 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Swiss Round: Aggregating Multi-Benchmark Performance via Competitive Swiss-System Dynamics
Dec 24, 2025The rapid proliferation of Large Language Models (LLMs) and diverse specialized benchmarks necessitates a shift from fragmented, task-specific metrics to a holistic, competitive ranking system that effectively aggregates performance across multiple ability dimensions. Primarily using static scoring, current evaluation methods are fundamentally limited. They struggle to determine the proper mix ratio across diverse benchmarks, and critically, they fail to capture a model's dynamic competitive fitness or its vulnerability when confronted with sequential, high-stakes tasks. To address this, we introduce the novel Competitive Swiss-System Dynamics (CSD) framework. CSD simulates a multi-round, sequential contest where models are dynamically paired across a curated sequence of benchmarks based on their accumulated win-loss record. And Monte Carlo Simulation ($N=100,000$ iterations) is used to approximate the statistically robust Expected Win Score ($E[S_m]$), which eliminates the noise of random pairing and early-round luck. Furthermore, we implement a Failure Sensitivity Analysis by parameterizing the per-round elimination quantity ($T_k$), which allows us to profile models based on their risk appetite--distinguishing between robust generalists and aggressive specialists. We demonstrate that CSD provides a more nuanced and context-aware ranking than traditional aggregate scoring and static pairwise models, representing a vital step towards risk-informed, next-generation LLM evaluation.
SynthTools: A Framework for Scaling Synthetic Tools for Agent Development
Nov 11, 2025



AI agents increasingly rely on external tools to solve complex, long-horizon tasks. Advancing such agents requires reproducible evaluation and large-scale training in controllable, diverse, and realistic tool-use environments. However, real-world APIs are limited in availability, domain coverage, and stability, often requiring access keys and imposing rate limits, which render them impractical for stable evaluation or scalable training. To address these challenges, we introduce SynthTools, a flexible and scalable framework for generating synthetic tool ecosystems. Our framework consists of three core components: Tool Generation for automatic and scalable creation of diverse tools, Tool Simulation to emulate realistic tool behaviors, and Tool Audit to ensure correctness and consistency of tool simulation. To illustrate its scalability, we show that SynthTools can readily produce toolsets that span twice as many domains and twice as many tools per domain as prior work. Furthermore, the tool simulation and tool audit components demonstrate strong reliability, achieving $94\%$ and $99\%$ accuracy respectively. Finally, we construct downstream tasks from the generated tools that even state-of-the-art models struggle to complete. By enabling scalable, diverse, and reliable tool ecosystems, SynthTools provides a practical path toward large-scale training and stable evaluation of tool-use agents. Our code is available at https://github.com/namkoong-lab/SynthTools.
Learning-To-Measure: In-context Active Feature Acquisition
Oct 14, 2025



Active feature acquisition (AFA) is a sequential decision-making problem where the goal is to improve model performance for test instances by adaptively selecting which features to acquire. In practice, AFA methods often learn from retrospective data with systematic missingness in the features and limited task-specific labels. Most prior work addresses acquisition for a single predetermined task, limiting scalability. To address this limitation, we formalize the meta-AFA problem, where the goal is to learn acquisition policies across various tasks. We introduce Learning-to-Measure (L2M), which consists of i) reliable uncertainty quantification over unseen tasks, and ii) an uncertainty-guided greedy feature acquisition agent that maximizes conditional mutual information. We demonstrate a sequence-modeling or autoregressive pre-training approach that underpins reliable uncertainty quantification for tasks with arbitrary missingness. L2M operates directly on datasets with retrospective missingness and performs the meta-AFA task in-context, eliminating per-task retraining. Across synthetic and real-world tabular benchmarks, L2M matches or surpasses task-specific baselines, particularly under scarce labels and high missingness.
A Broader View of Thompson Sampling
Oct 08, 2025Thompson Sampling is one of the most widely used and studied bandit algorithms, known for its simple structure, low regret performance, and solid theoretical guarantees. Yet, in stark contrast to most other families of bandit algorithms, the exact mechanism through which posterior sampling (as introduced by Thompson) is able to "properly" balance exploration and exploitation, remains a mystery. In this paper we show that the core insight to address this question stems from recasting Thompson Sampling as an online optimization algorithm. To distill this, a key conceptual tool is introduced, which we refer to as "faithful" stationarization of the regret formulation. Essentially, the finite horizon dynamic optimization problem is converted into a stationary counterpart which "closely resembles" the original objective (in contrast, the classical infinite horizon discounted formulation, that leads to the Gittins index, alters the problem and objective in too significant a manner). The newly crafted time invariant objective can be studied using Bellman's principle which leads to a time invariant optimal policy. When viewed through this lens, Thompson Sampling admits a simple online optimization form that mimics the structure of the Bellman-optimal policy, and where greediness is regularized by a measure of residual uncertainty based on point-biserial correlation. This answers the question of how Thompson Sampling balances exploration-exploitation, and moreover, provides a principled framework to study and further improve Thompson's original idea.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
DRO: A Python Library for Distributionally Robust Optimization in Machine Learning
May 29, 2025



