 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPD-100K: Towards Generalizable and Fine-grained Visual Privacy Protection
May 11, 2026Privacy protection has become a critical requirement in the era of ubiquitous visual data sharing, imposing higher demands on efficient and robust privacy detection algorithms. However, current robust detection models are severely hindered by the lack of comprehensive datasets. Existing privacy-oriented datasets often suffer from limited scale, coarse-grained annotations, and narrow domain coverage, failing to capture the intricate details of sensitive information in realworld environments. To bridge this gap, we present a large-scale, fine-grained Visual Privacy Dataset (VPD-100K), designed to facilitate generalized privacy detection. We establish a holistic taxonomy comprising four primary domains: Human Presence, On-Screen Personally Identifiable Information (PII), Physical Identifiers, and Location Indicators, containing 100,000 images annotated with 33 fine-grained classes and over 190,000 object instances. Statistical analysis reveals that our dataset features long-tailed distributions, small object scales, and high visual complexity. These characteristics make the dataset particularly valuable for demanding, unconstrained applications such as live streaming, where actors frequently face unintentional, realtime information leakage. Furthermore, we design an effective frequency-enhanced lightweight module consisting of frequency-domain attention fusion and adaptive spectral gating mechanism that breaks the limitations of spatial pixel intensity to better capture the subtle details of sensitive information. Extensive experiments conducted on both diverse image and streaming videos benchmarks consistently demonstrate the effectiveness of our VPD-100K dataset and the wellcurated frequency mechanism. The code and dataset are available at https://vpd-100k.github.io/.
Mobile GUI Agent Privacy Personalization with Trajectory Induced Preference Optimization
Apr 13, 2026Mobile GUI agents powered by Multimodal Large Language Models (MLLMs) can execute complex tasks on mobile devices. Despite this progress, most existing systems still optimize task success or efficiency, neglecting users' privacy personalization. In this paper, we study the often-overlooked problem of agent personalization. We observe that personalization can induce systematic structural heterogeneity in execution trajectories. For example, privacy-first users often prefer protective actions, e.g., refusing permissions, logging out, and minimizing exposure, leading to logically different execution trajectories from utility-first users. Such variable-length and structurally different trajectories make standard preference optimization unstable and less informative. To address this issue, we propose Trajectory Induced Preference Optimization (TIPO), which uses preference-intensity weighting to emphasize key privacy-related steps and padding gating to suppress alignment noise. Results on our Privacy Preference Dataset show that TIPO improves persona alignment and distinction while preserving strong task executability, achieving 65.60% SR, 46.22 Compliance, and 66.67% PD, outperforming existing optimization methods across various GUI tasks. The code and dataset will be publicly released at https://github.com/Zhixin-L/TIPO.
Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Jan 13, 2026CAPTCHAs are widely used by websites to block bots and spam by presenting challenges that are easy for humans but difficult for automated programs to solve. To improve accessibility, audio CAPTCHAs are designed to complement visual ones. However, the robustness of audio CAPTCHAs against advanced Large Audio Language Models (LALMs) and Automatic Speech Recognition (ASR) models remains unclear. In this paper, we introduce AI-CAPTCHA, a unified framework that offers (i) an evaluation framework, ACEval, which includes advanced LALM- and ASR-based solvers, and (ii) a novel audio CAPTCHA approach, IllusionAudio, leveraging audio illusions. Through extensive evaluations of seven widely deployed audio CAPTCHAs, we show that most existing methods can be solved with high success rates by advanced LALMs and ASR models, exposing critical security weaknesses. To address these vulnerabilities, we design a new audio CAPTCHA approach, IllusionAudio, which exploits perceptual illusion cues rooted in human auditory mechanisms. Extensive experiments demonstrate that our method defeats all tested LALM- and ASR-based attacks while achieving a 100% human pass rate, significantly outperforming existing audio CAPTCHA methods.
Mind the Third Eye! Benchmarking Privacy Awareness in MLLM-powered Smartphone Agents
Aug 27, 2025



