 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYN-DIGITS: A Synthetic Control Framework for Calibrated Digital Twin Simulation
Apr 08, 2026AI-based persona simulation -- often referred to as digital twin simulation -- is increasingly used for market research, recommender systems, and social sciences. Despite their flexibility, large language models (LLMs) often exhibit systematic bias and miscalibration relative to real human behavior, limiting their reliability. Inspired by synthetic control methods from causal inference, we propose SYN-DIGITS (SYNthetic Control Framework for Calibrated DIGItal Twin Simulation), a principled and lightweight calibration framework that learns latent structure from digital-twin responses and transfers it to align predictions with human ground truth. SYN-DIGITS operates as a post-processing layer on top of any LLM-based simulator and thus is model-agnostic. We develop a latent factor model that formalizes when and why calibration succeeds through latent space alignment conditions, and we systematically evaluate ten calibration methods across thirteen persona constructions, three LLMs, and two datasets. SYN-DIGITS supports both individual-level and distributional simulation for previously unseen questions and unobserved populations, with provable error guarantees. Experiments show that SYN-DIGITS achieves up to 50% relative improvements in individual-level correlation and 50--90% relative reductions in distributional discrepancy compared to uncalibrated baselines.
AgentOpt v0.1 Technical Report: Client-Side Optimization for LLM-Based Agent
Apr 07, 2026AI agents are increasingly deployed in real-world applications, including systems such as Manus, OpenClaw, and coding agents. Existing research has primarily focused on \emph{server-side} efficiency, proposing methods such as caching, speculative execution, traffic scheduling, and load balancing to reduce the cost of serving agentic workloads. However, as users increasingly construct agents by composing local tools, remote APIs, and diverse models, an equally important optimization problem arises on the client side. Client-side optimization asks how developers should allocate the resources available to them, including model choice, local tools, and API budget across pipeline stages, subject to application-specific quality, cost, and latency constraints. Because these objectives depend on the task and deployment setting, they cannot be determined by server-side systems alone. We introduce AgentOpt, the first framework-agnostic Python package for client-side agent optimization. We first study model selection, a high-impact optimization lever in multi-step agent pipelines. Given a pipeline and a small evaluation set, the goal is to find the most cost-effective assignment of models to pipeline roles. This problem is consequential in practice: at matched accuracy, the cost gap between the best and worst model combinations can reach 13--32$\times$ in our experiments. To efficiently explore the exponentially growing combination space, AgentOpt implements eight search algorithms, including Arm Elimination, Epsilon-LUCB, Threshold Successive Elimination, and Bayesian Optimization. Across four benchmarks, Arm Elimination recovers near-optimal accuracy while reducing evaluation budget by 24--67\% relative to brute-force search on three of four tasks. Code and benchmark results available at https://agentoptimizer.github.io/agentopt/.
Quantifying Trust: Financial Risk Management for Trustworthy AI Agents
Apr 05, 2026Prior work on trustworthy AI emphasizes model-internal properties such as bias mitigation, adversarial robustness, and interpretability. As AI systems evolve into autonomous agents deployed in open environments and increasingly connected to payments or assets, the operational meaning of trust shifts to end-to-end outcomes: whether an agent completes tasks, follows user intent, and avoids failures that cause material or psychological harm. These risks are fundamentally product-level and cannot be eliminated by technical safeguards alone because agent behavior is inherently stochastic. To address this gap between model-level reliability and user-facing assurance, we propose a complementary framework based on risk management. Drawing inspiration from financial underwriting, we introduce the \textbf{Agentic Risk Standard (ARS)}, a payment settlement standard for AI-mediated transactions. ARS integrates risk assessment, underwriting, and compensation into a single transaction framework that protects users when interacting with agents. Under ARS, users receive predefined and contractually enforceable compensation in cases of execution failure, misalignment, or unintended outcomes. This shifts trust from an implicit expectation about model behavior to an explicit, measurable, and enforceable product guarantee. We also present a simulation study analyzing the social benefits of applying ARS to agentic transactions. ARS's implementation can be found at https://github.com/t54-labs/AgenticRiskStandard.
