 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023
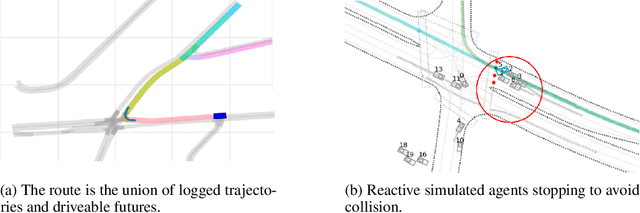
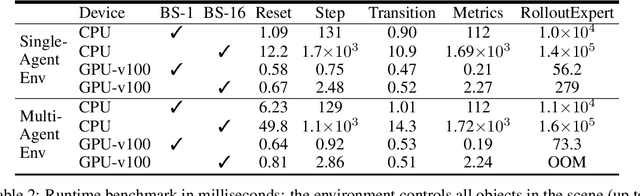
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
CausalAgents: A Robustness Benchmark for Motion Forecasting using Causal Relationships
Jul 07, 2022


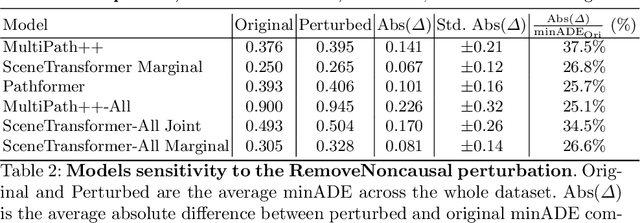
As machine learning models become increasingly prevalent in motion forecasting systems for autonomous vehicles (AVs), it is critical that we ensure that model predictions are safe and reliable. However, exhaustively collecting and labeling the data necessary to fully test the long tail of rare and challenging scenarios is difficult and expensive. In this work, we construct a new benchmark for evaluating and improving model robustness by applying perturbations to existing data. Specifically, we conduct an extensive labeling effort to identify causal agents, or agents whose presence influences human driver behavior in any way, in the Waymo Open Motion Dataset (WOMD), and we use these labels to perturb the data by deleting non-causal agents from the scene. We then evaluate a diverse set of state-of-the-art deep-learning model architectures on our proposed benchmark and find that all models exhibit large shifts under perturbation. Under non-causal perturbations, we observe a $25$-$38\%$ relative change in minADE as compared to the original. We then investigate techniques to improve model robustness, including increasing the training dataset size and using targeted data augmentations that drop agents throughout training. We plan to provide the causal agent labels as an additional attribute to WOMD and release the robustness benchmarks to aid the community in building more reliable and safe deep-learning models for motion forecasting.
When does dough become a bagel? Analyzing the remaining mistakes on ImageNet
May 09, 2022



Image classification accuracy on the ImageNet dataset has been a barometer for progress in computer vision over the last decade. Several recent papers have questioned the degree to which the benchmark remains useful to the community, yet innovations continue to contribute gains to performance, with today's largest models achieving 90%+ top-1 accuracy. To help contextualize progress on ImageNet and provide a more meaningful evaluation for today's state-of-the-art models, we manually review and categorize every remaining mistake that a few top models make in order to provide insight into the long-tail of errors on one of the most benchmarked datasets in computer vision. We focus on the multi-label subset evaluation of ImageNet, where today's best models achieve upwards of 97% top-1 accuracy. Our analysis reveals that nearly half of the supposed mistakes are not mistakes at all, and we uncover new valid multi-labels, demonstrating that, without careful review, we are significantly underestimating the performance of these models. On the other hand, we also find that today's best models still make a significant number of mistakes (40%) that are obviously wrong to human reviewers. To calibrate future progress on ImageNet, we provide an updated multi-label evaluation set, and we curate ImageNet-Major: a 68-example "major error" slice of the obvious mistakes made by today's top models -- a slice where models should achieve near perfection, but today are far from doing so.
