 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Causal Attribution for Real-Time Attack Forensics in 6G Network Slicing
May 26, 2026Cross-slice attack attribution in 6G networks requires identifying causal propagation chains through shared infrastructure in under 100 ms. Existing methods struggle to satisfy this strict SLA without sacrificing accuracy, because shared resource contention creates spurious correlations that are indistinguishable from genuine causal links under standard Granger tests. We propose DA-GC, a certified causal attribution framework that integrates resource-conditioned Granger causality with an axiomatically derived Resource Contention Model (RCM) to systematically block resource-mediated confounding. On a 15-slice production-emulation 6G testbed with 1,100 attack scenarios, DA-GC achieves 89.2% attribution accuracy at 87 ms. This represents a 7.9 percentage-point improvement over the strongest baseline at 2.7x lower latency, alongside demonstrated cross-topology generalization and concept-drift resilience. Crucially, DA-GC is backed by a comprehensive formal certification stack. We provide mathematically proven validity certificates for statistical soundness under serially dependent telemetry and piecewise-stationarity. Furthermore, we establish strict security bounds, including an adversarial utilization spoofing breakdown point of $δ^* \approx 0.95$, and define the minimum differential-privacy noise required for a provably private and robust deployment.
StreamSplit: Continuous Audio Representation Learning via Uncertainty-Guided Adaptive Splitting
May 26, 2026Large-batch Contrastive Learning (CL), the foundation of modern representation learning, is fundamentally incompatible with the volatile resource constraints of edge devices. This conflict creates a dilemma: small on-device batches degrade model fidelity, while offloading to the cloud incurs unacceptable latency and bandwidth costs. Existing solutions often resort to static model compression, which fails to adapt to the runtime volatility of edge environments. To bridge this gap, we present StreamSplit, a novel framework that makes streaming CL practical across heterogeneous ARM client platforms. StreamSplit resolves the conflict between the continuous nature of ambient audio and the discrete batch requirements of models like CLAP and COLA. We introduce: (1) A distribution-based streaming framework that decouples representation quality from local batch size, using a tractable Hybrid Loss to maintain fidelity despite sparse updates; and (2) An Uncertainty-Guided Adaptive Splitter that uses a lightweight Reinforcement Learning (RL) policy to dynamically partition computation. Uniquely, this policy integrates real-time resource monitoring with embedding ambiguity to optimize the accuracy-latency trade-off on the fly. We evaluate StreamSplit on diverse hardware, from the resource-constrained Raspberry Pi 4 to the high-performance Apple M2. Results demonstrate that StreamSplit reduces per-sample latency by up to 4.7x and cuts bandwidth by 77.1% and energy by 52.3% compared to server-centric baselines. Crucially, it maintains accuracy within 2.2% of server-centric models, proving that adaptive, distributed learning is a viable path for the modern edge ecosystem.
Geometric Analysis of Speech Representation Spaces: Topological Disentanglement and Confound Detection
Feb 24, 2026Speech-based clinical tools are increasingly deployed in multilingual settings, yet whether pathological speech markers remain geometrically separable from accent variation remains unclear. Systems may misclassify healthy non-native speakers or miss pathology in multilingual patients. We propose a four-metric clustering framework to evaluate geometric disentanglement of emotional, linguistic, and pathological speech features across six corpora and eight dataset combinations. A consistent hierarchy emerges: emotional features form the tightest clusters (Silhouette 0.250), followed by pathological (0.141) and linguistic (0.077). Confound analysis shows pathological-linguistic overlap remains below 0.21, which is above the permutation null but bounded for clinical deployment. Trustworthiness analysis confirms embedding fidelity and robustness of the geometric conclusions. Our framework provides actionable guidelines for equitable and reliable speech health systems across diverse populations.
Quantifying Dimensional Independence in Speech: An Information-Theoretic Framework for Disentangled Representation Learning
Feb 24, 2026Speech signals encode emotional, linguistic, and pathological information within a shared acoustic channel; however, disentanglement is typically assessed indirectly through downstream task performance. We introduce an information-theoretic framework to quantify cross-dimension statistical dependence in handcrafted acoustic features by integrating bounded neural mutual information (MI) estimation with non-parametric validation. Across six corpora, cross-dimension MI remains low, with tight estimation bounds ($< 0.15$ nats), indicating weak statistical coupling in the data considered, whereas Source--Filter MI is substantially higher (0.47 nats). Attribution analysis, defined as the proportion of total MI attributable to source versus filter components, reveals source dominance for emotional dimensions (80\%) and filter dominance for linguistic and pathological dimensions (60\% and 58\%, respectively). These findings provide a principled framework for quantifying dimensional independence in speech.
