 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well do LLMs Compress Their Own Chain-of-Thought? A Token Complexity Approach
Mar 03, 2025Chain-of-thought prompting has emerged as a powerful technique for enabling large language models (LLMs) to solve complex reasoning tasks. However, these reasoning chains can be verbose, raising concerns about efficiency. In response, recent works have sought to decrease response lengths through simple prompting strategies (e.g. 'be concise'). In this work, we conduct the first systematic study of the relationship between reasoning length and model performance across a diverse range of compression instructions (e.g. 'use 10 words or less' or 'remove all punctuation'). In doing so, we discover a universal tradeoff between reasoning length and accuracy that persists across even very distinct reasoning chains. We demonstrate that this tradeoff emerges from a sharp threshold behavior at the question level: each task has an intrinsic 'token complexity' - a minimal number of tokens required for successful problem-solving. We show how token complexity enables us to compute information-theoretic limits on the accuracy-compression tradeoff, and find that prompt-based compression strategies operate far from these theoretical limits. This suggests there may be significant room for improvement and our framework provides a benchmark to help researchers evaluate progress in reasoning efficiency. Our work also highlights the importance of adaptive compression -- giving shorter responses for easier questions -- and we show that token complexity is a useful tool for measuring this capability.
QGym: Scalable Simulation and Benchmarking of Queuing Network Controllers
Oct 08, 2024



Queuing network control determines the allocation of scarce resources to manage congestion, a fundamental problem in manufacturing, communications, and healthcare. Compared to standard RL problems, queueing problems are distinguished by unique challenges: i) a system operating in continuous time, ii) high stochasticity, and iii) long horizons over which the system can become unstable (exploding delays). To spur methodological progress tackling these challenges, we present an open-sourced queueing simulation framework, QGym, that benchmark queueing policies across realistic problem instances. Our modular framework allows the researchers to build on our initial instances, which provide a wide range of environments including parallel servers, criss-cross, tandem, and re-entrant networks, as well as a realistically calibrated hospital queuing system. QGym makes it easy to compare multiple policies, including both model-free RL methods and classical queuing policies. Our testbed complements the traditional focus on evaluating algorithms based on mathematical guarantees in idealized settings, and significantly expands the scope of empirical benchmarking in prior work. QGym code is open-sourced at https://github.com/namkoong-lab/QGym.
Stochastic Gradient Descent with Adaptive Data
Oct 02, 2024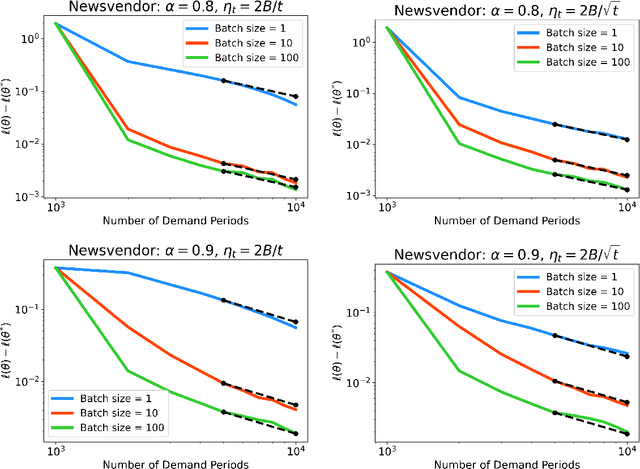

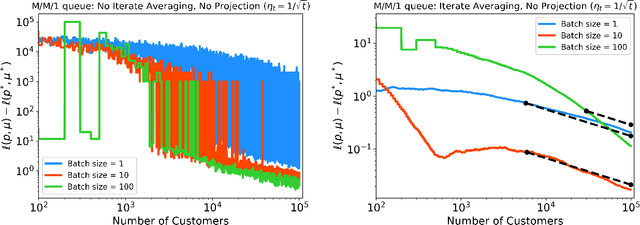
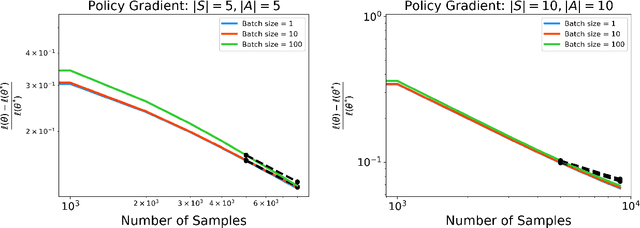
Stochastic gradient descent (SGD) is a powerful optimization technique that is particularly useful in online learning scenarios. Its convergence analysis is relatively well understood under the assumption that the data samples are independent and identically distributed (iid). However, applying SGD to policy optimization problems in operations research involves a distinct challenge: the policy changes the environment and thereby affects the data used to update the policy. The adaptively generated data stream involves samples that are non-stationary, no longer independent from each other, and affected by previous decisions. The influence of previous decisions on the data generated introduces bias in the gradient estimate, which presents a potential source of instability for online learning not present in the iid case. In this paper, we introduce simple criteria for the adaptively generated data stream to guarantee the convergence of SGD. We show that the convergence speed of SGD with adaptive data is largely similar to the classical iid setting, as long as the mixing time of the policy-induced dynamics is factored in. Our Lyapunov-function analysis allows one to translate existing stability analysis of stochastic systems studied in operations research into convergence rates for SGD, and we demonstrate this for queueing and inventory management problems. We also showcase how our result can be applied to study the sample complexity of an actor-critic policy gradient algorithm.
Differentiable Discrete Event Simulation for Queuing Network Control
Sep 05, 2024



