 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction as Bayesian Quadrature
Feb 18, 2025As machine learning-based prediction systems are increasingly used in high-stakes situations, it is important to understand how such predictive models will perform upon deployment. Distribution-free uncertainty quantification techniques such as conformal prediction provide guarantees about the loss black-box models will incur even when the details of the models are hidden. However, such methods are based on frequentist probability, which unduly limits their applicability. We revisit the central aspects of conformal prediction from a Bayesian perspective and thereby illuminate the shortcomings of frequentist guarantees. We propose a practical alternative based on Bayesian quadrature that provides interpretable guarantees and offers a richer representation of the likely range of losses to be observed at test time.
Improving Predictor Reliability with Selective Recalibration
Oct 07, 2024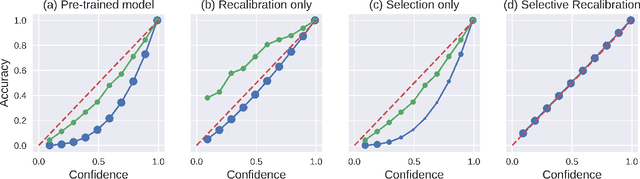
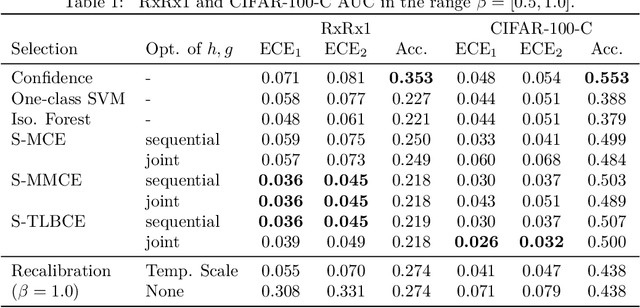
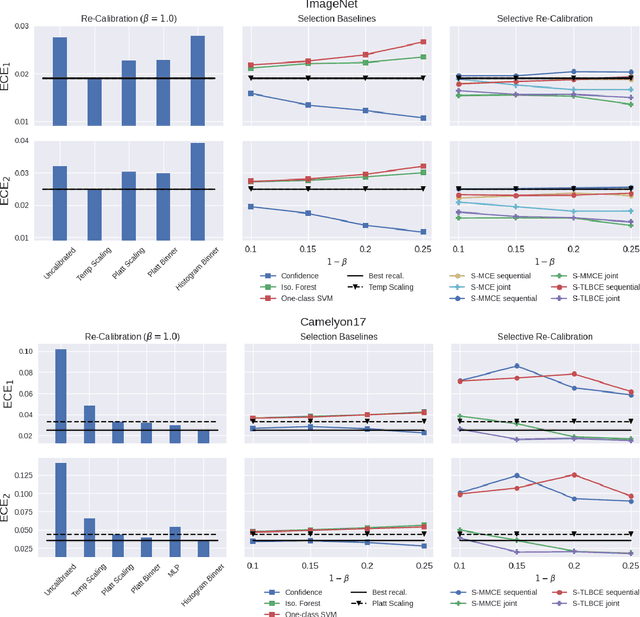
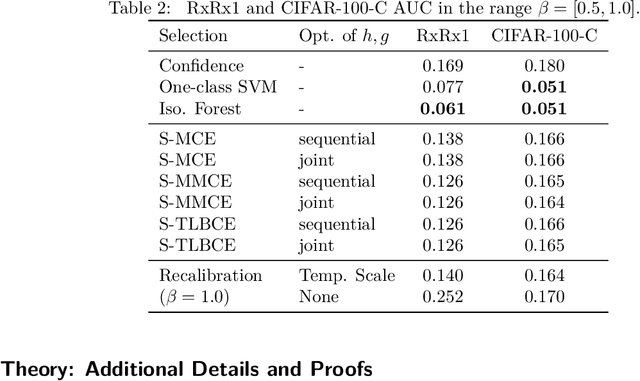
A reliable deep learning system should be able to accurately express its confidence with respect to its predictions, a quality known as calibration. One of the most effective ways to produce reliable confidence estimates with a pre-trained model is by applying a post-hoc recalibration method. Popular recalibration methods like temperature scaling are typically fit on a small amount of data and work in the model's output space, as opposed to the more expressive feature embedding space, and thus usually have only one or a handful of parameters. However, the target distribution to which they are applied is often complex and difficult to fit well with such a function. To this end we propose \textit{selective recalibration}, where a selection model learns to reject some user-chosen proportion of the data in order to allow the recalibrator to focus on regions of the input space that can be well-captured by such a model. We provide theoretical analysis to motivate our algorithm, and test our method through comprehensive experiments on difficult medical imaging and zero-shot classification tasks. Our results show that selective recalibration consistently leads to significantly lower calibration error than a wide range of selection and recalibration baselines.
A Metalearned Neural Circuit for Nonparametric Bayesian Inference
Nov 24, 2023



