 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Inference of Human Perceptions of Robot Performance in Social Navigation Scenarios
Dec 17, 2025Understanding how humans evaluate robot behavior during human-robot interactions is crucial for developing socially aware robots that behave according to human expectations. While the traditional approach to capturing these evaluations is to conduct a user study, recent work has proposed utilizing machine learning instead. However, existing data-driven methods require large amounts of labeled data, which limits their use in practice. To address this gap, we propose leveraging the few-shot learning capabilities of Large Language Models (LLMs) to improve how well a robot can predict a user's perception of its performance, and study this idea experimentally in social navigation tasks. To this end, we extend the SEAN TOGETHER dataset with additional real-world human-robot navigation episodes and participant feedback. Using this augmented dataset, we evaluate the ability of several LLMs to predict human perceptions of robot performance from a small number of in-context examples, based on observed spatio-temporal cues of the robot and surrounding human motion. Our results demonstrate that LLMs can match or exceed the performance of traditional supervised learning models while requiring an order of magnitude fewer labeled instances. We further show that prediction performance can improve with more in-context examples, confirming the scalability of our approach. Additionally, we investigate what kind of sensor-based information an LLM relies on to make these inferences by conducting an ablation study on the input features considered for performance prediction. Finally, we explore the novel application of personalized examples for in-context learning, i.e., drawn from the same user being evaluated, finding that they further enhance prediction accuracy. This work paves the path to improving robot behavior in a scalable manner through user-centered feedback.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024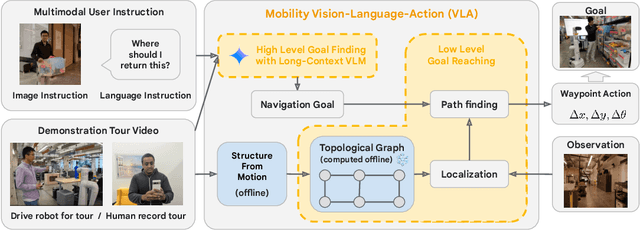
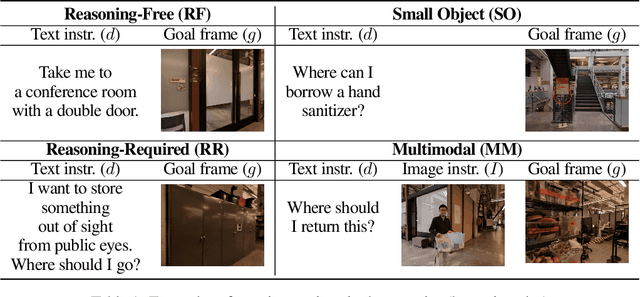


An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
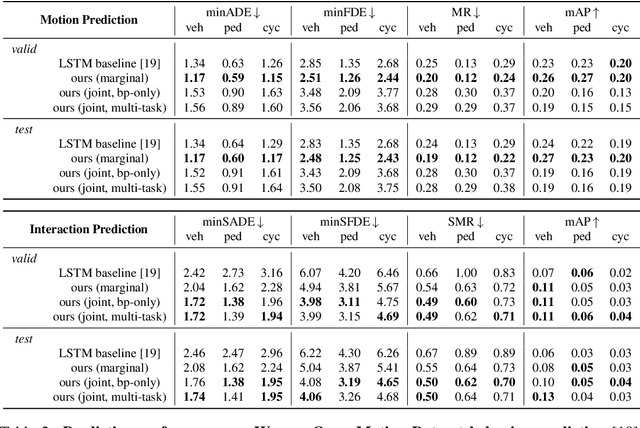
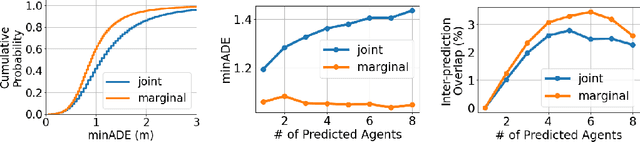
Towards Inferring Users' Impressions of Robot Performance in Navigation Scenarios
Oct 17, 2023
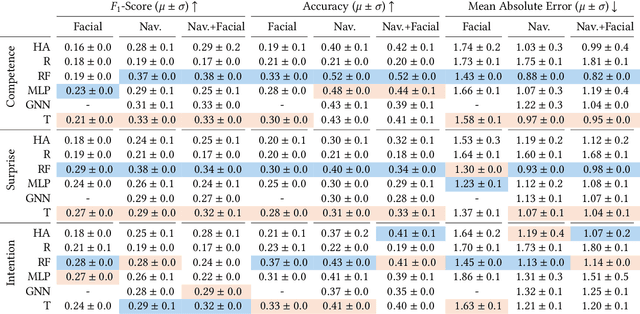
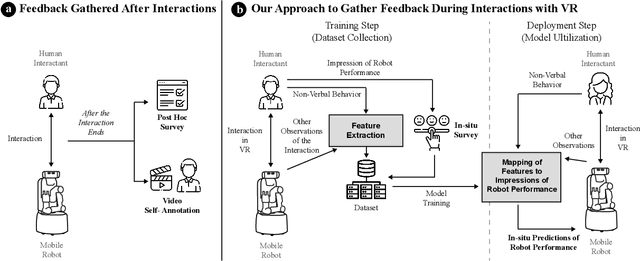
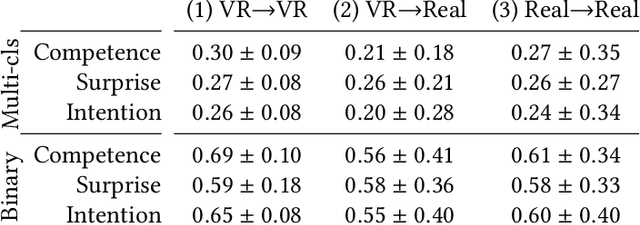
Human impressions of robot performance are often measured through surveys. As a more scalable and cost-effective alternative, we study the possibility of predicting people's impressions of robot behavior using non-verbal behavioral cues and machine learning techniques. To this end, we first contribute the SEAN TOGETHER Dataset consisting of observations of an interaction between a person and a mobile robot in a Virtual Reality simulation, together with impressions of robot performance