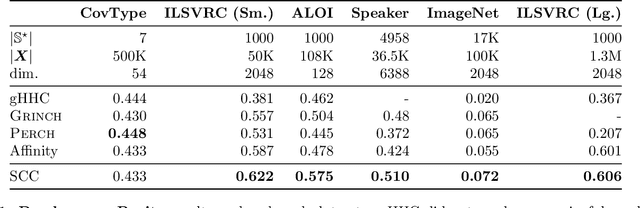

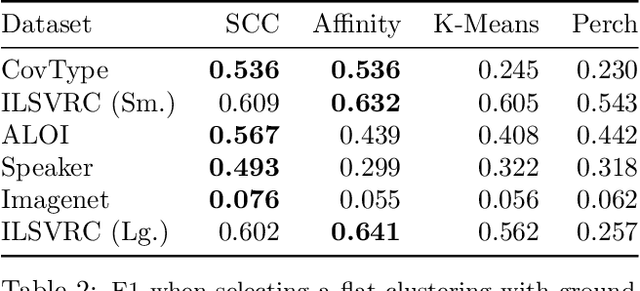
Bottom-up algorithms such as the classic hierarchical agglomerative clustering, are highly effective for hierarchical as well as flat clustering. However, the large number of rounds and their sequential nature limit the scalability of agglomerative clustering. In this paper, we present an alternative round-based bottom-up hierarchical clustering, the Sub-Cluster Component Algorithm (SCC), that scales gracefully to massive datasets. Our method builds many sub-clusters in parallel in a given round and requires many fewer rounds -- usually an order of magnitude smaller than classic agglomerative clustering. Our theoretical analysis shows that, under a modest separability assumption, SCC will contain the optimal flat clustering. SCC also provides a 2-approx solution to the DP-means objective, thereby introducing a novel application of hierarchical clustering methods. Empirically, SCC finds better hierarchies and flat clusterings even when the data does not satisfy the separability assumption. We demonstrate the scalability of our method by applying it to a dataset of 30 billion points and showing that SCC produces higher quality clusterings than the state-of-the-art.
Big Bird: Transformers for Longer Sequences
Jul 28, 2020
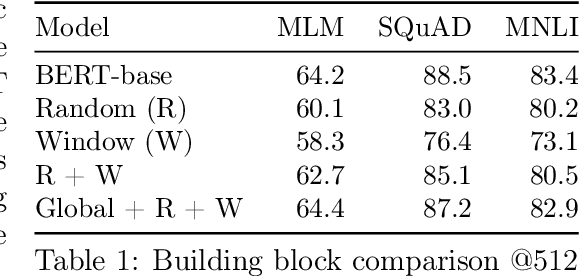

Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having $O(1)$ global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.