Smartphones bring significant convenience to users but also enable devices to extensively record various types of personal information. Existing smartphone agents powered by Multimodal Large Language Models (MLLMs) have achieved remarkable performance in automating different tasks. However, as the cost, these agents are granted substantial access to sensitive users' personal information during this operation. To gain a thorough understanding of the privacy awareness of these agents, we present the first large-scale benchmark encompassing 7,138 scenarios to the best of our knowledge. In addition, for privacy context in scenarios, we annotate its type (e.g., Account Credentials), sensitivity level, and location. We then carefully benchmark seven available mainstream smartphone agents. Our results demonstrate that almost all benchmarked agents show unsatisfying privacy awareness (RA), with performance remaining below 60% even with explicit hints. Overall, closed-source agents show better privacy ability than open-source ones, and Gemini 2.0-flash achieves the best, achieving an RA of 67%. We also find that the agents' privacy detection capability is highly related to scenario sensitivity level, i.e., the scenario with a higher sensitivity level is typically more identifiable. We hope the findings enlighten the research community to rethink the unbalanced utility-privacy tradeoff about smartphone agents. Our code and benchmark are available at https://zhixin-l.github.io/SAPA-Bench.
Deployability-Centric Infrastructure-as-Code Generation: An LLM-based Iterative Framework
Jun 05, 2025Infrastructure-as-Code (IaC) generation holds significant promise for automating cloud infrastructure provisioning. Recent advances in Large Language Models (LLMs) present a promising opportunity to democratize IaC development by generating deployable infrastructure templates from natural language descriptions, but current evaluation focuses on syntactic correctness while ignoring deployability, the fatal measure of IaC template utility. We address this gap through two contributions: (1) IaCGen, an LLM-based deployability-centric framework that uses iterative feedback mechanism to generate IaC templates, and (2) DPIaC-Eval, a deployability-centric IaC template benchmark consists of 153 real-world scenarios that can evaluate syntax, deployment, user intent, and security. Our evaluation reveals that state-of-the-art LLMs initially performed poorly, with Claude-3.5 and Claude-3.7 achieving only 30.2% and 26.8% deployment success on the first attempt respectively. However, IaCGen transforms this performance dramatically: all evaluated models reach over 90% passItr@25, with Claude-3.5 and Claude-3.7 achieving 98% success rate. Despite these improvements, critical challenges remain in user intent alignment (25.2% accuracy) and security compliance (8.4% pass rate), highlighting areas requiring continued research. Our work provides the first comprehensive assessment of deployability-centric IaC template generation and establishes a foundation for future research.
Multilingual Prompting for Improving LLM Generation Diversity
May 21, 2025



Large Language Models (LLMs) are known to lack cultural representation and overall diversity in their generations, from expressing opinions to answering factual questions. To mitigate this problem, we propose multilingual prompting: a prompting method which generates several variations of a base prompt with added cultural and linguistic cues from several cultures, generates responses, and then combines the results. Building on evidence that LLMs have language-specific knowledge, multilingual prompting seeks to increase diversity by activating a broader range of cultural knowledge embedded in model training data. Through experiments across multiple models (GPT-4o, GPT-4o-mini, LLaMA 70B, and LLaMA 8B), we show that multilingual prompting consistently outperforms existing diversity-enhancing techniques such as high-temperature sampling, step-by-step recall, and personas prompting. Further analyses show that the benefits of multilingual prompting vary with language resource level and model size, and that aligning the prompting language with the cultural cues reduces hallucination about culturally-specific information.
Automated Knot Detection and Pairing for Wood Analysis in the Timber Industry
May 09, 2025Knots in wood are critical to both aesthetics and structural integrity, making their detection and pairing essential in timber processing. However, traditional manual annotation was labor-intensive and inefficient, necessitating automation. This paper proposes a lightweight and fully automated pipeline for knot detection and pairing based on machine learning techniques. In the detection stage, high-resolution surface images of wooden boards were collected using industrial-grade cameras, and a large-scale dataset was manually annotated and preprocessed. After the transfer learning, the YOLOv8l achieves an mAP@0.5 of 0.887. In the pairing stage, detected knots were analyzed and paired based on multidimensional feature extraction. A triplet neural network was used to map the features into a latent space, enabling clustering algorithms to identify and pair corresponding knots. The triplet network with learnable weights achieved a pairing accuracy of 0.85. Further analysis revealed that he distances from the knot's start and end points to the bottom of the wooden board, and the longitudinal coordinates play crucial roles in achieving high pairing accuracy. Our experiments validate the effectiveness of the proposed solution, demonstrating the potential of AI in advancing wood science and industry.
Privacy Meets Explainability: Managing Confidential Data and Transparency Policies in LLM-Empowered Science
Apr 14, 2025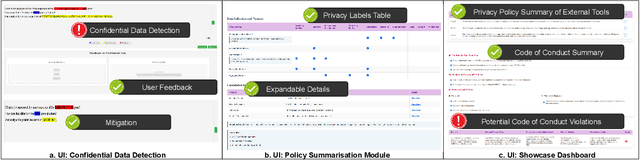