provided by users on a 5-point scale. Second, we contribute analyses of how well humans and supervised learning techniques can predict perceived robot performance based on different combinations of observation types (e.g., facial, spatial, and map features). Our results show that facial expressions alone provide useful information about human impressions of robot performance; but in the navigation scenarios we tested, spatial features are the most critical piece of information for this inference task. Also, when evaluating results as binary classification (rather than multiclass classification), the F1-Score of human predictions and machine learning models more than doubles, showing that both are better at telling the directionality of robot performance than predicting exact performance ratings. Based on our findings, we provide guidelines for implementing these predictions models in real-world navigation scenarios.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Language to Rewards for Robotic Skill Synthesis
Jun 16, 2023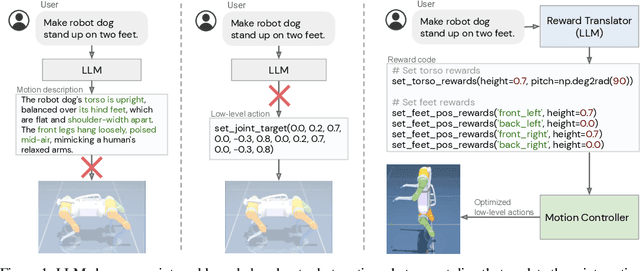
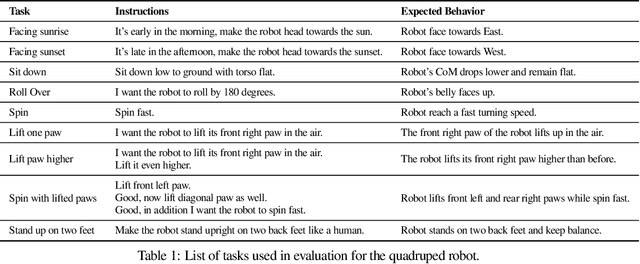

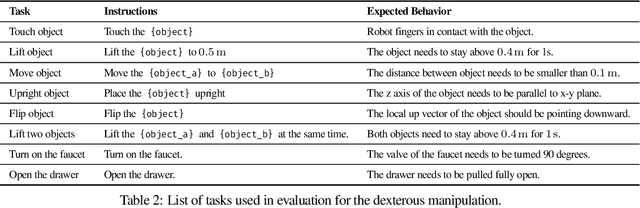
Large language models (LLMs) have demonstrated exciting progress in acquiring diverse new capabilities through in-context learning, ranging from logical reasoning to code-writing. Robotics researchers have also explored using LLMs to advance the capabilities of robotic control. However, since low-level robot actions are hardware-dependent and underrepresented in LLM training corpora, existing efforts in applying LLMs to robotics have largely treated LLMs as semantic planners or relied on human-engineered control primitives to interface with the robot. On the other hand, reward functions are shown to be flexible representations that can be optimized for control policies to achieve diverse tasks, while their semantic richness makes them suitable to be specified by LLMs. In this work, we introduce a new paradigm that harnesses this realization by utilizing LLMs to define reward parameters that can be optimized and accomplish variety of robotic tasks. Using reward as the intermediate interface generated by LLMs, we can effectively bridge the gap between high-level language instructions or corrections to low-level robot actions. Meanwhile, combining this with a real-time optimizer, MuJoCo MPC, empowers an interactive behavior creation experience where users can immediately observe the results and provide feedback to the system. To systematically evaluate the performance of our proposed method, we designed a total of 17 tasks for a simulated quadruped robot and a dexterous manipulator robot. We demonstrate that our proposed method reliably tackles 90% of the designed tasks, while a baseline using primitive skills as the interface with Code-as-policies achieves 50% of the tasks. We further validated our method on a real robot arm where complex manipulation skills such as non-prehensile pushing emerge through our interactive system.
