 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution Bias in Large Language Models
Apr 06, 2026As Large Language Models (LLMs) are increasingly used to support search and information retrieval, it is critical that they accurately attribute content to its original authors. In this work, we introduce AttriBench, the first fame- and demographically-balanced quote attribution benchmark dataset. Through explicitly balancing author fame and demographics, AttriBench enables controlled investigation of demographic bias in quote attribution. Using this dataset, we evaluate 11 widely used LLMs across different prompt settings and find that quote attribution remains a challenging task even for frontier models. We observe large and systematic disparities in attribution accuracy between race, gender, and intersectional groups. We further introduce and investigate suppression, a distinct failure mode in which models omit attribution entirely, even when the model has access to authorship information. We find that suppression is widespread and unevenly distributed across demographic groups, revealing systematic biases not captured by standard accuracy metrics. Our results position quote attribution as a benchmark for representational fairness in LLMs.
Multilingual Prompting for Improving LLM Generation Diversity
May 21, 2025



Large Language Models (LLMs) are known to lack cultural representation and overall diversity in their generations, from expressing opinions to answering factual questions. To mitigate this problem, we propose multilingual prompting: a prompting method which generates several variations of a base prompt with added cultural and linguistic cues from several cultures, generates responses, and then combines the results. Building on evidence that LLMs have language-specific knowledge, multilingual prompting seeks to increase diversity by activating a broader range of cultural knowledge embedded in model training data. Through experiments across multiple models (GPT-4o, GPT-4o-mini, LLaMA 70B, and LLaMA 8B), we show that multilingual prompting consistently outperforms existing diversity-enhancing techniques such as high-temperature sampling, step-by-step recall, and personas prompting. Further analyses show that the benefits of multilingual prompting vary with language resource level and model size, and that aligning the prompting language with the cultural cues reduces hallucination about culturally-specific information.
Be Intentional About Fairness!: Fairness, Size, and Multiplicity in the Rashomon Set
Jan 26, 2025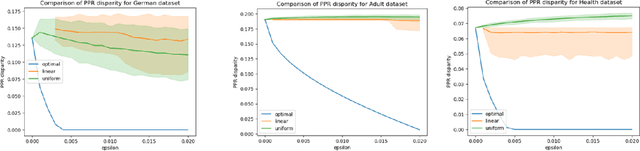
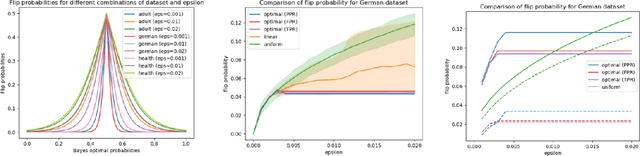
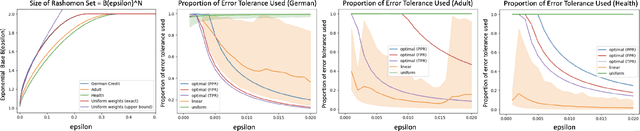
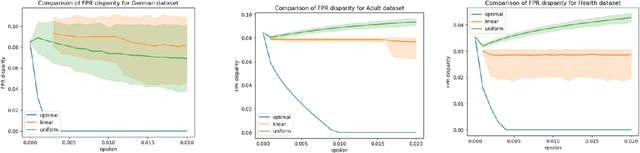
When selecting a model from a set of equally performant models, how much unfairness can you really reduce? Is it important to be intentional about fairness when choosing among this set, or is arbitrarily choosing among the set of ''good'' models good enough? Recent work has highlighted that the phenomenon of model multiplicity-where multiple models with nearly identical predictive accuracy exist for the same task-has both positive and negative implications for fairness, from strengthening the enforcement of civil rights law in AI systems to showcasing arbitrariness in AI decision-making. Despite the enormous implications of model multiplicity, there is little work that explores the properties of sets of equally accurate models, or Rashomon sets, in general. In this paper, we present five main theoretical and methodological contributions which help us to understand the relatively unexplored properties of the Rashomon set, in particular with regards to fairness. Our contributions include methods for efficiently sampling models from this set and techniques for identifying the fairest models according to key fairness metrics such as statistical parity. We also derive the probability that an individual's prediction will be flipped within the Rashomon set, as well as expressions for the set's size and the distribution of error tolerance used across models. These results lead to policy-relevant takeaways, such as the importance of intentionally looking for fair models within the Rashomon set, and understanding which individuals or groups may be more susceptible to arbitrary decisions.
