 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Discrimination Testing for Generative AI
Dec 30, 2024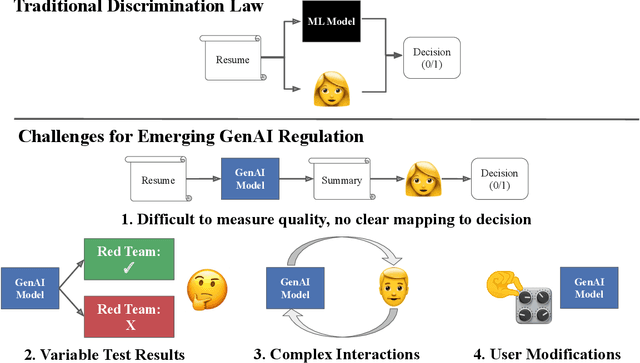

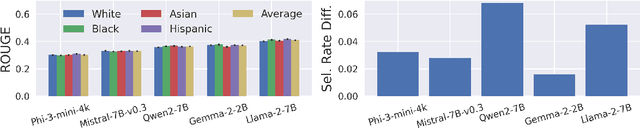
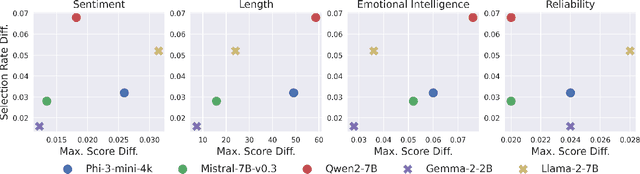
Generative AI (GenAI) models present new challenges in regulating against discriminatory behavior. In this paper, we argue that GenAI fairness research still has not met these challenges; instead, a significant gap remains between existing bias assessment methods and regulatory goals. This leads to ineffective regulation that can allow deployment of reportedly fair, yet actually discriminatory, GenAI systems. Towards remedying this problem, we connect the legal and technical literature around GenAI bias evaluation and identify areas of misalignment. Through four case studies, we demonstrate how this misalignment between fairness testing techniques and regulatory goals can result in discriminatory outcomes in real-world deployments, especially in adaptive or complex environments. We offer practical recommendations for improving discrimination testing to better align with regulatory goals and enhance the reliability of fairness assessments in future deployments.
Improving Predictor Reliability with Selective Recalibration
Oct 07, 2024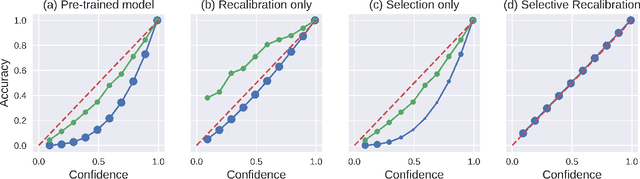
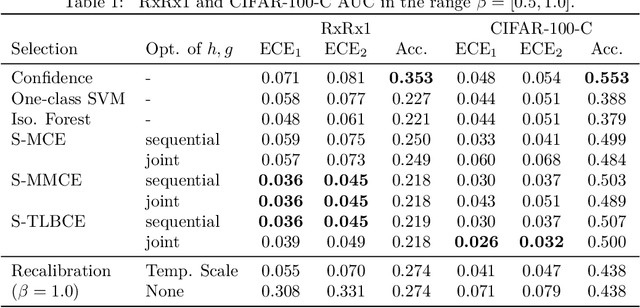
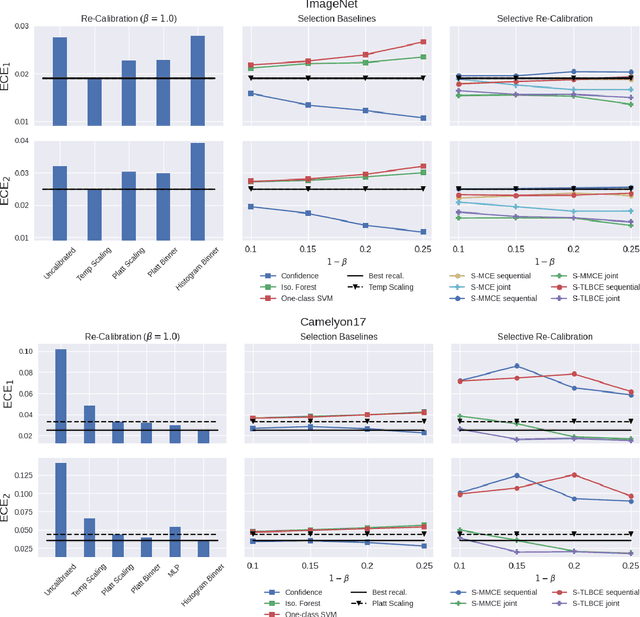
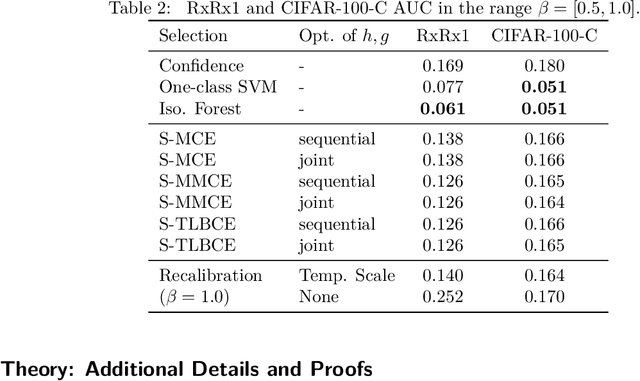
A reliable deep learning system should be able to accurately express its confidence with respect to its predictions, a quality known as calibration. One of the most effective ways to produce reliable confidence estimates with a pre-trained model is by applying a post-hoc recalibration method. Popular recalibration methods like temperature scaling are typically fit on a small amount of data and work in the model's output space, as opposed to the more expressive feature embedding space, and thus usually have only one or a handful of parameters. However, the target distribution to which they are applied is often complex and difficult to fit well with such a function. To this end we propose \textit{selective recalibration}, where a selection model learns to reject some user-chosen proportion of the data in order to allow the recalibrator to focus on regions of the input space that can be well-captured by such a model. We provide theoretical analysis to motivate our algorithm, and test our method through comprehensive experiments on difficult medical imaging and zero-shot classification tasks. Our results show that selective recalibration consistently leads to significantly lower calibration error than a wide range of selection and recalibration baselines.
PersonalLLM: Tailoring LLMs to Individual Preferences
Sep 30, 2024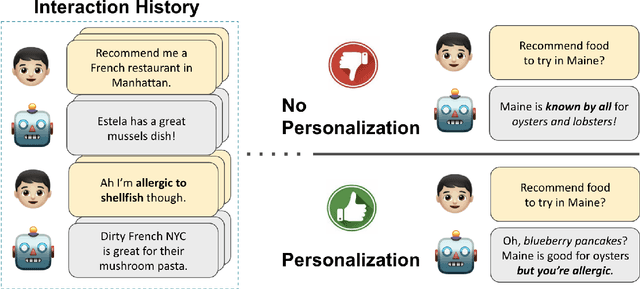