Queuing network control is essential for managing congestion in job-processing systems such as service systems, communication networks, and manufacturing processes. Despite growing interest in applying reinforcement learning (RL) techniques, queueing network control poses distinct challenges, including high stochasticity, large state and action spaces, and lack of stability. To tackle these challenges, we propose a scalable framework for policy optimization based on differentiable discrete event simulation. Our main insight is that by implementing a well-designed smoothing technique for discrete event dynamics, we can compute pathwise policy gradients for large-scale queueing networks using auto-differentiation software (e.g., Tensorflow, PyTorch) and GPU parallelization. Through extensive empirical experiments, we observe that our policy gradient estimators are several orders of magnitude more accurate than typical REINFORCE-based estimators. In addition, We propose a new policy architecture, which drastically improves stability while maintaining the flexibility of neural-network policies. In a wide variety of scheduling and admission control tasks, we demonstrate that training control policies with pathwise gradients leads to a 50-1000x improvement in sample efficiency over state-of-the-art RL methods. Unlike prior tailored approaches to queueing, our methods can flexibly handle realistic scenarios, including systems operating in non-stationary environments and those with non-exponential interarrival/service times.
AExGym: Benchmarks and Environments for Adaptive Experimentation
Aug 08, 2024



Innovations across science and industry are evaluated using randomized trials (a.k.a. A/B tests). While simple and robust, such static designs are inefficient or infeasible for testing many hypotheses. Adaptive designs can greatly improve statistical power in theory, but they have seen limited adoption due to their fragility in practice. We present a benchmark for adaptive experimentation based on real-world datasets, highlighting prominent practical challenges to operationalizing adaptivity: non-stationarity, batched/delayed feedback, multiple outcomes and objectives, and external validity. Our benchmark aims to spur methodological development that puts practical performance (e.g., robustness) as a central concern, rather than mathematical guarantees on contrived instances. We release an open source library, AExGym, which is designed with modularity and extensibility in mind to allow experimentation practitioners to develop custom environments and algorithms.
Mathematical Programming For Adaptive Experiments
Aug 08, 2024



Adaptive experimentation can significantly improve statistical power, but standard algorithms overlook important practical issues including batched and delayed feedback, personalization, non-stationarity, multiple objectives, and constraints. To address these issues, the current algorithm design paradigm crafts tailored methods for each problem instance. Since it is infeasible to devise novel algorithms for every real-world instance, practitioners often have to resort to suboptimal approximations that do not address all of their challenges. Moving away from developing bespoke algorithms for each setting, we present a mathematical programming view of adaptive experimentation that can flexibly incorporate a wide range of objectives, constraints, and statistical procedures. By formulating a dynamic program in the batched limit, our modeling framework enables the use of scalable optimization methods (e.g., SGD and auto-differentiation) to solve for treatment allocations. We evaluate our framework on benchmarks modeled after practical challenges such as non-stationarity, personalization, multi-objectives, and constraints. Unlike bespoke algorithms such as modified variants of Thomson sampling, our mathematical programming approach provides remarkably robust performance across instances.
Adaptive Experimentation at Scale: Bayesian Algorithms for Flexible Batches
Mar 21, 2023Standard bandit algorithms that assume continual reallocation of measurement effort are challenging to implement due to delayed feedback and infrastructural/organizational difficulties. Motivated by practical instances involving a handful of reallocation epochs in which outcomes are measured in batches, we develop a new adaptive experimentation framework that can flexibly handle any batch size. Our main observation is that normal approximations universal in statistical inference can also guide the design of scalable adaptive designs. By deriving an asymptotic sequential experiment, we formulate a dynamic program that can leverage prior information on average rewards. State transitions of the dynamic program are differentiable with respect to the sampling allocations, allowing the use of gradient-based methods for planning and policy optimization. We propose a simple iterative planning method, Residual Horizon Optimization, which selects sampling allocations by optimizing a planning objective via stochastic gradient-based methods. Our method significantly improves statistical power over standard adaptive policies, even when compared to Bayesian bandit algorithms (e.g., Thompson sampling) that require full distributional knowledge of individual rewards. Overall, we expand the scope of adaptive experimentation to settings which are difficult for standard adaptive policies, including problems with a small number of reallocation epochs, low signal-to-noise ratio, and unknown reward distributions.