Towards Effective Discrimination Testing for Generative AI
Dec 30, 2024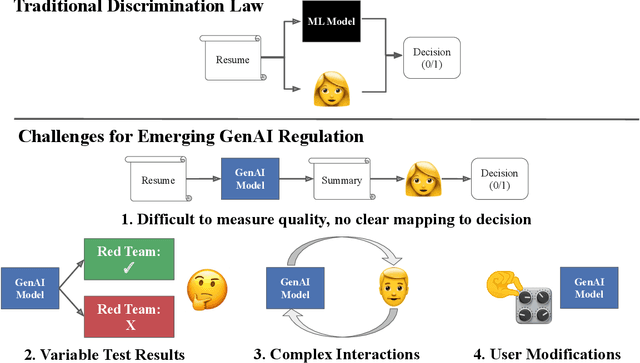

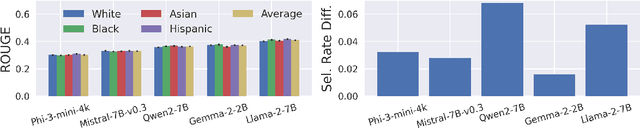
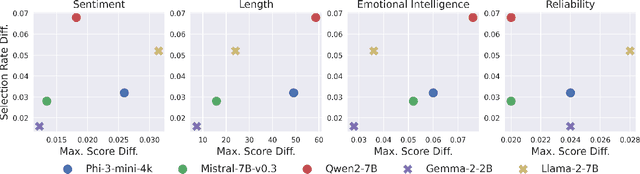
Generative AI (GenAI) models present new challenges in regulating against discriminatory behavior. In this paper, we argue that GenAI fairness research still has not met these challenges; instead, a significant gap remains between existing bias assessment methods and regulatory goals. This leads to ineffective regulation that can allow deployment of reportedly fair, yet actually discriminatory, GenAI systems. Towards remedying this problem, we connect the legal and technical literature around GenAI bias evaluation and identify areas of misalignment. Through four case studies, we demonstrate how this misalignment between fairness testing techniques and regulatory goals can result in discriminatory outcomes in real-world deployments, especially in adaptive or complex environments. We offer practical recommendations for improving discrimination testing to better align with regulatory goals and enhance the reliability of fairness assessments in future deployments.
Generative Monoculture in Large Language Models
Jul 02, 2024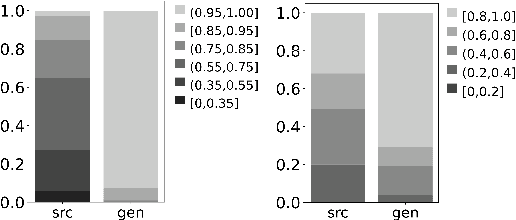

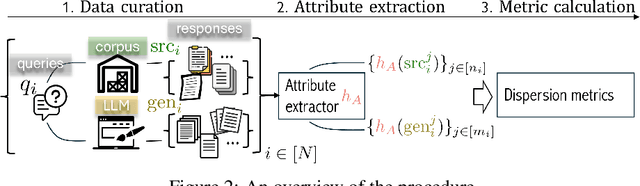

We introduce {\em generative monoculture}, a behavior observed in large language models (LLMs) characterized by a significant narrowing of model output diversity relative to available training data for a given task: for example, generating only positive book reviews for books with a mixed reception. While in some cases, generative monoculture enhances performance (e.g., LLMs more often produce efficient code), the dangers are exacerbated in others (e.g., LLMs refuse to share diverse opinions). As LLMs are increasingly used in high-impact settings such as education and web search, careful maintenance of LLM output diversity is essential to ensure a variety of facts and perspectives are preserved over time. We experimentally demonstrate the prevalence of generative monoculture through analysis of book review and code generation tasks, and find that simple countermeasures such as altering sampling or prompting strategies are insufficient to mitigate the behavior. Moreover, our results suggest that the root causes of generative monoculture are likely embedded within the LLM's alignment processes, suggesting a need for developing fine-tuning paradigms that preserve or promote diversity.