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Mar 10, 2022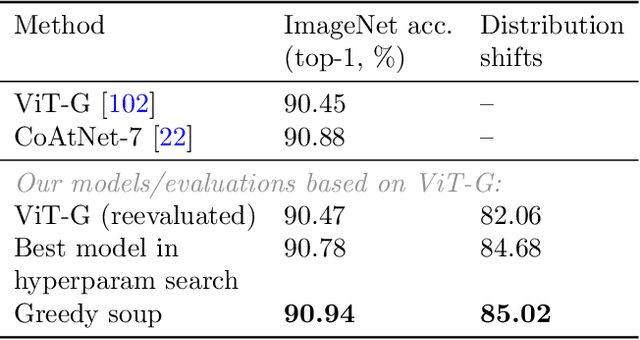
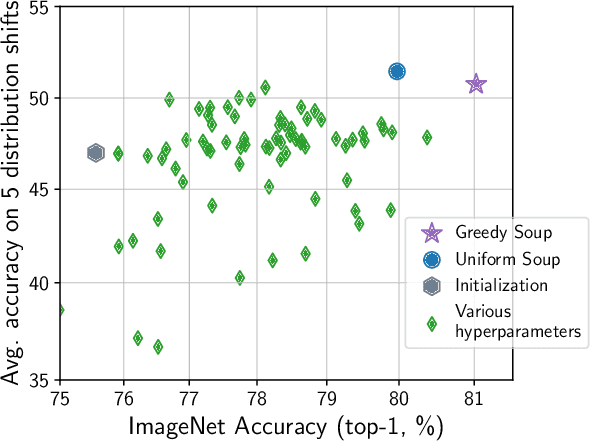

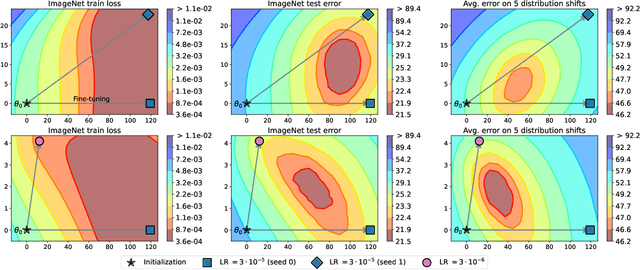
The conventional recipe for maximizing model accuracy is to (1) train multiple models with various hyperparameters and (2) pick the individual model which performs best on a held-out validation set, discarding the remainder. In this paper, we revisit the second step of this procedure in the context of fine-tuning large pre-trained models, where fine-tuned models often appear to lie in a single low error basin. We show that averaging the weights of multiple models fine-tuned with different hyperparameter configurations often improves accuracy and robustness. Unlike a conventional ensemble, we may average many models without incurring any additional inference or memory costs -- we call the results "model soups." When fine-tuning large pre-trained models such as CLIP, ALIGN, and a ViT-G pre-trained on JFT, our soup recipe provides significant improvements over the best model in a hyperparameter sweep on ImageNet. As a highlight, the resulting ViT-G model attains 90.94% top-1 accuracy on ImageNet, a new state of the art. Furthermore, we show that the model soup approach extends to multiple image classification and natural language processing tasks, improves out-of-distribution performance, and improves zero-shot performance on new downstream tasks. Finally, we analytically relate the performance similarity of weight-averaging and logit-ensembling to flatness of the loss and confidence of the predictions, and validate this relation empirically.
