 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Deep Convolutional Inverse Graphics Network
Jun 22, 2015
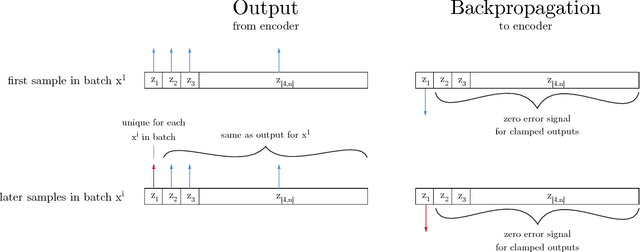

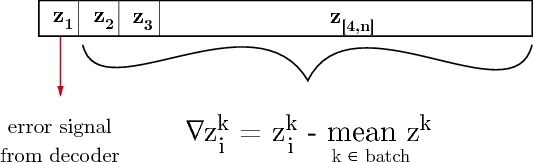
This paper presents the Deep Convolution Inverse Graphics Network (DC-IGN), a model that learns an interpretable representation of images. This representation is disentangled with respect to transformations such as out-of-plane rotations and lighting variations. The DC-IGN model is composed of multiple layers of convolution and de-convolution operators and is trained using the Stochastic Gradient Variational Bayes (SGVB) algorithm. We propose a training procedure to encourage neurons in the graphics code layer to represent a specific transformation (e.g. pose or light). Given a single input image, our model can generate new images of the same object with variations in pose and lighting. We present qualitative and quantitative results of the model's efficacy at learning a 3D rendering engine.