Estimating and Implementing Conventional Fairness Metrics With Probabilistic Protected Features
Oct 02, 2023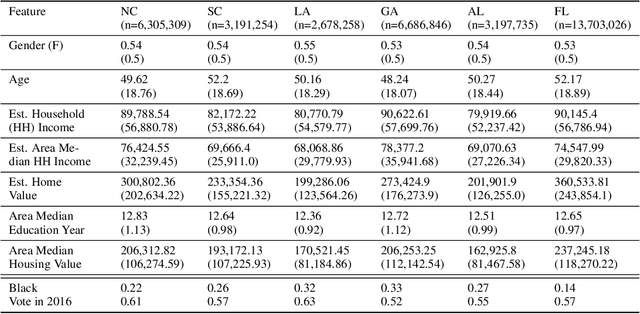
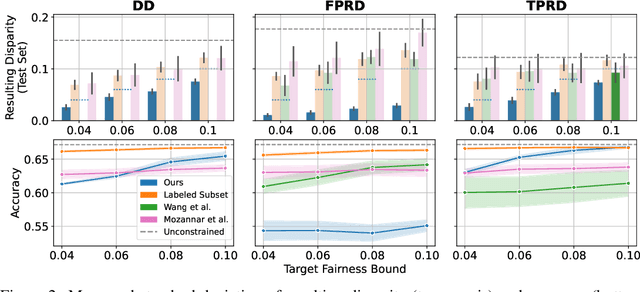
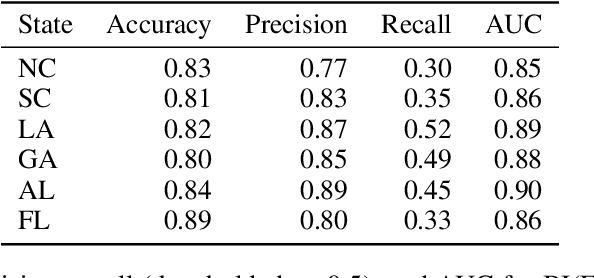
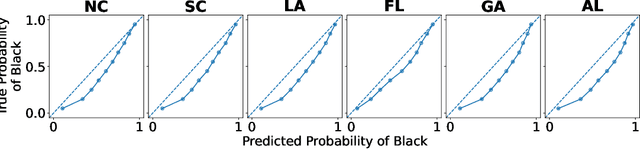
The vast majority of techniques to train fair models require access to the protected attribute (e.g., race, gender), either at train time or in production. However, in many important applications this protected attribute is largely unavailable. In this paper, we develop methods for measuring and reducing fairness violations in a setting with limited access to protected attribute labels. Specifically, we assume access to protected attribute labels on a small subset of the dataset of interest, but only probabilistic estimates of protected attribute labels (e.g., via Bayesian Improved Surname Geocoding) for the rest of the dataset. With this setting in mind, we propose a method to estimate bounds on common fairness metrics for an existing model, as well as a method for training a model to limit fairness violations by solving a constrained non-convex optimization problem. Unlike similar existing approaches, our methods take advantage of contextual information -- specifically, the relationships between a model's predictions and the probabilistic prediction of protected attributes, given the true protected attribute, and vice versa -- to provide tighter bounds on the true disparity. We provide an empirical illustration of our methods using voting data. First, we show our measurement method can bound the true disparity up to 5.5x tighter than previous methods in these applications. Then, we demonstrate that our training technique effectively reduces disparity while incurring lesser fairness-accuracy trade-offs than other fair optimization methods with limited access to protected attributes.
Toward Operationalizing Pipeline-aware ML Fairness: A Research Agenda for Developing Practical Guidelines and Tools
Sep 29, 2023



While algorithmic fairness is a thriving area of research, in practice, mitigating issues of bias often gets reduced to enforcing an arbitrarily chosen fairness metric, either by enforcing fairness constraints during the optimization step, post-processing model outputs, or by manipulating the training data. Recent work has called on the ML community to take a more holistic approach to tackle fairness issues by systematically investigating the many design choices made through the ML pipeline, and identifying interventions that target the issue's root cause, as opposed to its symptoms. While we share the conviction that this pipeline-based approach is the most appropriate for combating algorithmic unfairness on the ground, we believe there are currently very few methods of \emph{operationalizing} this approach in practice. Drawing on our experience as educators and practitioners, we first demonstrate that without clear guidelines and toolkits, even individuals with specialized ML knowledge find it challenging to hypothesize how various design choices influence model behavior. We then consult the fair-ML literature to understand the progress to date toward operationalizing the pipeline-aware approach: we systematically collect and organize the prior work that attempts to detect, measure, and mitigate various sources of unfairness through the ML pipeline. We utilize this extensive categorization of previous contributions to sketch a research agenda for the community. We hope this work serves as the stepping stone toward a more comprehensive set of resources for ML researchers, practitioners, and students interested in exploring, designing, and testing pipeline-oriented approaches to algorithmic fairness.