Spectral Bias in Practice: The Role of Function Frequency in Generalization
Oct 06, 2021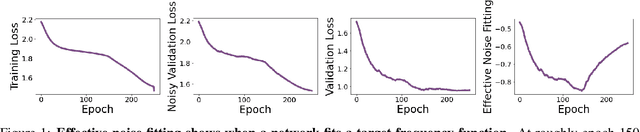
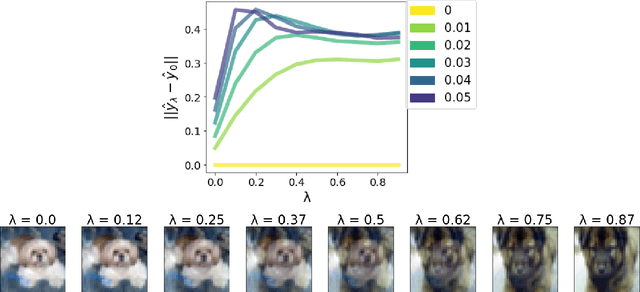
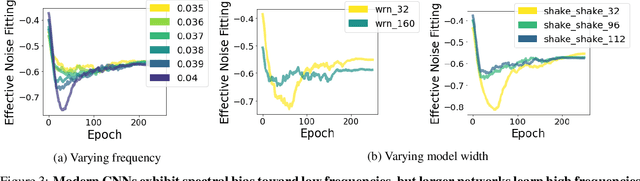
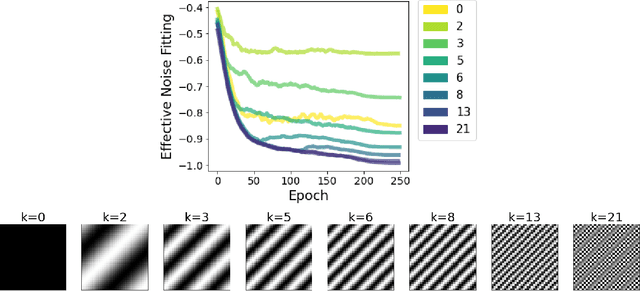
Despite their ability to represent highly expressive functions, deep learning models trained with SGD seem to find simple, constrained solutions that generalize surprisingly well. Spectral bias - the tendency of neural networks to prioritize learning low frequency functions - is one possible explanation for this phenomenon, but so far spectral bias has only been observed in theoretical models and simplified experiments. In this work, we propose methodologies for measuring spectral bias in modern image classification networks. We find that these networks indeed exhibit spectral bias, and that networks that generalize well strike a balance between having enough complexity(i.e. high frequencies) to fit the data while being simple enough to avoid overfitting. For example, we experimentally show that larger models learn high frequencies faster than smaller ones, but many forms of regularization, both explicit and implicit, amplify spectral bias and delay the learning of high frequencies. We also explore the connections between function frequency and image frequency and find that spectral bias is sensitive to the low frequencies prevalent in natural images. Our work enables measuring and ultimately controlling the spectral behavior of neural networks used for image classification, and is a step towards understanding why deep models generalize well
The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning
Jun 30, 2021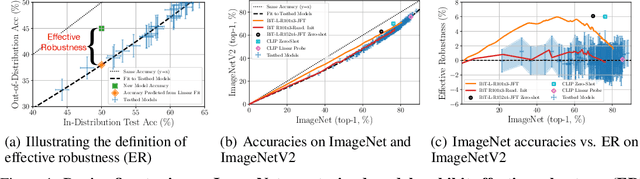

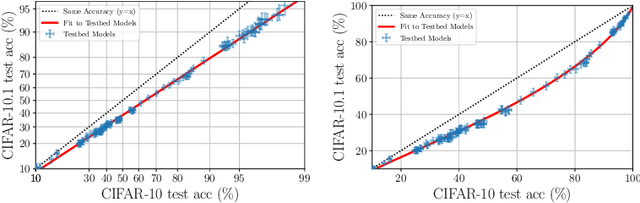

Although machine learning models typically experience a drop in performance on out-of-distribution data, accuracies on in- versus out-of-distribution data are widely observed to follow a single linear trend when evaluated across a testbed of models. Models that are more accurate on the out-of-distribution data relative to this baseline exhibit "effective robustness" and are exceedingly rare. Identifying such models, and understanding their properties, is key to improving out-of-distribution performance. We conduct a thorough empirical investigation of effective robustness during fine-tuning and surprisingly find that models pre-trained on larger datasets exhibit effective robustness during training that vanishes at convergence. We study how properties of the data influence effective robustness, and we show that it increases with the larger size, more diversity, and higher example difficulty of the dataset. We also find that models that display effective robustness are able to correctly classify 10% of the examples that no other current testbed model gets correct. Finally, we discuss several strategies for scaling effective robustness to the high-accuracy regime to improve the out-of-distribution accuracy of state-of-the-art models.
