 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025



We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024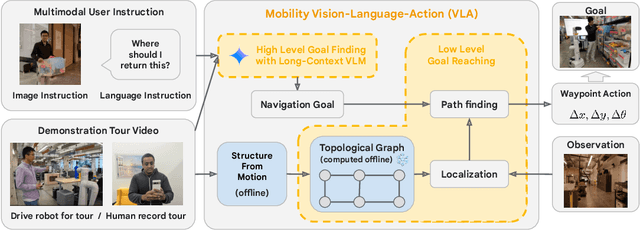
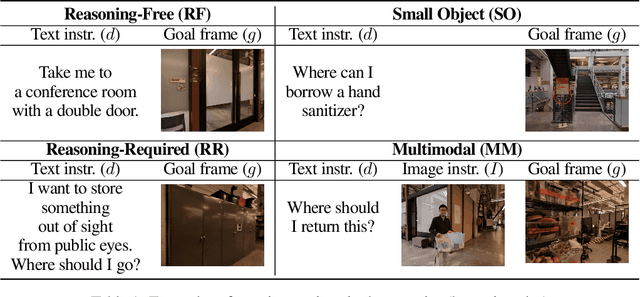


An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023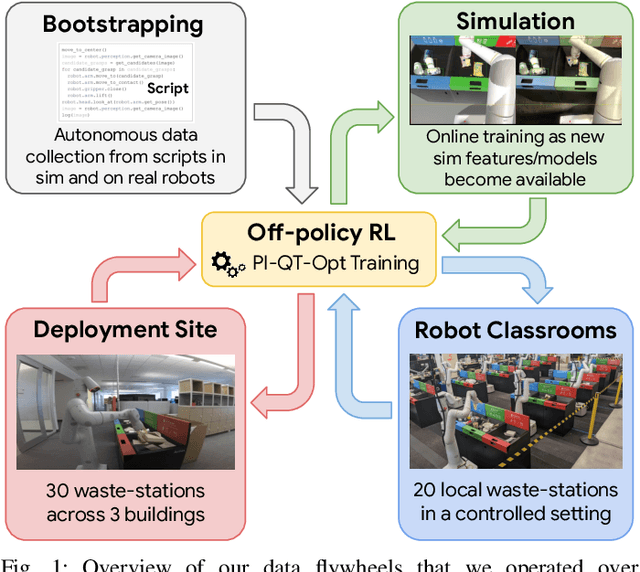


We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.