We introduce dro, an open-source Python library for distributionally robust optimization (DRO) for regression and classification problems. The library implements 14 DRO formulations and 9 backbone models, enabling 79 distinct DRO methods. Furthermore, dro is compatible with both scikit-learn and PyTorch. Through vectorization and optimization approximation techniques, dro reduces runtime by 10x to over 1000x compared to baseline implementations on large-scale datasets. Comprehensive documentation is available at https://python-dro.org.
Adaptive Elicitation of Latent Information Using Natural Language
Apr 05, 2025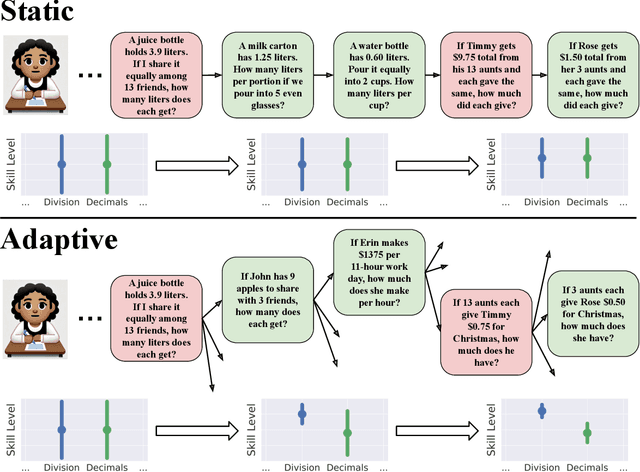