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021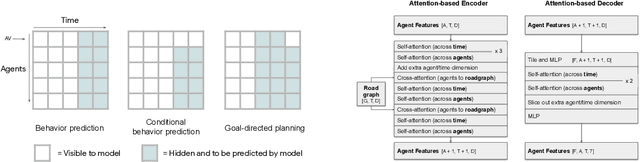
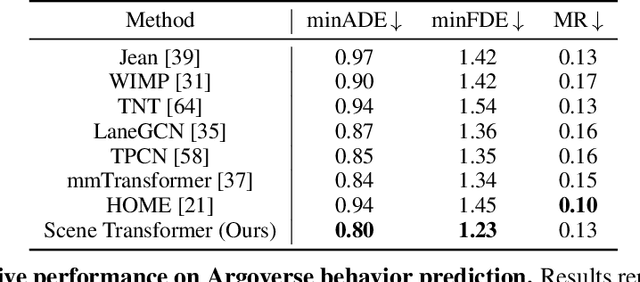
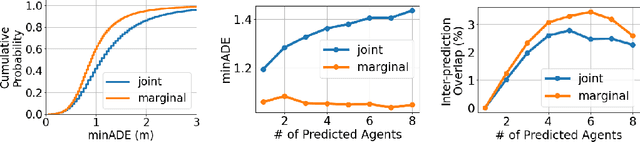
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
Jun 08, 2021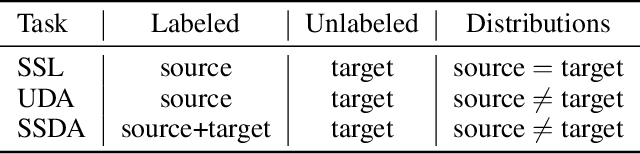
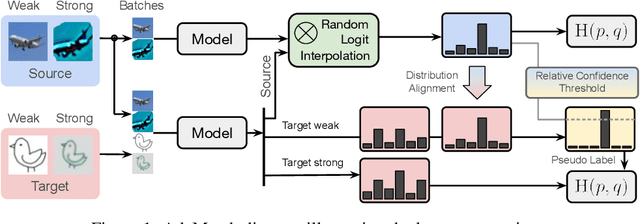

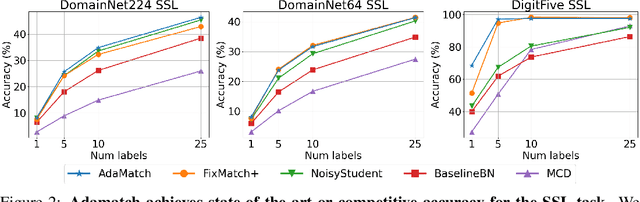
We extend semi-supervised learning to the problem of domain adaptation to learn significantly higher-accuracy models that train on one data distribution and test on a different one. With the goal of generality, we introduce AdaMatch, a method that unifies the tasks of unsupervised domain adaptation (UDA), semi-supervised learning (SSL), and semi-supervised domain adaptation (SSDA). In an extensive experimental study, we compare its behavior with respective state-of-the-art techniques from SSL, SSDA, and UDA on vision classification tasks. We find AdaMatch either matches or significantly exceeds the state-of-the-art in each case using the same hyper-parameters regardless of the dataset or task. For example, AdaMatch nearly doubles the accuracy compared to that of the prior state-of-the-art on the UDA task for DomainNet and even exceeds the accuracy of the prior state-of-the-art obtained with pre-training by 6.4% when AdaMatch is trained completely from scratch. Furthermore, by providing AdaMatch with just one labeled example per class from the target domain (i.e., the SSDA setting), we increase the target accuracy by an additional 6.1%, and with 5 labeled examples, by 13.6%.
