 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Mixture Optimization: A Multi-fidelity Multi-scale Bayesian Framework
Mar 26, 2025Careful curation of data sources can significantly improve the performance of LLM pre-training, but predominant approaches rely heavily on intuition or costly trial-and-error, making them difficult to generalize across different data domains and downstream tasks. Although scaling laws can provide a principled and general approach for data curation, standard deterministic extrapolation from small-scale experiments to larger scales requires strong assumptions on the reliability of such extrapolation, whose brittleness has been highlighted in prior works. In this paper, we introduce a $\textit{probabilistic extrapolation framework}$ for data mixture optimization that avoids rigid assumptions and explicitly models the uncertainty in performance across decision variables. We formulate data curation as a sequential decision-making problem$\unicode{x2013}$multi-fidelity, multi-scale Bayesian optimization$\unicode{x2013}$where $\{$data mixtures, model scale, training steps$\}$ are adaptively selected to balance training cost and potential information gain. Our framework naturally gives rise to algorithm prototypes that leverage noisy information from inexpensive experiments to systematically inform costly training decisions. To accelerate methodological progress, we build a simulator based on 472 language model pre-training runs with varying data compositions from the SlimPajama dataset. We observe that even simple kernels and acquisition functions can enable principled decisions across training models from 20M to 1B parameters and achieve $\textbf{2.6x}$ and $\textbf{3.3x}$ speedups compared to multi-fidelity BO and random search baselines. Taken together, our framework underscores potential efficiency gains achievable by developing principled and transferable data mixture optimization methods.
PersonalLLM: Tailoring LLMs to Individual Preferences
Sep 30, 2024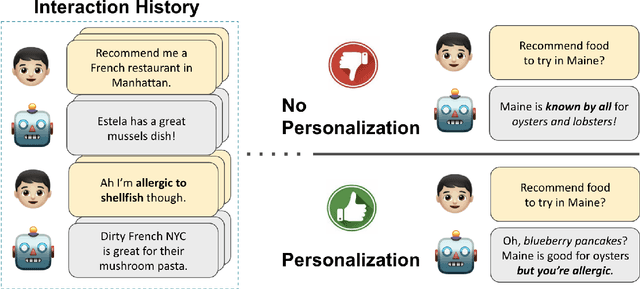



As LLMs become capable of complex tasks, there is growing potential for personalized interactions tailored to the subtle and idiosyncratic preferences of the user. We present a public benchmark, PersonalLLM, focusing on adapting LLMs to provide maximal benefits for a particular user. Departing from existing alignment benchmarks that implicitly assume uniform preferences, we curate open-ended prompts paired with many high-quality answers over which users would be expected to display heterogeneous latent preferences. Instead of persona-prompting LLMs based on high-level attributes (e.g., user's race or response length), which yields homogeneous preferences relative to humans, we develop a method that can simulate a large user base with diverse preferences from a set of pre-trained reward models. Our dataset and generated personalities offer an innovative testbed for developing personalization algorithms that grapple with continual data sparsity--few relevant feedback from the particular user--by leveraging historical data from other (similar) users. We explore basic in-context learning and meta-learning baselines to illustrate the utility of PersonalLLM and highlight the need for future methodological development. Our dataset is available at https://huggingface.co/datasets/namkoong-lab/PersonalLLM