 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Unlearning Using Conformal Prediction
Feb 03, 2026Machine unlearning is the process of efficiently removing specific information from a trained machine learning model without retraining from scratch. Existing unlearning methods, which often provide provable guarantees, typically involve retraining a subset of model parameters based on a forget set. While these approaches show promise in certain scenarios, their underlying assumptions are often challenged in real-world applications -- particularly when applied to generative models. Furthermore, updating parameters using these unlearning procedures often degrades the general-purpose capabilities the model acquired during pre-training. Motivated by these shortcomings, this paper considers the paradigm of inference time unlearning -- wherein, the generative model is equipped with an (approximately correct) verifier that judges whether the model's response satisfies appropriate unlearning guarantees. This paper introduces a framework that iteratively refines the quality of the generated responses using feedback from the verifier without updating the model parameters. The proposed framework leverages conformal prediction to reduce computational overhead and provide distribution-free unlearning guarantees. This paper's approach significantly outperforms existing state-of-the-art methods, reducing unlearning error by up to 93% across challenging unlearning benchmarks.
Fundamental Limits of Perfect Concept Erasure
Mar 25, 2025Concept erasure is the task of erasing information about a concept (e.g., gender or race) from a representation set while retaining the maximum possible utility -- information from original representations. Concept erasure is useful in several applications, such as removing sensitive concepts to achieve fairness and interpreting the impact of specific concepts on a model's performance. Previous concept erasure techniques have prioritized robustly erasing concepts over retaining the utility of the resultant representations. However, there seems to be an inherent tradeoff between erasure and retaining utility, making it unclear how to achieve perfect concept erasure while maintaining high utility. In this paper, we offer a fresh perspective toward solving this problem by quantifying the fundamental limits of concept erasure through an information-theoretic lens. Using these results, we investigate constraints on the data distribution and the erasure functions required to achieve the limits of perfect concept erasure. Empirically, we show that the derived erasure functions achieve the optimal theoretical bounds. Additionally, we show that our approach outperforms existing methods on a range of synthetic and real-world datasets using GPT-4 representations.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024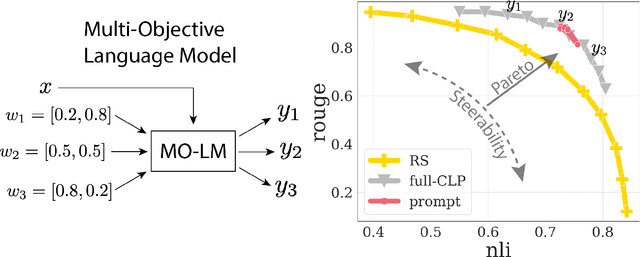