Pseudo-labeling for Scalable 3D Object Detection
Mar 02, 2021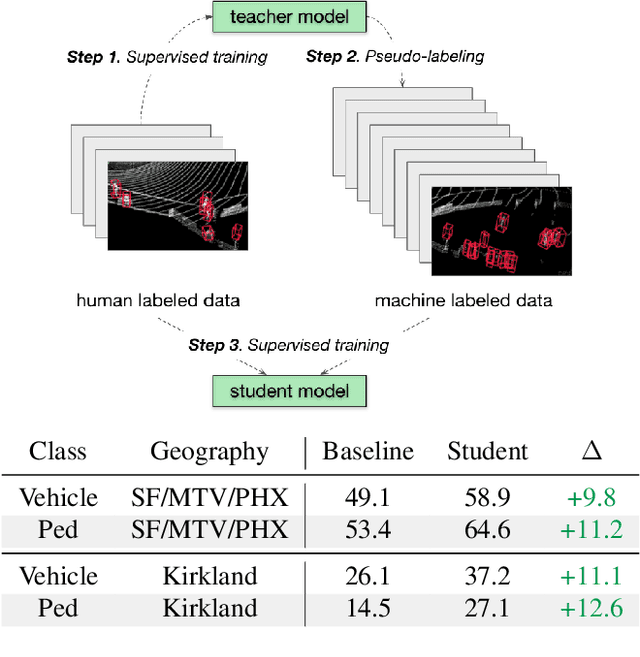
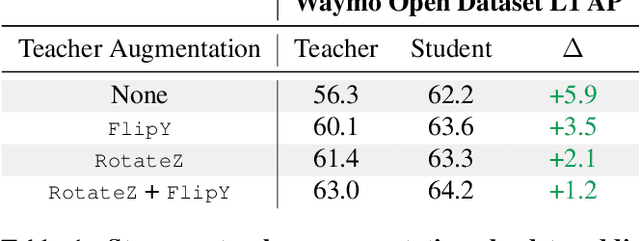
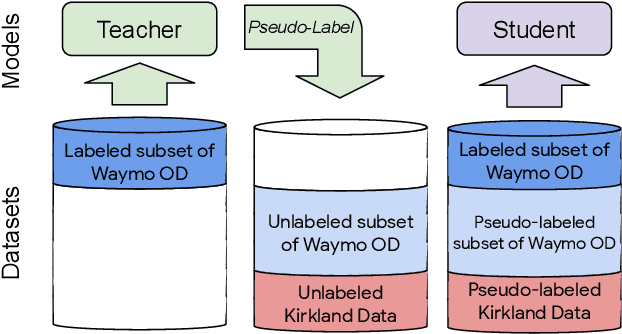
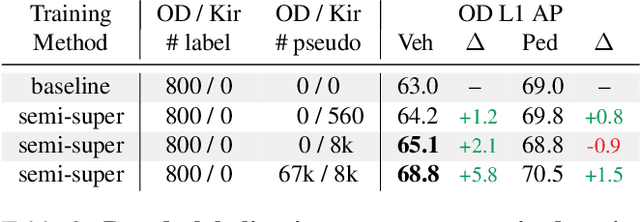
To safely deploy autonomous vehicles, onboard perception systems must work reliably at high accuracy across a diverse set of environments and geographies. One of the most common techniques to improve the efficacy of such systems in new domains involves collecting large labeled datasets, but such datasets can be extremely costly to obtain, especially if each new deployment geography requires additional data with expensive 3D bounding box annotations. We demonstrate that pseudo-labeling for 3D object detection is an effective way to exploit less expensive and more widely available unlabeled data, and can lead to performance gains across various architectures, data augmentation strategies, and sizes of the labeled dataset. Overall, we show that better teacher models lead to better student models, and that we can distill expensive teachers into efficient, simple students. Specifically, we demonstrate that pseudo-label-trained student models can outperform supervised models trained on 3-10 times the amount of labeled examples. Using PointPillars [24], a two-year-old architecture, as our student model, we are able to achieve state of the art accuracy simply by leveraging large quantities of pseudo-labeled data. Lastly, we show that these student models generalize better than supervised models to a new domain in which we only have unlabeled data, making pseudo-label training an effective form of unsupervised domain adaptation.
