 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Auctions with LLM Summaries
Apr 11, 2024We study an auction setting in which bidders bid for placement of their content within a summary generated by a large language model (LLM), e.g., an ad auction in which the display is a summary paragraph of multiple ads. This generalizes the classic ad settings such as position auctions to an LLM generated setting, which allows us to handle general display formats. We propose a novel factorized framework in which an auction module and an LLM module work together via a prediction model to provide welfare maximizing summary outputs in an incentive compatible manner. We provide a theoretical analysis of this framework and synthetic experiments to demonstrate the feasibility and validity of the system together with welfare comparisons.
Learning a Fourier Transform for Linear Relative Positional Encodings in Transformers
Feb 03, 2023



We propose a new class of linear Transformers called FourierLearner-Transformers (FLTs), which incorporate a wide range of relative positional encoding mechanisms (RPEs). These include regular RPE techniques applied for nongeometric data, as well as novel RPEs operating on the sequences of tokens embedded in higher-dimensional Euclidean spaces (e.g. point clouds). FLTs construct the optimal RPE mechanism implicitly by learning its spectral representation. As opposed to other architectures combining efficient low-rank linear attention with RPEs, FLTs remain practical in terms of their memory usage and do not require additional assumptions about the structure of the RPE-mask. FLTs allow also for applying certain structural inductive bias techniques to specify masking strategies, e.g. they provide a way to learn the so-called local RPEs introduced in this paper and providing accuracy gains as compared with several other linear Transformers for language modeling. We also thoroughly tested FLTs on other data modalities and tasks, such as: image classification and 3D molecular modeling. For 3D-data FLTs are, to the best of our knowledge, the first Transformers architectures providing RPE-enhanced linear attention.
Discourse in Multimedia: A Case Study in Information Extraction
Nov 13, 2018
To ensure readability, text is often written and presented with due formatting. These text formatting devices help the writer to effectively convey the narrative. At the same time, these help the readers pick up the structure of the discourse and comprehend the conveyed information. There have been a number of linguistic theories on discourse structure of text. However, these theories only consider unformatted text. Multimedia text contains rich formatting features which can be leveraged for various NLP tasks. In this paper, we study some of these discourse features in multimedia text and what communicative function they fulfil in the context. We examine how these multimedia discourse features can be used to improve an information extraction system. We show that the discourse and text layout features provide information that is complementary to lexical semantic information commonly used for information extraction. As a case study, we use these features to harvest structured subject knowledge of geometry from textbooks. We show that the harvested structured knowledge can be used to improve an existing solver for geometry problems, making it more accurate as well as more explainable.
Recurrent Estimation of Distributions
May 30, 2017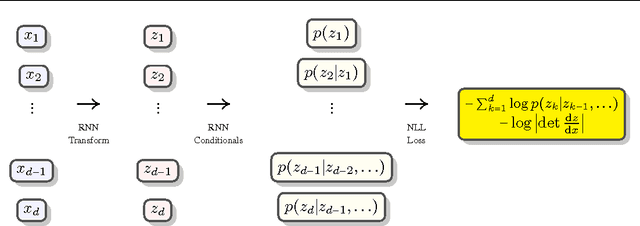
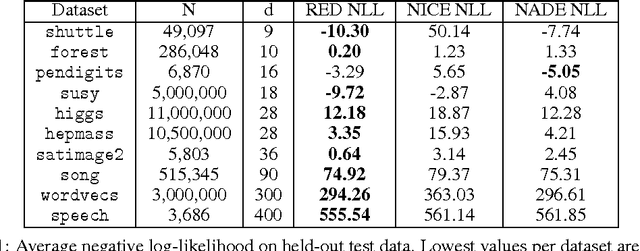
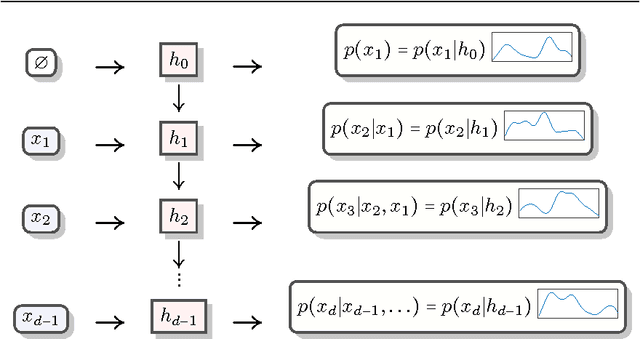
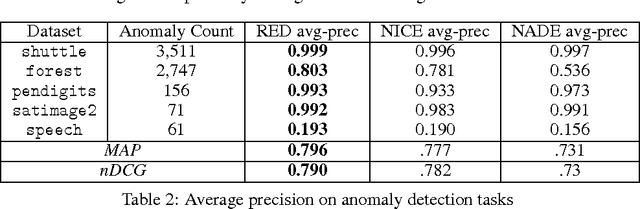
This paper presents the recurrent estimation of distributions (RED) for modeling real-valued data in a semiparametric fashion. RED models make two novel uses of recurrent neural networks (RNNs) for density estimation of general real-valued data. First, RNNs are used to transform input covariates into a latent space to better capture conditional dependencies in inputs. After, an RNN is used to compute the conditional distributions of the latent covariates. The resulting model is efficient to train, compute, and sample from, whilst producing normalized pdfs. The effectiveness of RED is shown via several real-world data experiments. Our results show that RED models achieve a lower held-out negative log-likelihood than other neural network approaches across multiple dataset sizes and dimensionalities. Further context of the efficacy of RED is provided by considering anomaly detection tasks, where we also observe better performance over alternative models.