 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing DPSGD via Per-Sample Momentum and Low-Pass Filtering
Nov 11, 2025



Differentially Private Stochastic Gradient Descent (DPSGD) is widely used to train deep neural networks with formal privacy guarantees. However, the addition of differential privacy (DP) often degrades model accuracy by introducing both noise and bias. Existing techniques typically address only one of these issues, as reducing DP noise can exacerbate clipping bias and vice-versa. In this paper, we propose a novel method, \emph{DP-PMLF}, which integrates per-sample momentum with a low-pass filtering strategy to simultaneously mitigate DP noise and clipping bias. Our approach uses per-sample momentum to smooth gradient estimates prior to clipping, thereby reducing sampling variance. It further employs a post-processing low-pass filter to attenuate high-frequency DP noise without consuming additional privacy budget. We provide a theoretical analysis demonstrating an improved convergence rate under rigorous DP guarantees, and our empirical evaluations reveal that DP-PMLF significantly enhances the privacy-utility trade-off compared to several state-of-the-art DPSGD variants.
Privacy Meets Explainability: Managing Confidential Data and Transparency Policies in LLM-Empowered Science
Apr 14, 2025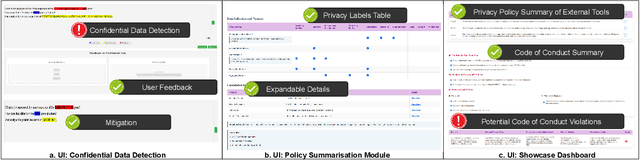


As Large Language Models (LLMs) become integral to scientific workflows, concerns over the confidentiality and ethical handling of confidential data have emerged. This paper explores data exposure risks through LLM-powered scientific tools, which can inadvertently leak confidential information, including intellectual property and proprietary data, from scientists' perspectives. We propose "DataShield", a framework designed to detect confidential data leaks, summarize privacy policies, and visualize data flow, ensuring alignment with organizational policies and procedures. Our approach aims to inform scientists about data handling practices, enabling them to make informed decisions and protect sensitive information. Ongoing user studies with scientists are underway to evaluate the framework's usability, trustworthiness, and effectiveness in tackling real-world privacy challenges.
Adaptive Clipping for Privacy-Preserving Few-Shot Learning: Enhancing Generalization with Limited Data
Mar 27, 2025In the era of data-driven machine-learning applications, privacy concerns and the scarcity of labeled data have become paramount challenges. These challenges are particularly pronounced in the domain of few-shot learning, where the ability to learn from limited labeled data is crucial. Privacy-preserving few-shot learning algorithms have emerged as a promising solution to address such pronounced challenges. However, it is well-known that privacy-preserving techniques often lead to a drop in utility due to the fundamental trade-off between data privacy and model performance. To enhance the utility of privacy-preserving few-shot learning methods, we introduce a novel approach called Meta-Clip. This technique is specifically designed for meta-learning algorithms, including Differentially Private (DP) model-agnostic meta-learning, DP-Reptile, and DP-MetaSGD algorithms, with the objective of balancing data privacy preservation with learning capacity maximization. By dynamically adjusting clipping thresholds during the training process, our Adaptive Clipping method provides fine-grained control over the disclosure of sensitive information, mitigating overfitting on small datasets and significantly improving the generalization performance of meta-learning models. Through comprehensive experiments on diverse benchmark datasets, we demonstrate the effectiveness of our approach in minimizing utility degradation, showcasing a superior privacy-utility trade-off compared to existing privacy-preserving techniques. The adoption of Adaptive Clipping represents a substantial step forward in the field of privacy-preserving few-shot learning, empowering the development of secure and accurate models for real-world applications, especially in scenarios where there are limited data availability.