Algorithmic Fairness and Vertical Equity: Income Fairness with IRS Tax Audit Models
Jun 20, 2022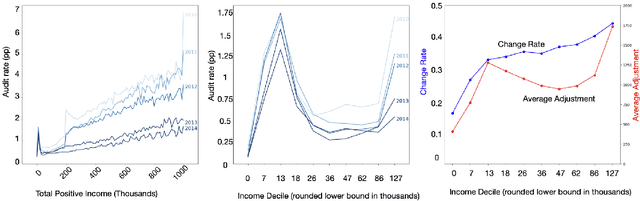
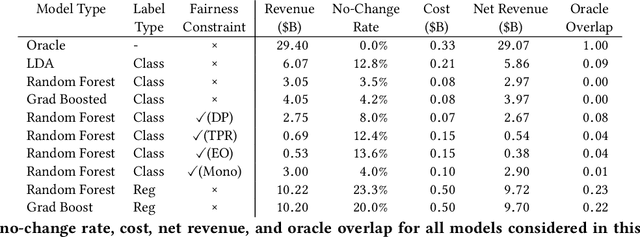
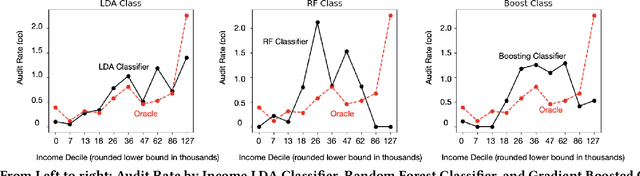
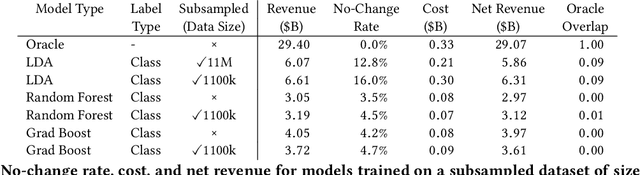
This study examines issues of algorithmic fairness in the context of systems that inform tax audit selection by the United States Internal Revenue Service (IRS). While the field of algorithmic fairness has developed primarily around notions of treating like individuals alike, we instead explore the concept of vertical equity -- appropriately accounting for relevant differences across individuals -- which is a central component of fairness in many public policy settings. Applied to the design of the U.S. individual income tax system, vertical equity relates to the fair allocation of tax and enforcement burdens across taxpayers of different income levels. Through a unique collaboration with the Treasury Department and IRS, we use access to anonymized individual taxpayer microdata, risk-selected audits, and random audits from 2010-14 to study vertical equity in tax administration. In particular, we assess how the use of modern machine learning methods for selecting audits may affect vertical equity. First, we show how the use of more flexible machine learning (classification) methods -- as opposed to simpler models -- shifts audit burdens from high to middle-income taxpayers. Second, we show that while existing algorithmic fairness techniques can mitigate some disparities across income, they can incur a steep cost to performance. Third, we show that the choice of whether to treat risk of underreporting as a classification or regression problem is highly consequential. Moving from classification to regression models to predict underreporting shifts audit burden substantially toward high income individuals, while increasing revenue. Last, we explore the role of differential audit cost in shaping the audit distribution. We show that a narrow focus on return-on-investment can undermine vertical equity. Our results have implications for the design of algorithmic tools across the public sector.
Selective Ensembles for Consistent Predictions
Nov 16, 2021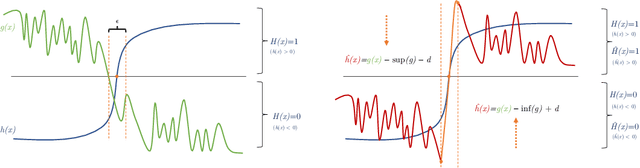



Recent work has shown that models trained to the same objective, and which achieve similar measures of accuracy on consistent test data, may nonetheless behave very differently on individual predictions. This inconsistency is undesirable in high-stakes contexts, such as medical diagnosis and finance. We show that this inconsistent behavior extends beyond predictions to feature attributions, which may likewise have negative implications for the intelligibility of a model, and one's ability to find recourse for subjects. We then introduce selective ensembles to mitigate such inconsistencies by applying hypothesis testing to the predictions of a set of models trained using randomly-selected starting conditions; importantly, selective ensembles can abstain in cases where a consistent outcome cannot be achieved up to a specified confidence level. We prove that that prediction disagreement between selective ensembles is bounded, and empirically demonstrate that selective ensembles achieve consistent predictions and feature attributions while maintaining low abstention rates. On several benchmark datasets, selective ensembles reach zero inconsistently predicted points, with abstention rates as low 1.5%.