Mitigating bias in calibration error estimation
Dec 15, 2020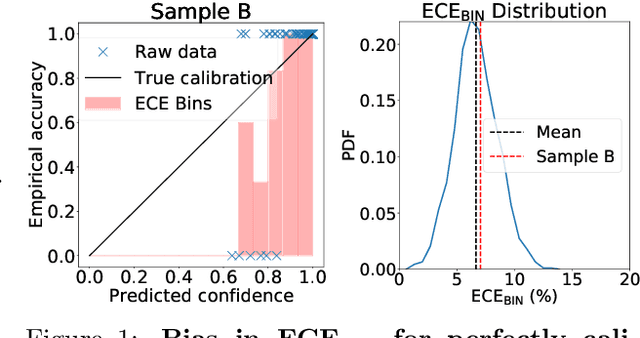
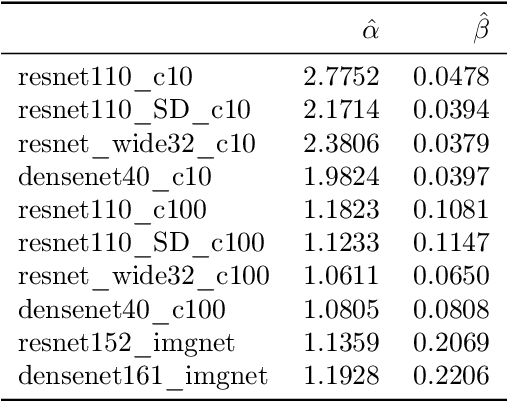
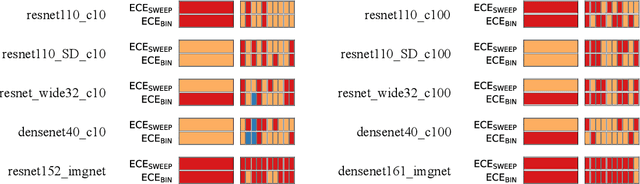
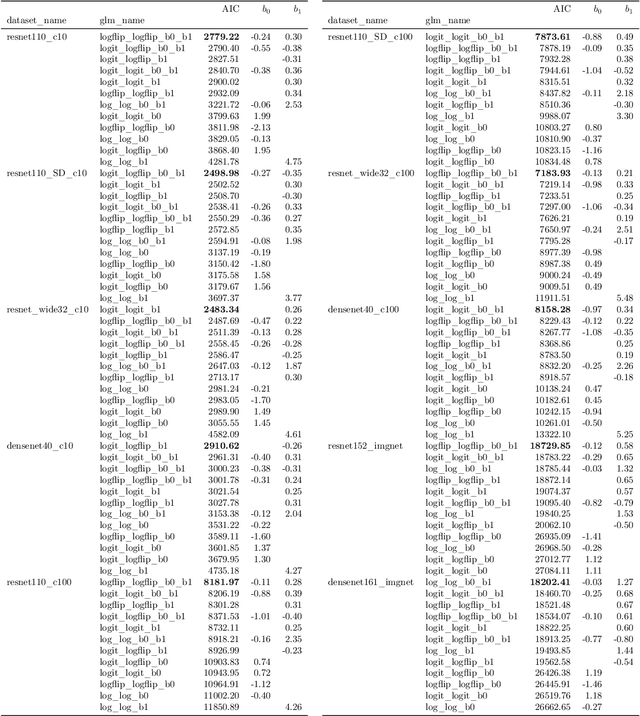
Building reliable machine learning systems requires that we correctly understand their level of confidence. Calibration focuses on measuring the degree of accuracy in a model's confidence and most research in calibration focuses on techniques to improve an empirical estimate of calibration error, ECE_bin. Using simulation, we show that ECE_bin can systematically underestimate or overestimate the true calibration error depending on the nature of model miscalibration, the size of the evaluation data set, and the number of bins. Critically, ECE_bin is more strongly biased for perfectly calibrated models. We propose a simple alternative calibration error metric, ECE_sweep, in which the number of bins is chosen to be as large as possible while preserving monotonicity in the calibration function. Evaluating our measure on distributions fit to neural network confidence scores on CIFAR-10, CIFAR-100, and ImageNet, we show that ECE_sweep produces a less biased estimator of calibration error and therefore should be used by any researcher wishing to evaluate the calibration of models trained on similar datasets.