AI Agents for Inventory Control: Human-LLM-OR Complementarity
Feb 13, 2026Inventory control is a fundamental operations problem in which ordering decisions are traditionally guided by theoretically grounded operations research (OR) algorithms. However, such algorithms often rely on rigid modeling assumptions and can perform poorly when demand distributions shift or relevant contextual information is unavailable. Recent advances in large language models (LLMs) have generated interest in AI agents that can reason flexibly and incorporate rich contextual signals, but it remains unclear how best to incorporate LLM-based methods into traditional decision-making pipelines. We study how OR algorithms, LLMs, and humans can interact and complement each other in a multi-period inventory control setting. We construct InventoryBench, a benchmark of over 1,000 inventory instances spanning both synthetic and real-world demand data, designed to stress-test decision rules under demand shifts, seasonality, and uncertain lead times. Through this benchmark, we find that OR-augmented LLM methods outperform either method in isolation, suggesting that these methods are complementary rather than substitutes. We further investigate the role of humans through a controlled classroom experiment that embeds LLM recommendations into a human-in-the-loop decision pipeline. Contrary to prior findings that human-AI collaboration can degrade performance, we show that, on average, human-AI teams achieve higher profits than either humans or AI agents operating alone. Beyond this population-level finding, we formalize an individual-level complementarity effect and derive a distribution-free lower bound on the fraction of individuals who benefit from AI collaboration; empirically, we find this fraction to be substantial.
Speculative Actions: A Lossless Framework for Faster Agentic Systems
Oct 05, 2025Despite growing interest in AI agents across industry and academia, their execution in an environment is often slow, hampering training, evaluation, and deployment. For example, a game of chess between two state-of-the-art agents may take hours. A critical bottleneck is that agent behavior unfolds sequentially: each action requires an API call, and these calls can be time-consuming. Inspired by speculative execution in microprocessors and speculative decoding in LLM inference, we propose speculative actions, a lossless framework for general agentic systems that predicts likely actions using faster models, enabling multiple steps to be executed in parallel. We evaluate this framework across three agentic environments: gaming, e-commerce, web search, and a "lossy" extension for an operating systems environment. In all cases, speculative actions achieve substantial accuracy in next-action prediction (up to 55%), translating into significant reductions in end-to-end latency. Moreover, performance can be further improved through stronger guessing models, top-K action prediction, multi-step speculation, and uncertainty-aware optimization, opening a promising path toward deploying low-latency agentic systems in the real world.
AI Agents for Web Testing: A Case Study in the Wild
Sep 05, 2025Automated web testing plays a critical role in ensuring high-quality user experiences and delivering business value. Traditional approaches primarily focus on code coverage and load testing, but often fall short of capturing complex user behaviors, leaving many usability issues undetected. The emergence of large language models (LLM) and AI agents opens new possibilities for web testing by enabling human-like interaction with websites and a general awareness of common usability problems. In this work, we present WebProber, a prototype AI agent-based web testing framework. Given a URL, WebProber autonomously explores the website, simulating real user interactions, identifying bugs and usability issues, and producing a human-readable report. We evaluate WebProber through a case study of 120 academic personal websites, where it uncovered 29 usability issues--many of which were missed by traditional tools. Our findings highlight agent-based testing as a promising direction while outlining directions for developing next-generation, user-centered testing frameworks.
Twin-2K-500: A dataset for building digital twins of over 2,000 people based on their answers to over 500 questions
May 23, 2025LLM-based digital twin simulation, where large language models are used to emulate individual human behavior, holds great promise for research in AI, social science, and digital experimentation. However, progress in this area has been hindered by the scarcity of real, individual-level datasets that are both large and publicly available. This lack of high-quality ground truth limits both the development and validation of digital twin methodologies. To address this gap, we introduce a large-scale, public dataset designed to capture a rich and holistic view of individual human behavior. We survey a representative sample of $N = 2,058$ participants (average 2.42 hours per person) in the US across four waves with 500 questions in total, covering a comprehensive battery of demographic, psychological, economic, personality, and cognitive measures, as well as replications of behavioral economics experiments and a pricing survey. The final wave repeats tasks from earlier waves to establish a test-retest accuracy baseline. Initial analyses suggest the data are of high quality and show promise for constructing digital twins that predict human behavior well at the individual and aggregate levels. By making the full dataset publicly available, we aim to establish a valuable testbed for the development and benchmarking of LLM-based persona simulations. Beyond LLM applications, due to its unique breadth and scale the dataset also enables broad social science research, including studies of cross-construct correlations and heterogeneous treatment effects.
AdaKWS: Towards Robust Keyword Spotting with Test-Time Adaptation
May 20, 2025Spoken keyword spotting (KWS) aims to identify keywords in audio for wide applications, especially on edge devices. Current small-footprint KWS systems focus on efficient model designs. However, their inference performance can decline in unseen environments or noisy backgrounds. Test-time adaptation (TTA) helps models adapt to test samples without needing the original training data. In this study, we present AdaKWS, the first TTA method for robust KWS to the best of our knowledge. Specifically, 1) We initially optimize the model's confidence by selecting reliable samples based on prediction entropy minimization and adjusting the normalization statistics in each batch. 2) We introduce pseudo-keyword consistency (PKC) to identify critical, reliable features without overfitting to noise. Our experiments show that AdaKWS outperforms other methods across various conditions, including Gaussian noise and real-scenario noises. The code will be released in due course.