Most applications of machine learning to classification assume a closed set of balanced classes. This is at odds with the real world, where class occurrence statistics often follow a long-tailed power-law distribution and it is unlikely that all classes are seen in a single sample. Nonparametric Bayesian models naturally capture this phenomenon, but have significant practical barriers to widespread adoption, namely implementation complexity and computational inefficiency. To address this, we present a method for extracting the inductive bias from a nonparametric Bayesian model and transferring it to an artificial neural network. By simulating data with a nonparametric Bayesian prior, we can metalearn a sequence model that performs inference over an unlimited set of classes. After training, this "neural circuit" has distilled the corresponding inductive bias and can successfully perform sequential inference over an open set of classes. Our experimental results show that the metalearned neural circuit achieves comparable or better performance than particle filter-based methods for inference in these models while being faster and simpler to use than methods that explicitly incorporate Bayesian nonparametric inference.
Prompt Risk Control: A Rigorous Framework for Responsible Deployment of Large Language Models
Nov 22, 2023The recent explosion in the capabilities of large language models has led to a wave of interest in how best to prompt a model to perform a given task. While it may be tempting to simply choose a prompt based on average performance on a validation set, this can lead to a deployment where unexpectedly poor responses are generated, especially for the worst-off users. To mitigate this prospect, we propose Prompt Risk Control, a lightweight framework for selecting a prompt based on rigorous upper bounds on families of informative risk measures. We offer methods for producing bounds on a diverse set of metrics, including quantities that measure worst-case responses and disparities in generation quality across the population of users. In addition, we extend the underlying statistical bounding techniques to accommodate the possibility of distribution shifts in deployment. Experiments on applications such as open-ended chat, medical question summarization, and code generation highlight how such a framework can foster responsible deployment by reducing the risk of the worst outcomes.
Implicit Maximum a Posteriori Filtering via Adaptive Optimization
Nov 17, 2023Bayesian filtering approximates the true underlying behavior of a time-varying system by inverting an explicit generative model to convert noisy measurements into state estimates. This process typically requires either storage, inversion, and multiplication of large matrices or Monte Carlo estimation, neither of which are practical in high-dimensional state spaces such as the weight spaces of artificial neural networks. Here, we frame the standard Bayesian filtering problem as optimization over a time-varying objective. Instead of maintaining matrices for the filtering equations or simulating particles, we specify an optimizer that defines the Bayesian filter implicitly. In the linear-Gaussian setting, we show that every Kalman filter has an equivalent formulation using K steps of gradient descent. In the nonlinear setting, our experiments demonstrate that our framework results in filters that are effective, robust, and scalable to high-dimensional systems, comparing well against the standard toolbox of Bayesian filtering solutions. We suggest that it is easier to fine-tune an optimizer than it is to specify the correct filtering equations, making our framework an attractive option for high-dimensional filtering problems.
Distribution-Free Statistical Dispersion Control for Societal Applications
Sep 25, 2023Explicit finite-sample statistical guarantees on model performance are an important ingredient in responsible machine learning. Previous work has focused mainly on bounding either the expected loss of a predictor or the probability that an individual prediction will incur a loss value in a specified range. However, for many high-stakes applications, it is crucial to understand and control the dispersion of a loss distribution, or the extent to which different members of a population experience unequal effects of algorithmic decisions. We initiate the study of distribution-free control of statistical dispersion measures with societal implications and propose a simple yet flexible framework that allows us to handle a much richer class of statistical functionals beyond previous work. Our methods are verified through experiments in toxic comment detection, medical imaging, and film recommendation.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023



Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
Quantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions
Dec 27, 2022



Rigorous guarantees about the performance of predictive algorithms are necessary in order to ensure their responsible use. Previous work has largely focused on bounding the expected loss of a predictor, but this is not sufficient in many risk-sensitive applications where the distribution of errors is important. In this work, we propose a flexible framework to produce a family of bounds on quantiles of the loss distribution incurred by a predictor. Our method takes advantage of the order statistics of the observed loss values rather than relying on the sample mean alone. We show that a quantile is an informative way of quantifying predictive performance, and that our framework applies to a variety of quantile-based metrics, each targeting important subsets of the data distribution. We analyze the theoretical properties of our proposed method and demonstrate its ability to rigorously control loss quantiles on several real-world datasets.