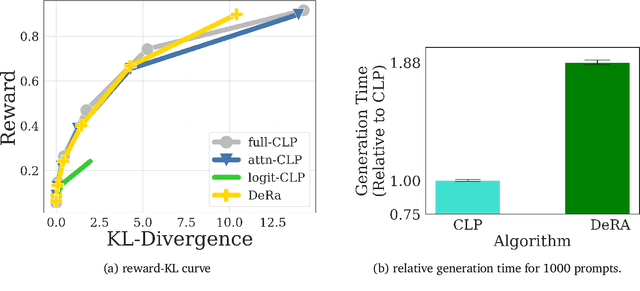
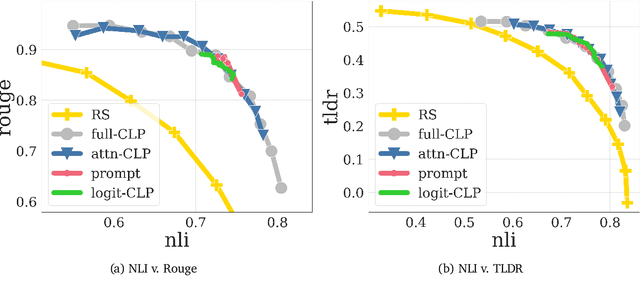
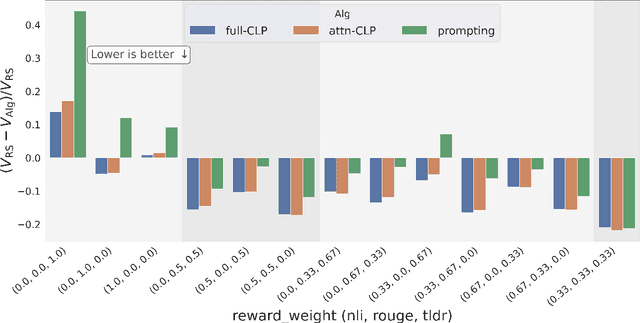
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Incremental Extractive Opinion Summarization Using Cover Trees
Jan 16, 2024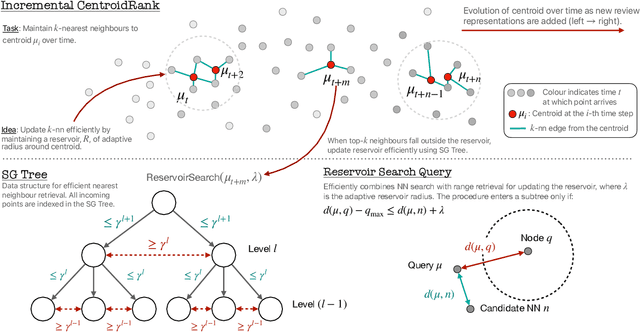
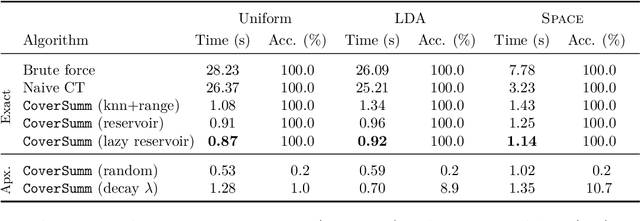
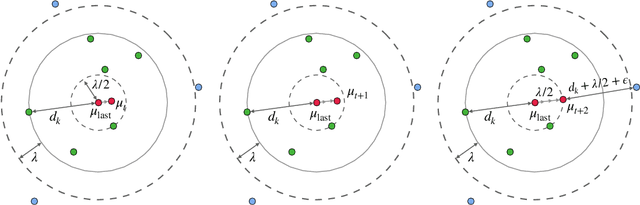
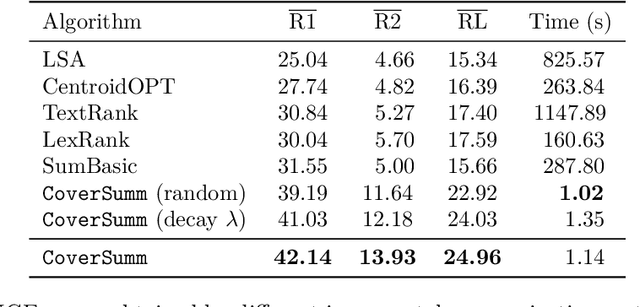
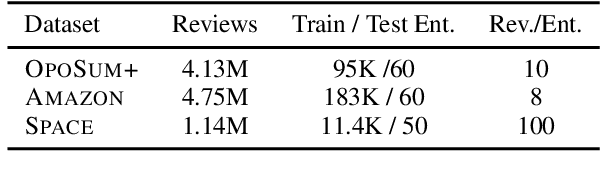
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accrue over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank. CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 25x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.
Robust Concept Erasure via Kernelized Rate-Distortion Maximization
Nov 30, 2023Distributed representations provide a vector space that captures meaningful relationships between data instances. The distributed nature of these representations, however, entangles together multiple attributes or concepts of data instances (e.g., the topic or sentiment of a text, characteristics of the author (age, gender, etc), etc). Recent work has proposed the task of concept erasure, in which rather than making a concept predictable, the goal is to remove an attribute from distributed representations while retaining other information from the original representation space as much as possible. In this paper, we propose a new distance metric learning-based objective, the Kernelized Rate-Distortion Maximizer (KRaM), for performing concept erasure. KRaM fits a transformation of representations to match a specified distance measure (defined by a labeled concept to erase) using a modified rate-distortion function. Specifically, KRaM's objective function aims to make instances with similar concept labels dissimilar in the learned representation space while retaining other information. We find that optimizing KRaM effectively erases various types of concepts: categorical, continuous, and vector-valued variables from data representations across diverse domains. We also provide a theoretical analysis of several properties of KRaM's objective. To assess the quality of the learned representations, we propose an alignment score to evaluate their similarity with the original representation space. Additionally, we conduct experiments to showcase KRaM's efficacy in various settings, from erasing binary gender variables in word embeddings to vector-valued variables in GPT-3 representations.