AnalyticKWS: Towards Exemplar-Free Analytic Class Incremental Learning for Small-footprint Keyword Spotting
May 17, 2025Keyword spotting (KWS) offers a vital mechanism to identify spoken commands in voice-enabled systems, where user demands often shift, requiring models to learn new keywords continually over time. However, a major problem is catastrophic forgetting, where models lose their ability to recognize earlier keywords. Although several continual learning methods have proven their usefulness for reducing forgetting, most existing approaches depend on storing and revisiting old data to combat catastrophic forgetting. Though effective, these methods face two practical challenges: 1) privacy risks from keeping user data and 2) large memory and time consumption that limit deployment on small devices. To address these issues, we propose an exemplar-free Analytic Continual Learning (AnalyticKWS) method that updates model parameters without revisiting earlier data. Inspired by efficient learning principles, AnalyticKWS computes a closed-form analytical solution for model updates and requires only a single epoch of adaptation for incoming keywords. AnalyticKWS demands fewer computational resources by avoiding gradient-based updates and does not store old data. By eliminating the need for back-propagation during incremental learning, the model remains lightweight and efficient. As a result, AnalyticKWS meets the challenges mentioned earlier and suits resource-limited settings well. Extensive experiments on various datasets and settings show that AnalyticKWS consistently outperforms existing continual learning methods.
Throughput-Optimal Scheduling Algorithms for LLM Inference and AI Agents
Apr 10, 2025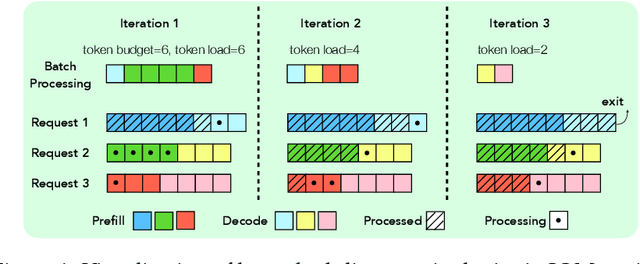
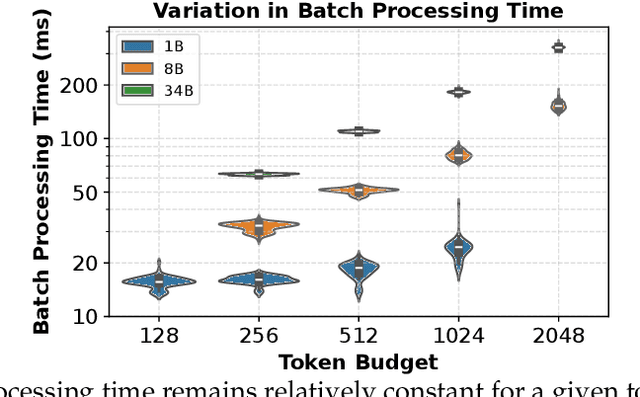
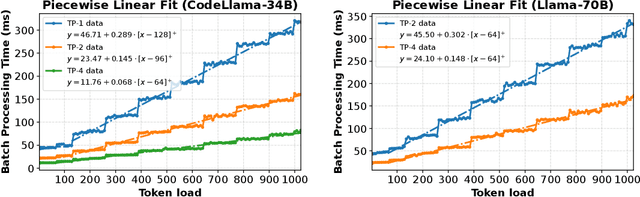
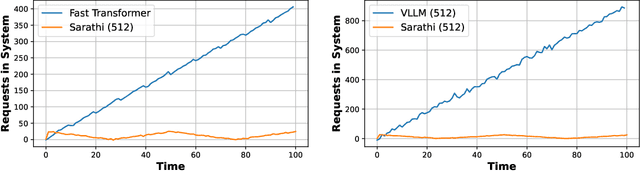
As demand for Large Language Models (LLMs) and AI agents rapidly grows, optimizing systems for efficient LLM inference becomes critical. While significant efforts have targeted system-level engineering, little is explored through a mathematical modeling and queuing perspective. In this paper, we aim to develop the queuing fundamentals for LLM inference, bridging the gap between queuing and LLM system communities. In particular, we study the throughput aspect in LLM inference systems. We prove that a large class of 'work-conserving' scheduling algorithms can achieve maximum throughput for both individual requests and AI agent workloads, highlighting 'work-conserving' as a key design principle in practice. Evaluations of real-world systems show that Orca and Sarathi-serve are throughput-optimal, reassuring practitioners, while FastTransformer and vanilla vLLM are not maximally stable and should be used with caution. Our results highlight the substantial benefits queuing community can offer in improving LLM inference systems and call for more interdisciplinary developments.