Multi-Objective Optimization for Privacy-Utility Balance in Differentially Private Federated Learning
Mar 27, 2025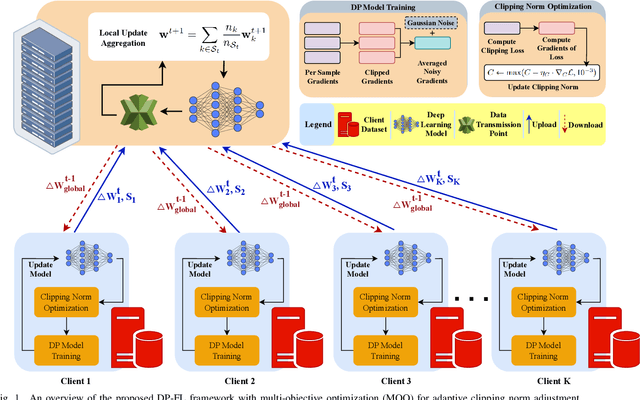
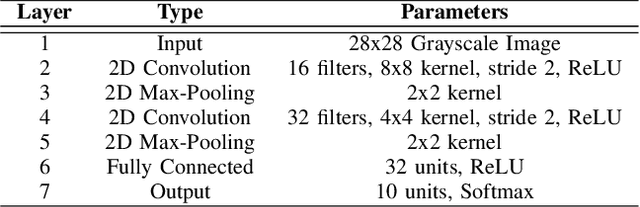

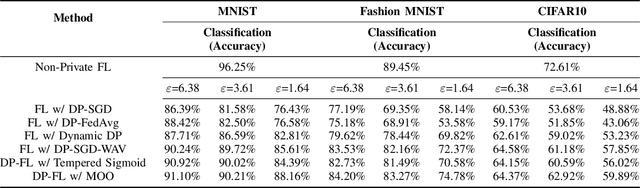
Federated learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it a promising approach for privacy-preserving machine learning. However, ensuring differential privacy (DP) in FL presents challenges due to the trade-off between model utility and privacy protection. Clipping gradients before aggregation is a common strategy to limit privacy loss, but selecting an optimal clipping norm is non-trivial, as excessively high values compromise privacy, while overly restrictive clipping degrades model performance. In this work, we propose an adaptive clipping mechanism that dynamically adjusts the clipping norm using a multi-objective optimization framework. By integrating privacy and utility considerations into the optimization objective, our approach balances privacy preservation with model accuracy. We theoretically analyze the convergence properties of our method and demonstrate its effectiveness through extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 datasets. Our results show that adaptive clipping consistently outperforms fixed-clipping baselines, achieving improved accuracy under the same privacy constraints. This work highlights the potential of dynamic clipping strategies to enhance privacy-utility trade-offs in differentially private federated learning.
Privacy at a Price: Exploring its Dual Impact on AI Fairness
Apr 15, 2024



The worldwide adoption of machine learning (ML) and deep learning models, particularly in critical sectors, such as healthcare and finance, presents substantial challenges in maintaining individual privacy and fairness. These two elements are vital to a trustworthy environment for learning systems. While numerous studies have concentrated on protecting individual privacy through differential privacy (DP) mechanisms, emerging research indicates that differential privacy in machine learning models can unequally impact separate demographic subgroups regarding prediction accuracy. This leads to a fairness concern, and manifests as biased performance. Although the prevailing view is that enhancing privacy intensifies fairness disparities, a smaller, yet significant, subset of research suggests the opposite view. In this article, with extensive evaluation results, we demonstrate that the impact of differential privacy on fairness is not monotonous. Instead, we observe that the accuracy disparity initially grows as more DP noise (enhanced privacy) is added to the ML process, but subsequently diminishes at higher privacy levels with even more noise. Moreover, implementing gradient clipping in the differentially private stochastic gradient descent ML method can mitigate the negative impact of DP noise on fairness. This mitigation is achieved by moderating the disparity growth through a lower clipping threshold.