As LLMs become capable of complex tasks, there is growing potential for personalized interactions tailored to the subtle and idiosyncratic preferences of the user. We present a public benchmark, PersonalLLM, focusing on adapting LLMs to provide maximal benefits for a particular user. Departing from existing alignment benchmarks that implicitly assume uniform preferences, we curate open-ended prompts paired with many high-quality answers over which users would be expected to display heterogeneous latent preferences. Instead of persona-prompting LLMs based on high-level attributes (e.g., user's race or response length), which yields homogeneous preferences relative to humans, we develop a method that can simulate a large user base with diverse preferences from a set of pre-trained reward models. Our dataset and generated personalities offer an innovative testbed for developing personalization algorithms that grapple with continual data sparsity--few relevant feedback from the particular user--by leveraging historical data from other (similar) users. We explore basic in-context learning and meta-learning baselines to illustrate the utility of PersonalLLM and highlight the need for future methodological development. Our dataset is available at https://huggingface.co/datasets/namkoong-lab/PersonalLLM
Prompt Risk Control: A Rigorous Framework for Responsible Deployment of Large Language Models
Nov 22, 2023The recent explosion in the capabilities of large language models has led to a wave of interest in how best to prompt a model to perform a given task. While it may be tempting to simply choose a prompt based on average performance on a validation set, this can lead to a deployment where unexpectedly poor responses are generated, especially for the worst-off users. To mitigate this prospect, we propose Prompt Risk Control, a lightweight framework for selecting a prompt based on rigorous upper bounds on families of informative risk measures. We offer methods for producing bounds on a diverse set of metrics, including quantities that measure worst-case responses and disparities in generation quality across the population of users. In addition, we extend the underlying statistical bounding techniques to accommodate the possibility of distribution shifts in deployment. Experiments on applications such as open-ended chat, medical question summarization, and code generation highlight how such a framework can foster responsible deployment by reducing the risk of the worst outcomes.
Distribution-Free Statistical Dispersion Control for Societal Applications
Sep 25, 2023Explicit finite-sample statistical guarantees on model performance are an important ingredient in responsible machine learning. Previous work has focused mainly on bounding either the expected loss of a predictor or the probability that an individual prediction will incur a loss value in a specified range. However, for many high-stakes applications, it is crucial to understand and control the dispersion of a loss distribution, or the extent to which different members of a population experience unequal effects of algorithmic decisions. We initiate the study of distribution-free control of statistical dispersion measures with societal implications and propose a simple yet flexible framework that allows us to handle a much richer class of statistical functionals beyond previous work. Our methods are verified through experiments in toxic comment detection, medical imaging, and film recommendation.
Quantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions
Dec 27, 2022



Rigorous guarantees about the performance of predictive algorithms are necessary in order to ensure their responsible use. Previous work has largely focused on bounding the expected loss of a predictor, but this is not sufficient in many risk-sensitive applications where the distribution of errors is important. In this work, we propose a flexible framework to produce a family of bounds on quantiles of the loss distribution incurred by a predictor. Our method takes advantage of the order statistics of the observed loss values rather than relying on the sample mean alone. We show that a quantile is an informative way of quantifying predictive performance, and that our framework applies to a variety of quantile-based metrics, each targeting important subsets of the data distribution. We analyze the theoretical properties of our proposed method and demonstrate its ability to rigorously control loss quantiles on several real-world datasets.