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021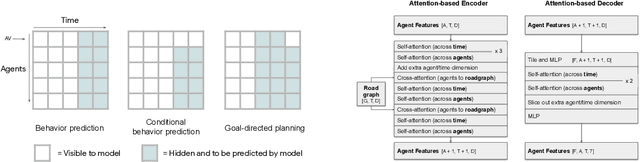
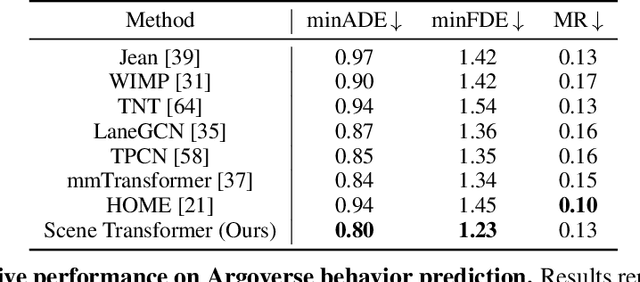
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
RL-RRT: Kinodynamic Motion Planning via Learning Reachability Estimators from RL Policies
Jul 12, 2019


This paper addresses two challenges facing sampling-based kinodynamic motion planning: a way to identify good candidate states for local transitions and the subsequent computationally intractable steering between these candidate states. Through the combination of sampling-based planning, a Rapidly Exploring Randomized Tree (RRT) and an efficient kinodynamic motion planner through machine learning, we propose an efficient solution to long-range planning for kinodynamic motion planning. First, we use deep reinforcement learning to learn an obstacle-avoiding policy that maps a robot's sensor observations to actions, which is used as a local planner during planning and as a controller during execution. Second, we train a reachability estimator in a supervised manner, which predicts the RL policy's time to reach a state in the presence of obstacles. Lastly, we introduce RL-RRT that uses the RL policy as a local planner, and the reachability estimator as the distance function to bias tree-growth towards promising regions. We evaluate our method on three kinodynamic systems, including physical robot experiments. Results across all three robots tested indicate that RL-RRT outperforms state of the art kinodynamic planners in efficiency, and also provides a shorter path finish time than a steering function free method. The learned local planner policy and accompanying reachability estimator demonstrate transferability to the previously unseen experimental environments, making RL-RRT fast because the expensive computations are replaced with simple neural network inference. Video: https://youtu.be/dDMVMTOI8KY
* Accepted to Robotics and Automation Letters in June 2019
Long-Range Indoor Navigation with PRM-RL
Feb 25, 2019
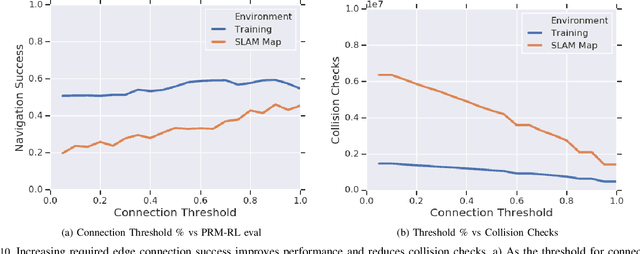
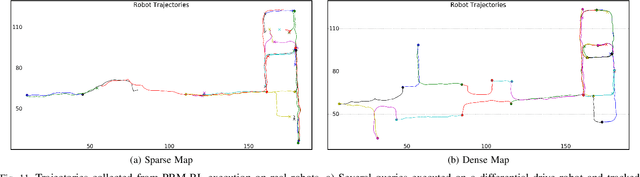
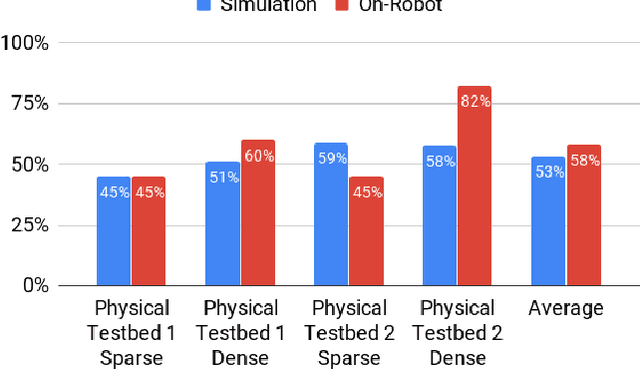
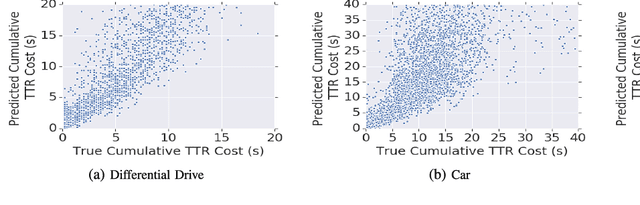
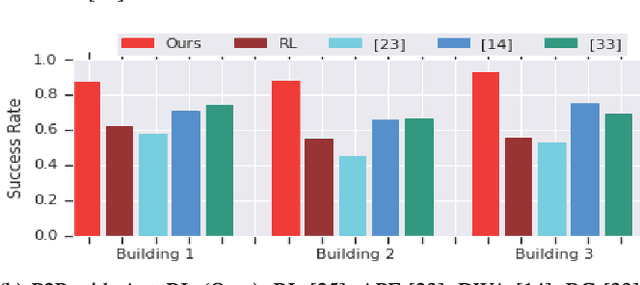