Quantifying Quanvolutional Neural Networks Robustness for Speech in Healthcare Applications
Jan 05, 2026Speech-based machine learning systems are sensitive to noise, complicating reliable deployment in emotion recognition and voice pathology detection. We evaluate the robustness of a hybrid quantum machine learning model, quanvolutional neural networks (QNNs) against classical convolutional neural networks (CNNs) under four acoustic corruptions (Gaussian noise, pitch shift, temporal shift, and speed variation) in a clean-train/corrupted-test regime. Using AVFAD (voice pathology) and TESS (speech emotion), we compare three QNN models (Random, Basic, Strongly) to a simple CNN baseline (CNN-Base), ResNet-18 and VGG-16 using accuracy and corruption metrics (CE, mCE, RCE, RmCE), and analyze architectural factors (circuit complexity or depth, convergence) alongside per-emotion robustness. QNNs generally outperform the CNN-Base under pitch shift, temporal shift, and speed variation (up to 22% lower CE/RCE at severe temporal shift), while the CNN-Base remains more resilient to Gaussian noise. Among quantum circuits, QNN-Basic achieves the best overall robustness on AVFAD, and QNN-Random performs strongest on TESS. Emotion-wise, fear is most robust (80-90% accuracy under severe corruptions), neutral can collapse under strong Gaussian noise (5.5% accuracy), and happy is most vulnerable to pitch, temporal, and speed distortions. QNNs also converge up to six times faster than the CNN-Base. To our knowledge, this is a systematic study of QNN robustness for speech under common non-adversarial acoustic corruptions, indicating that shallow entangling quantum front-ends can improve noise resilience while sensitivity to additive noise remains a challenge.
Federated Learning for Cyber Physical Systems: A Comprehensive Survey
May 08, 2025The integration of machine learning (ML) in cyber physical systems (CPS) is a complex task due to the challenges that arise in terms of real-time decision making, safety, reliability, device heterogeneity, and data privacy. There are also open research questions that must be addressed in order to fully realize the potential of ML in CPS. Federated learning (FL), a distributed approach to ML, has become increasingly popular in recent years. It allows models to be trained using data from decentralized sources. This approach has been gaining popularity in the CPS field, as it integrates computer, communication, and physical processes. Therefore, the purpose of this work is to provide a comprehensive analysis of the most recent developments of FL-CPS, including the numerous application areas, system topologies, and algorithms developed in recent years. The paper starts by discussing recent advances in both FL and CPS, followed by their integration. Then, the paper compares the application of FL in CPS with its applications in the internet of things (IoT) in further depth to show their connections and distinctions. Furthermore, the article scrutinizes how FL is utilized in critical CPS applications, e.g., intelligent transportation systems, cybersecurity services, smart cities, and smart healthcare solutions. The study also includes critical insights and lessons learned from various FL-CPS implementations. The paper's concluding section delves into significant concerns and suggests avenues for further research in this fast-paced and dynamic era.
Quantum-Inspired Genetic Algorithm for Robust Source Separation in Smart City Acoustics
Apr 10, 2025



The cacophony of urban sounds presents a significant challenge for smart city applications that rely on accurate acoustic scene analysis. Effectively analyzing these complex soundscapes, often characterized by overlapping sound sources, diverse acoustic events, and unpredictable noise levels, requires precise source separation. This task becomes more complicated when only limited training data is available. This paper introduces a novel Quantum-Inspired Genetic Algorithm (p-QIGA) for source separation, drawing inspiration from quantum information theory to enhance acoustic scene analysis in smart cities. By leveraging quantum superposition for efficient solution space exploration and entanglement to handle correlated sources, p-QIGA achieves robust separation even with limited data. These quantum-inspired concepts are integrated into a genetic algorithm framework to optimize source separation parameters. The effectiveness of our approach is demonstrated on two datasets: the TAU Urban Acoustic Scenes 2020 Mobile dataset, representing typical urban soundscapes, and the Silent Cities dataset, capturing quieter urban environments during the COVID-19 pandemic. Experimental results show that the p-QIGA achieves accuracy comparable to state-of-the-art methods while exhibiting superior resilience to noise and limited training data, achieving up to 8.2 dB signal-to-distortion ratio (SDR) in noisy environments and outperforming baseline methods by up to 2 dB with only 10% of the training data. This research highlights the potential of p-QIGA to advance acoustic signal processing in smart cities, particularly for noise pollution monitoring and acoustic surveillance.
Enhancing Federated Learning Through Secure Cluster-Weighted Client Aggregation
Mar 29, 2025Federated learning (FL) has emerged as a promising paradigm in machine learning, enabling collaborative model training across decentralized devices without the need for raw data sharing. In FL, a global model is trained iteratively on local datasets residing on individual devices, each contributing to the model's improvement. However, the heterogeneous nature of these local datasets, stemming from diverse user behaviours, device capabilities, and data distributions, poses a significant challenge. The inherent heterogeneity in federated learning gives rise to various issues, including model performance discrepancies, convergence challenges, and potential privacy concerns. As the global model progresses through rounds of training, the disparities in local data quality and quantity can impede the overall effectiveness of federated learning systems. Moreover, maintaining fairness and privacy across diverse user groups becomes a paramount concern. To address this issue, this paper introduces a novel FL framework, ClusterGuardFL, that employs dissimilarity scores, k-means clustering, and reconciliation confidence scores to dynamically assign weights to client updates. The dissimilarity scores between global and local models guide the formation of clusters, with cluster size influencing the weight allocation. Within each cluster, a reconciliation confidence score is calculated for individual data points, and a softmax layer generates customized weights for clients. These weights are utilized in the aggregation process, enhancing the model's robustness and privacy. Experimental results demonstrate the efficacy of the proposed approach in achieving improved model performance in diverse datasets.