Enhancing Group Fairness in Online Settings Using Oblique Decision Forests
Oct 17, 2023Fairness, especially group fairness, is an important consideration in the context of machine learning systems. The most commonly adopted group fairness-enhancing techniques are in-processing methods that rely on a mixture of a fairness objective (e.g., demographic parity) and a task-specific objective (e.g., cross-entropy) during the training process. However, when data arrives in an online fashion -- one instance at a time -- optimizing such fairness objectives poses several challenges. In particular, group fairness objectives are defined using expectations of predictions across different demographic groups. In the online setting, where the algorithm has access to a single instance at a time, estimating the group fairness objective requires additional storage and significantly more computation (e.g., forward/backward passes) than the task-specific objective at every time step. In this paper, we propose Aranyani, an ensemble of oblique decision trees, to make fair decisions in online settings. The hierarchical tree structure of Aranyani enables parameter isolation and allows us to efficiently compute the fairness gradients using aggregate statistics of previous decisions, eliminating the need for additional storage and forward/backward passes. We also present an efficient framework to train Aranyani and theoretically analyze several of its properties. We conduct empirical evaluations on 5 publicly available benchmarks (including vision and language datasets) to show that Aranyani achieves a better accuracy-fairness trade-off compared to baseline approaches.
Unsupervised Opinion Summarization Using Approximate Geodesics
Sep 15, 2022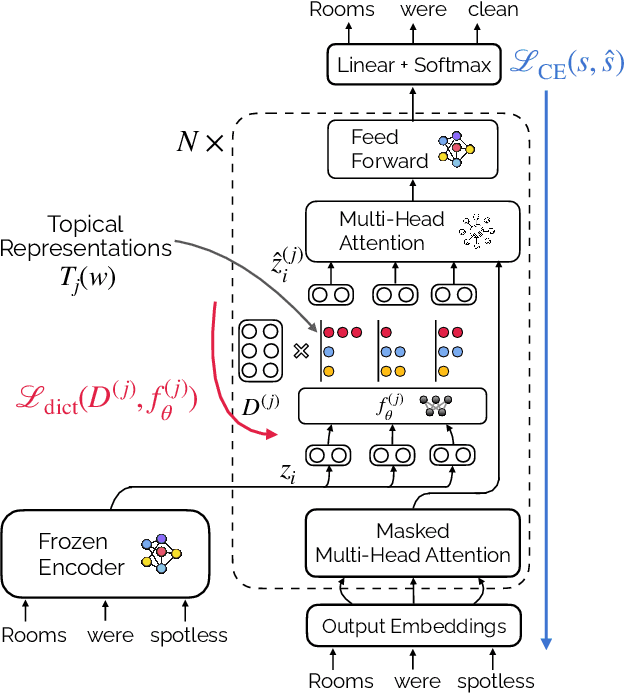


Opinion summarization is the task of creating summaries capturing popular opinions from user reviews. In this paper, we introduce Geodesic Summarizer (GeoSumm), a novel system to perform unsupervised extractive opinion summarization. GeoSumm involves an encoder-decoder based representation learning model, that generates representations of text as a distribution over latent semantic units. GeoSumm generates these representations by performing dictionary learning over pre-trained text representations at multiple decoder layers. We then use these representations to quantify the relevance of review sentences using a novel approximate geodesic distance based scoring mechanism. We use the relevance scores to identify popular opinions in order to compose general and aspect-specific summaries. Our proposed model, GeoSumm, achieves state-of-the-art performance on three opinion summarization datasets. We perform additional experiments to analyze the functioning of our model and showcase the generalization ability of {\X} across different domains.