As Large Language Models (LLMs) become integral to scientific workflows, concerns over the confidentiality and ethical handling of confidential data have emerged. This paper explores data exposure risks through LLM-powered scientific tools, which can inadvertently leak confidential information, including intellectual property and proprietary data, from scientists' perspectives. We propose "DataShield", a framework designed to detect confidential data leaks, summarize privacy policies, and visualize data flow, ensuring alignment with organizational policies and procedures. Our approach aims to inform scientists about data handling practices, enabling them to make informed decisions and protect sensitive information. Ongoing user studies with scientists are underway to evaluate the framework's usability, trustworthiness, and effectiveness in tackling real-world privacy challenges.
Test-takers have a say: understanding the implications of the use of AI in language tests
Jul 19, 2023

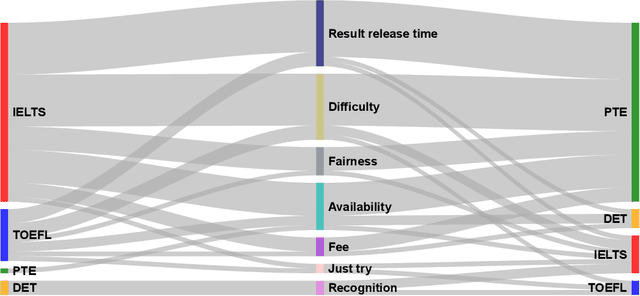
Language tests measure a person's ability to use a language in terms of listening, speaking, reading, or writing. Such tests play an integral role in academic, professional, and immigration domains, with entities such as educational institutions, professional accreditation bodies, and governments using them to assess candidate language proficiency. Recent advances in Artificial Intelligence (AI) and the discipline of Natural Language Processing have prompted language test providers to explore AI's potential applicability within language testing, leading to transformative activity patterns surrounding language instruction and learning. However, with concerns over AI's trustworthiness, it is imperative to understand the implications of integrating AI into language testing. This knowledge will enable stakeholders to make well-informed decisions, thus safeguarding community well-being and testing integrity. To understand the concerns and effects of AI usage in language tests, we conducted interviews and surveys with English test-takers. To the best of our knowledge, this is the first empirical study aimed at identifying the implications of AI adoption in language tests from a test-taker perspective. Our study reveals test-taker perceptions and behavioral patterns. Specifically, we identify that AI integration may enhance perceptions of fairness, consistency, and availability. Conversely, it might incite mistrust regarding reliability and interactivity aspects, subsequently influencing the behaviors and well-being of test-takers. These insights provide a better understanding of potential societal implications and assist stakeholders in making informed decisions concerning AI usage in language testing.
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
Jul 08, 2023


The Right to be Forgotten (RTBF) was first established as the result of the ruling of Google Spain SL, Google Inc. v AEPD, Mario Costeja Gonz\'alez, and was later included as the Right to Erasure under the General Data Protection Regulation (GDPR) of European Union to allow individuals the right to request personal data be deleted by organizations. Specifically for search engines, individuals can send requests to organizations to exclude their information from the query results. With the recent development of Large Language Models (LLMs) and their use in chatbots, LLM-enabled software systems have become popular. But they are not excluded from the RTBF. Compared with the indexing approach used by search engines, LLMs store, and process information in a completely different way. This poses new challenges for compliance with the RTBF. In this paper, we explore these challenges and provide our insights on how to implement technical solutions for the RTBF, including the use of machine unlearning, model editing, and prompting engineering.