Multi-Objective Optimization for Privacy-Utility Balance in Differentially Private Federated Learning
Mar 27, 2025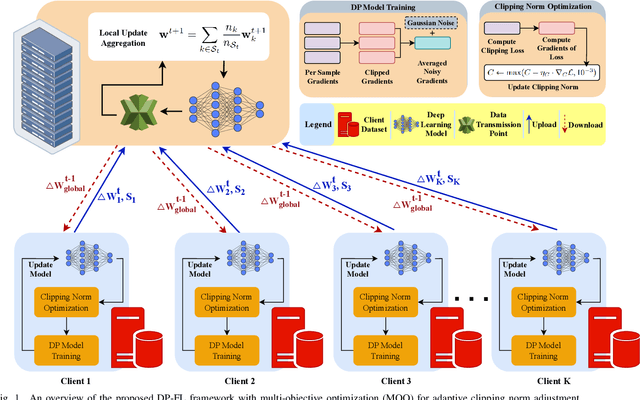
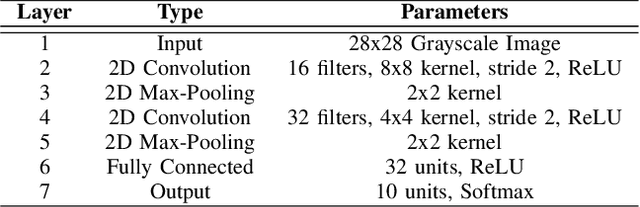

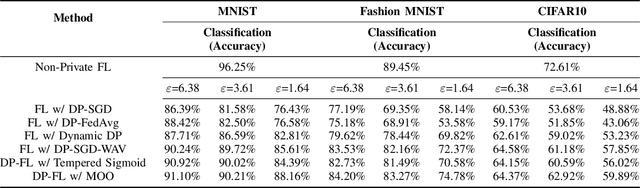
Federated learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it a promising approach for privacy-preserving machine learning. However, ensuring differential privacy (DP) in FL presents challenges due to the trade-off between model utility and privacy protection. Clipping gradients before aggregation is a common strategy to limit privacy loss, but selecting an optimal clipping norm is non-trivial, as excessively high values compromise privacy, while overly restrictive clipping degrades model performance. In this work, we propose an adaptive clipping mechanism that dynamically adjusts the clipping norm using a multi-objective optimization framework. By integrating privacy and utility considerations into the optimization objective, our approach balances privacy preservation with model accuracy. We theoretically analyze the convergence properties of our method and demonstrate its effectiveness through extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 datasets. Our results show that adaptive clipping consistently outperforms fixed-clipping baselines, achieving improved accuracy under the same privacy constraints. This work highlights the potential of dynamic clipping strategies to enhance privacy-utility trade-offs in differentially private federated learning.
Adaptive Clipping for Privacy-Preserving Few-Shot Learning: Enhancing Generalization with Limited Data
Mar 27, 2025In the era of data-driven machine-learning applications, privacy concerns and the scarcity of labeled data have become paramount challenges. These challenges are particularly pronounced in the domain of few-shot learning, where the ability to learn from limited labeled data is crucial. Privacy-preserving few-shot learning algorithms have emerged as a promising solution to address such pronounced challenges. However, it is well-known that privacy-preserving techniques often lead to a drop in utility due to the fundamental trade-off between data privacy and model performance. To enhance the utility of privacy-preserving few-shot learning methods, we introduce a novel approach called Meta-Clip. This technique is specifically designed for meta-learning algorithms, including Differentially Private (DP) model-agnostic meta-learning, DP-Reptile, and DP-MetaSGD algorithms, with the objective of balancing data privacy preservation with learning capacity maximization. By dynamically adjusting clipping thresholds during the training process, our Adaptive Clipping method provides fine-grained control over the disclosure of sensitive information, mitigating overfitting on small datasets and significantly improving the generalization performance of meta-learning models. Through comprehensive experiments on diverse benchmark datasets, we demonstrate the effectiveness of our approach in minimizing utility degradation, showcasing a superior privacy-utility trade-off compared to existing privacy-preserving techniques. The adoption of Adaptive Clipping represents a substantial step forward in the field of privacy-preserving few-shot learning, empowering the development of secure and accurate models for real-world applications, especially in scenarios where there are limited data availability.