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022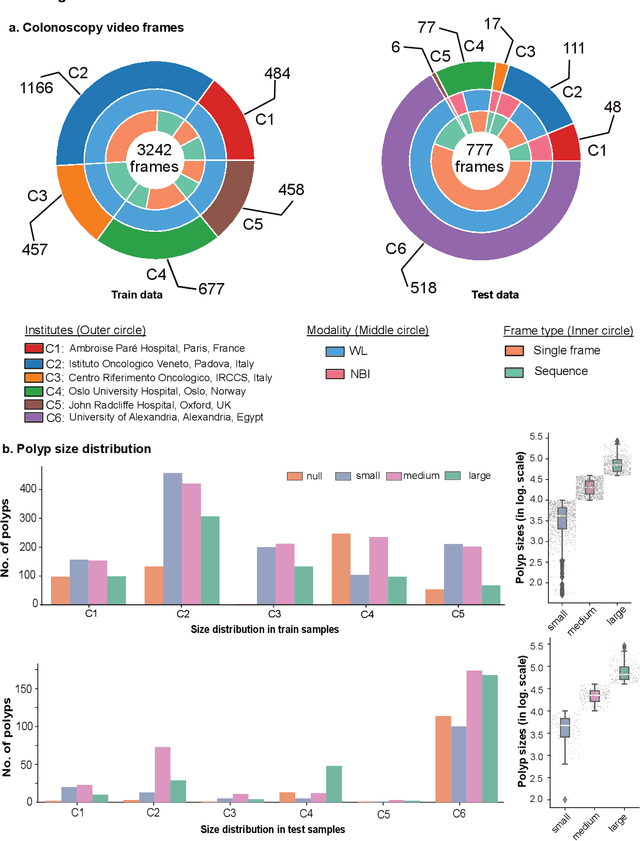
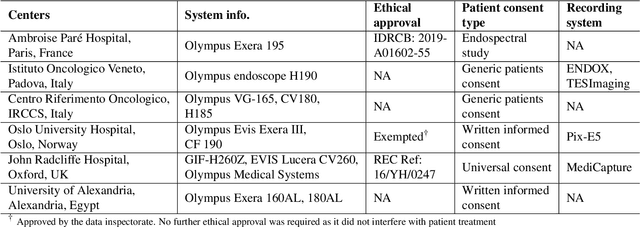
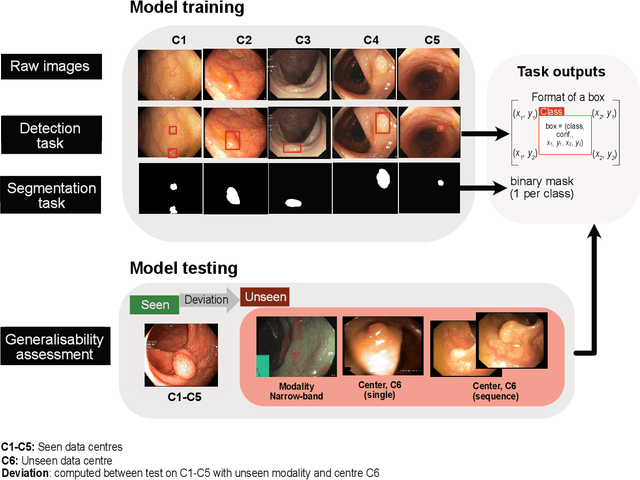
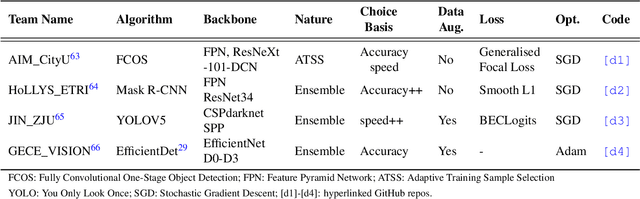
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.
When in Doubt, Summon the Titans: Efficient Inference with Large Models
Oct 19, 2021

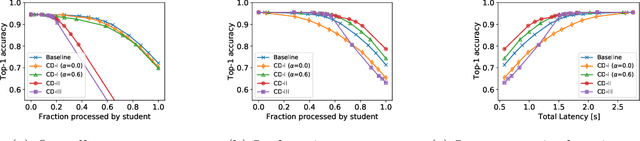

Scaling neural networks to "large" sizes, with billions of parameters, has been shown to yield impressive results on many challenging problems. However, the inference cost incurred by such large models often prevents their application in most real-world settings. In this paper, we propose a two-stage framework based on distillation that realizes the modelling benefits of the large models, while largely preserving the computational benefits of inference with more lightweight models. In a nutshell, we use the large teacher models to guide the lightweight student models to only make correct predictions on a subset of "easy" examples; for the "hard" examples, we fall-back to the teacher. Such an approach allows us to efficiently employ large models in practical scenarios where easy examples are much more frequent than rare hard examples. Our proposed use of distillation to only handle easy instances allows for a more aggressive trade-off in the student size, thereby reducing the amortized cost of inference and achieving better accuracy than standard distillation. Empirically, we demonstrate the benefits of our approach on both image classification and natural language processing benchmarks.