Learn to Unlearn: A Survey on Machine Unlearning
May 12, 2023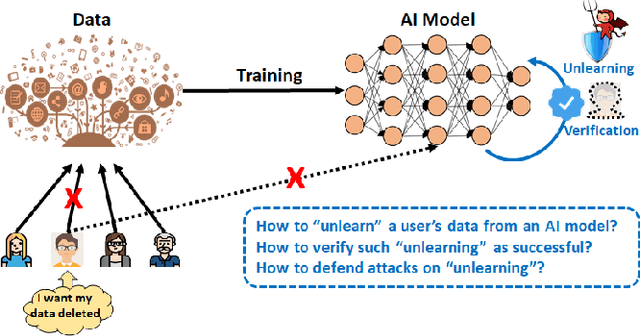
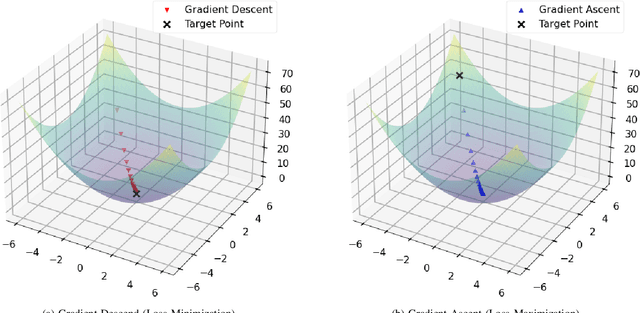
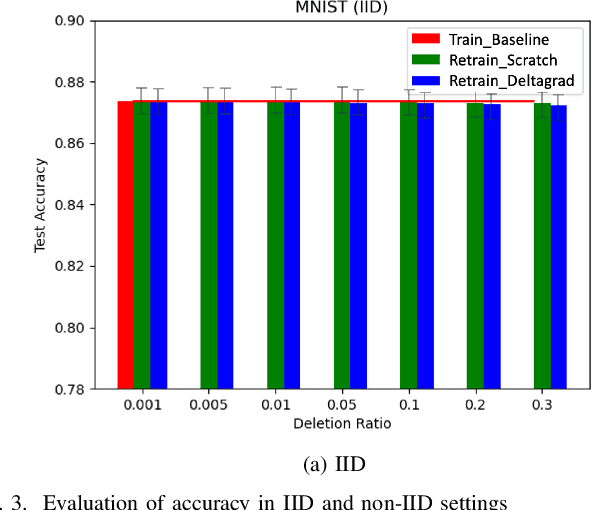
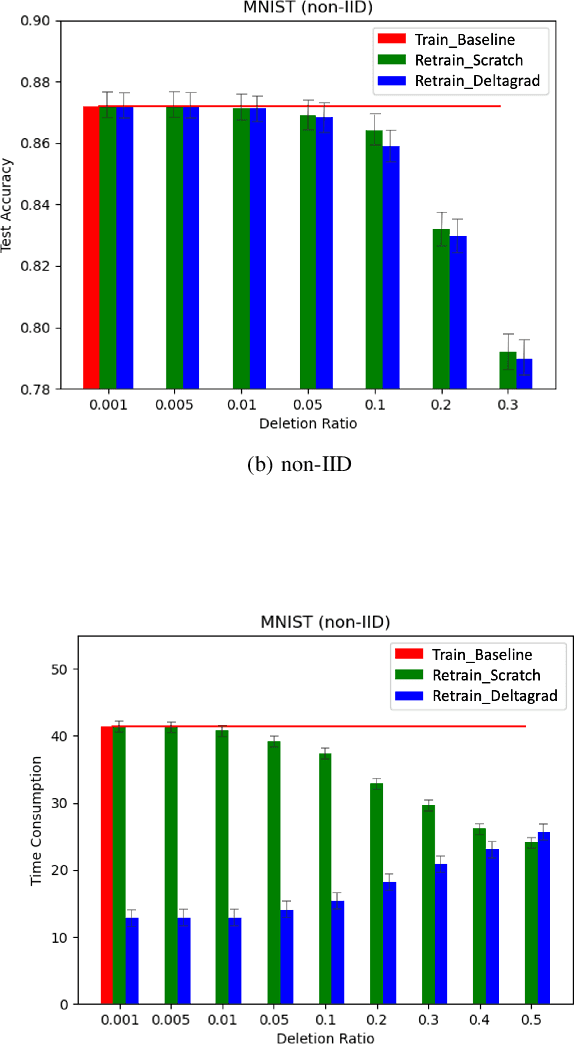
Machine Learning (ML) models contain private information, and implementing the right to be forgotten is a challenging privacy issue in many data applications. Machine unlearning has emerged as an alternative to remove sensitive data from a trained model, but completely retraining ML models is often not feasible. This survey provides a concise appraisal of Machine Unlearning techniques, encompassing both exact and approximate methods, probable attacks, and verification approaches. The survey compares the merits and limitations each method and evaluates their performance using the Deltagrad exact machine unlearning method. The survey also highlights challenges like the pressing need for a robust model for non-IID deletion to mitigate fairness issues. Overall, the survey provides a thorough synopsis of machine unlearning techniques and applications, noting future research directions in this evolving field. The survey aims to be a valuable resource for researchers and practitioners seeking to provide privacy and equity in ML systems.