Long-range indoor navigation requires guiding robots with noisy sensors and controls through cluttered environments along paths that span a variety of buildings. We achieve this with PRM-RL, a hierarchical robot navigation method in which reinforcement learning agents that map noisy sensors to robot controls learn to solve short-range obstacle avoidance tasks, and then sampling-based planners map where these agents can reliably navigate in simulation; these roadmaps and agents are then deployed on-robot, guiding the robot along the shortest path where the agents are likely to succeed. Here we use Probabilistic Roadmaps (PRMs) as the sampling-based planner and AutoRL as the reinforcement learning method in the indoor navigation context. We evaluate the method in simulation for kinematic differential drive and kinodynamic car-like robots in several environments, and on-robot for differential-drive robots at two physical sites. Our results show PRM-RL with AutoRL is more successful than several baselines, is robust to noise, and can guide robots over hundreds of meters in the face of noise and obstacles in both simulation and on-robot, including over 3.3 kilometers of physical robot navigation.
Learning Navigation Behaviors End-to-End with AutoRL
Feb 01, 2019

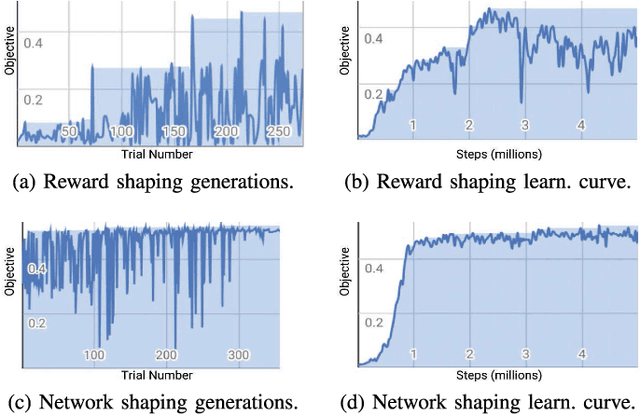
We learn end-to-end point-to-point and path-following navigation behaviors that avoid moving obstacles. These policies receive noisy lidar observations and output robot linear and angular velocities. The policies are trained in small, static environments with AutoRL, an evolutionary automation layer around Reinforcement Learning (RL) that searches for a deep RL reward and neural network architecture with large-scale hyper-parameter optimization. AutoRL first finds a reward that maximizes task completion, and then finds a neural network architecture that maximizes the cumulative of the found reward. Empirical evaluations, both in simulation and on-robot, show that AutoRL policies do not suffer from the catastrophic forgetfulness that plagues many other deep reinforcement learning algorithms, generalize to new environments and moving obstacles, are robust to sensor, actuator, and localization noise, and can serve as robust building blocks for larger navigation tasks. Our path-following and point-to-point policies are respectively 23% and 26% more successful than comparison methods across new environments. Video at: https://youtu.be/0UwkjpUEcbI