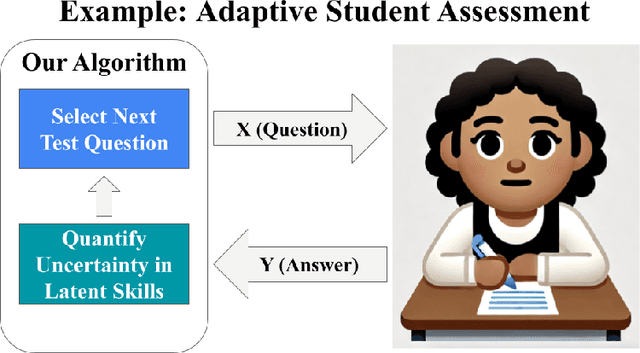

Eliciting information to reduce uncertainty about a latent entity is a critical task in many application domains, e.g., assessing individual student learning outcomes, diagnosing underlying diseases, or learning user preferences. Though natural language is a powerful medium for this purpose, large language models (LLMs) and existing fine-tuning algorithms lack mechanisms for strategically gathering information to refine their own understanding of the latent entity. To harness the generalization power and world knowledge of LLMs in developing effective information-gathering strategies, we propose an adaptive elicitation framework that actively reduces uncertainty on the latent entity. Since probabilistic modeling of an abstract latent entity is difficult, our framework adopts a predictive view of uncertainty, using a meta-learned language model to simulate future observations and enable scalable uncertainty quantification over complex natural language. Through autoregressive forward simulation, our model quantifies how new questions reduce epistemic uncertainty, enabling the development of sophisticated information-gathering strategies to choose the most informative next queries. In experiments on the 20 questions game, dynamic opinion polling, and adaptive student assessment, our method consistently outperforms baselines in identifying critical unknowns and improving downstream predictions, illustrating the promise of strategic information gathering in natural language settings.
Data Mixture Optimization: A Multi-fidelity Multi-scale Bayesian Framework
Mar 26, 2025Careful curation of data sources can significantly improve the performance of LLM pre-training, but predominant approaches rely heavily on intuition or costly trial-and-error, making them difficult to generalize across different data domains and downstream tasks. Although scaling laws can provide a principled and general approach for data curation, standard deterministic extrapolation from small-scale experiments to larger scales requires strong assumptions on the reliability of such extrapolation, whose brittleness has been highlighted in prior works. In this paper, we introduce a $\textit{probabilistic extrapolation framework}$ for data mixture optimization that avoids rigid assumptions and explicitly models the uncertainty in performance across decision variables. We formulate data curation as a sequential decision-making problem$\unicode{x2013}$multi-fidelity, multi-scale Bayesian optimization$\unicode{x2013}$where $\{$data mixtures, model scale, training steps$\}$ are adaptively selected to balance training cost and potential information gain. Our framework naturally gives rise to algorithm prototypes that leverage noisy information from inexpensive experiments to systematically inform costly training decisions. To accelerate methodological progress, we build a simulator based on 472 language model pre-training runs with varying data compositions from the SlimPajama dataset. We observe that even simple kernels and acquisition functions can enable principled decisions across training models from 20M to 1B parameters and achieve $\textbf{2.6x}$ and $\textbf{3.3x}$ speedups compared to multi-fidelity BO and random search baselines. Taken together, our framework underscores potential efficiency gains achievable by developing principled and transferable data mixture optimization methods.
LLM Generated Persona is a Promise with a Catch
Mar 18, 2025The use of large language models (LLMs) to simulate human behavior has gained significant attention, particularly through personas that approximate individual characteristics. Persona-based simulations hold promise for transforming disciplines that rely on population-level feedback, including social science, economic analysis, marketing research, and business operations. Traditional methods to collect realistic persona data face significant challenges. They are prohibitively expensive and logistically challenging due to privacy constraints, and often fail to capture multi-dimensional attributes, particularly subjective qualities. Consequently, synthetic persona generation with LLMs offers a scalable, cost-effective alternative. However, current approaches rely on ad hoc and heuristic generation techniques that do not guarantee methodological rigor or simulation precision, resulting in systematic biases in downstream tasks. Through extensive large-scale experiments including presidential election forecasts and general opinion surveys of the U.S. population, we reveal that these biases can lead to significant deviations from real-world outcomes. Our findings underscore the need to develop a rigorous science of persona generation and outline the methodological innovations, organizational and institutional support, and empirical foundations required to enhance the reliability and scalability of LLM-driven persona simulations. To support further research and development in this area, we have open-sourced approximately one million generated personas, available for public access and analysis at https://huggingface.co/datasets/Tianyi-Lab/Personas.
Architectural and Inferential Inductive Biases For Exchangeable Sequence Modeling
Mar 03, 2025Autoregressive models have emerged as a powerful framework for modeling exchangeable sequences - i.i.d. observations when conditioned on some latent factor - enabling direct modeling of uncertainty from missing data (rather than a latent). Motivated by the critical role posterior inference plays as a subroutine in decision-making (e.g., active learning, bandits), we study the inferential and architectural inductive biases that are most effective for exchangeable sequence modeling. For the inference stage, we highlight a fundamental limitation of the prevalent single-step generation approach: inability to distinguish between epistemic and aleatoric uncertainty. Instead, a long line of works in Bayesian statistics advocates for multi-step autoregressive generation; we demonstrate this "correct approach" enables superior uncertainty quantification that translates into better performance on downstream decision-making tasks. This naturally leads to the next question: which architectures are best suited for multi-step inference? We identify a subtle yet important gap between recently proposed Transformer architectures for exchangeable sequences (Muller et al., 2022; Nguyen & Grover, 2022; Ye & Namkoong, 2024), and prove that they in fact cannot guarantee exchangeability despite introducing significant computational overhead. We illustrate our findings using controlled synthetic settings, demonstrating how custom architectures can significantly underperform standard causal masks, underscoring the need for new architectural innovations.