PADDLES: Phase-Amplitude Spectrum Disentangled Early Stopping for Learning with Noisy Labels
Dec 07, 2022



Convolutional Neural Networks (CNNs) have demonstrated superiority in learning patterns, but are sensitive to label noises and may overfit noisy labels during training. The early stopping strategy averts updating CNNs during the early training phase and is widely employed in the presence of noisy labels. Motivated by biological findings that the amplitude spectrum (AS) and phase spectrum (PS) in the frequency domain play different roles in the animal's vision system, we observe that PS, which captures more semantic information, can increase the robustness of DNNs to label noise, more so than AS can. We thus propose early stops at different times for AS and PS by disentangling the features of some layer(s) into AS and PS using Discrete Fourier Transform (DFT) during training. Our proposed Phase-AmplituDe DisentangLed Early Stopping (PADDLES) method is shown to be effective on both synthetic and real-world label-noise datasets. PADDLES outperforms other early stopping methods and obtains state-of-the-art performance.
Realistic Differentially-Private Transmission Power Flow Data Release
Mar 25, 2021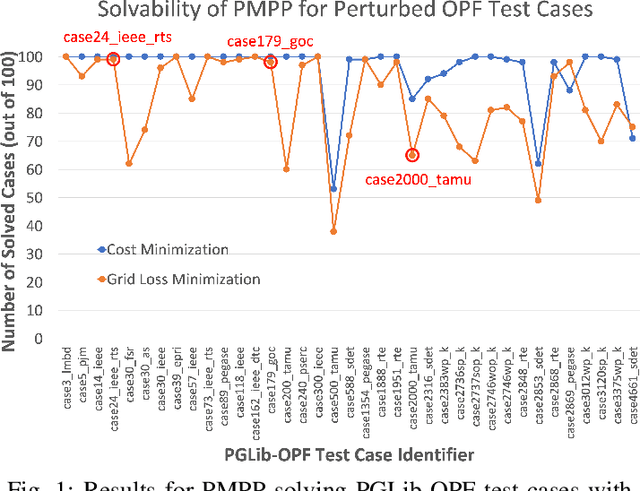
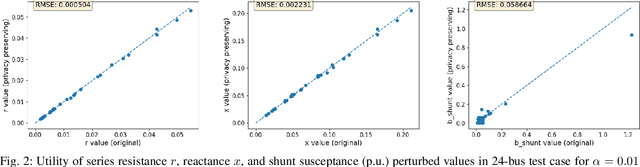
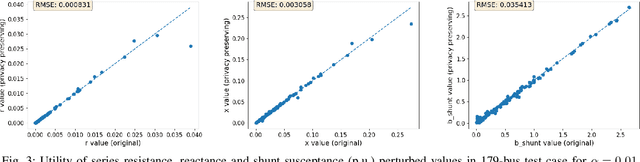
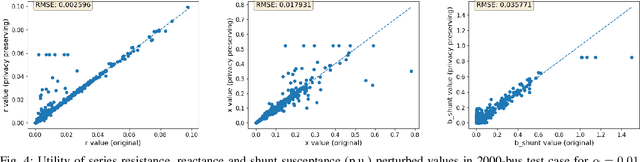
For the modeling, design and planning of future energy transmission networks, it is vital for stakeholders to access faithful and useful power flow data, while provably maintaining the privacy of business confidentiality of service providers. This critical challenge has recently been somewhat addressed in [1]. This paper significantly extends this existing work. First, we reduce the potential leakage information by proposing a fundamentally different post-processing method, using public information of grid losses rather than power dispatch, which achieve a higher level of privacy protection. Second, we protect more sensitive parameters, i.e., branch shunt susceptance in addition to series impedance (complete pi-model). This protects power flow data for the transmission high-voltage networks, using differentially private transformations that maintain the optimal power flow consistent with, and faithful to, expected model behaviour. Third, we tested our approach at a larger scale than previous work, using the PGLib-OPF test cases [10]. This resulted in the successful obfuscation of up to a 4700-bus system, which can be successfully solved with faithfulness of parameters and good utility to data analysts. Our approach addresses a more feasible and realistic scenario, and provides higher than state-of-the-art privacy guarantees, while maintaining solvability, fidelity and feasibility of the system.