Consistent Counterfactuals for Deep Models
Oct 06, 2021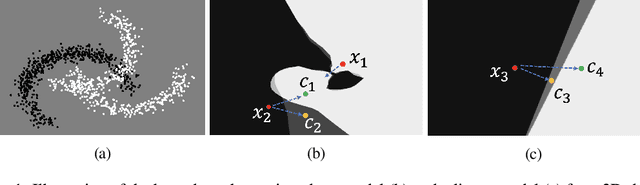
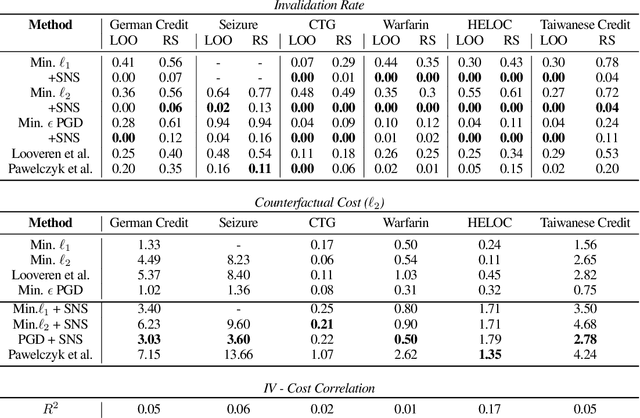
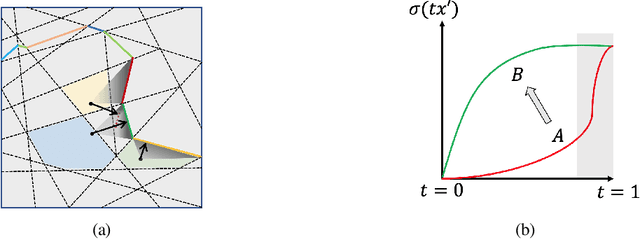
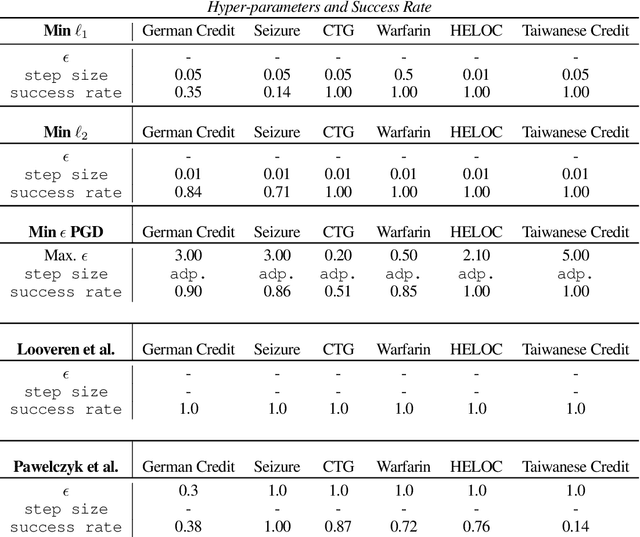
Counterfactual examples are one of the most commonly-cited methods for explaining the predictions of machine learning models in key areas such as finance and medical diagnosis. Counterfactuals are often discussed under the assumption that the model on which they will be used is static, but in deployment models may be periodically retrained or fine-tuned. This paper studies the consistency of model prediction on counterfactual examples in deep networks under small changes to initial training conditions, such as weight initialization and leave-one-out variations in data, as often occurs during model deployment. We demonstrate experimentally that counterfactual examples for deep models are often inconsistent across such small changes, and that increasing the cost of the counterfactual, a stability-enhancing mitigation suggested by prior work in the context of simpler models, is not a reliable heuristic in deep networks. Rather, our analysis shows that a model's local Lipschitz continuity around the counterfactual is key to its consistency across related models. To this end, we propose Stable Neighbor Search as a way to generate more consistent counterfactual explanations, and illustrate the effectiveness of this approach on several benchmark datasets.