 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokEye: Fast Signal Extraction for Fluctuating Time Series via Offline Self-Supervised Learning From Fusion Diagnostics to Bioacoustics
Feb 26, 2026Next-generation fusion facilities like ITER face a "data deluge," generating petabytes of multi-diagnostic signals daily that challenge manual analysis. We present a "signals-first" self-supervised framework for the automated extraction of coherent and transient modes from high-noise time-frequency data across a variety of sensors. We also develop a general-purpose method and tool for extracting coherent, quasi-coherent, and transient modes for fluctuation measurements in tokamaks by employing non-linear optimal techniques in multichannel signal processing with a fast neural network surrogate on fast magnetics, electron cyclotron emission, CO2 interferometers, and beam emission spectroscopy measurements from DIII-D. Results are tested on data from DIII-D, TJ-II, and non-fusion spectrograms. With an inference latency of 0.5 seconds, this framework enables real-time mode identification and large-scale automated database generation for advanced plasma control. Repository is in https://github.com/PlasmaControl/TokEye.
Pre-Editorial Normalization for Automatically Transcribed Medieval Manuscripts in Old French and Latin
Feb 14, 2026Recent advances in Automatic Text Recognition (ATR) have improved access to historical archives, yet a methodological divide persists between palaeographic transcriptions and normalized digital editions. While ATR models trained on more palaeographically-oriented datasets such as CATMuS have shown greater generalizability, their raw outputs remain poorly compatible with most readers and downstream NLP tools, thus creating a usability gap. On the other hand, ATR models trained to produce normalized outputs have been shown to struggle to adapt to new domains and tend to over-normalize and hallucinate. We introduce the task of Pre-Editorial Normalization (PEN), which consists in normalizing graphemic ATR output according to editorial conventions, which has the advantage of keeping an intermediate step with palaeographic fidelity while providing a normalized version for practical usability. We present a new dataset derived from the CoMMA corpus and aligned with digitized Old French and Latin editions using passim. We also produce a manually corrected gold-standard evaluation set. We benchmark this resource using ByT5-based sequence-to-sequence models on normalization and pre-annotation tasks. Our contributions include the formal definition of PEN, a 4.66M-sample silver training corpus, a 1.8k-sample gold evaluation set, and a normalization model achieving a 6.7% CER, substantially outperforming previous models for this task.
Enhancing DPSGD via Per-Sample Momentum and Low-Pass Filtering
Nov 11, 2025



Differentially Private Stochastic Gradient Descent (DPSGD) is widely used to train deep neural networks with formal privacy guarantees. However, the addition of differential privacy (DP) often degrades model accuracy by introducing both noise and bias. Existing techniques typically address only one of these issues, as reducing DP noise can exacerbate clipping bias and vice-versa. In this paper, we propose a novel method, \emph{DP-PMLF}, which integrates per-sample momentum with a low-pass filtering strategy to simultaneously mitigate DP noise and clipping bias. Our approach uses per-sample momentum to smooth gradient estimates prior to clipping, thereby reducing sampling variance. It further employs a post-processing low-pass filter to attenuate high-frequency DP noise without consuming additional privacy budget. We provide a theoretical analysis demonstrating an improved convergence rate under rigorous DP guarantees, and our empirical evaluations reveal that DP-PMLF significantly enhances the privacy-utility trade-off compared to several state-of-the-art DPSGD variants.
Multi-Objective Optimization for Privacy-Utility Balance in Differentially Private Federated Learning
Mar 27, 2025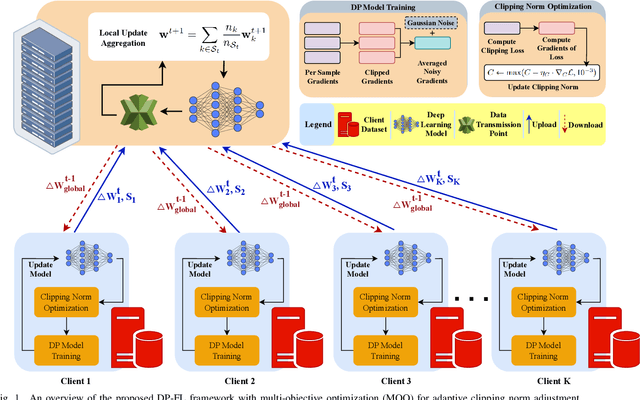
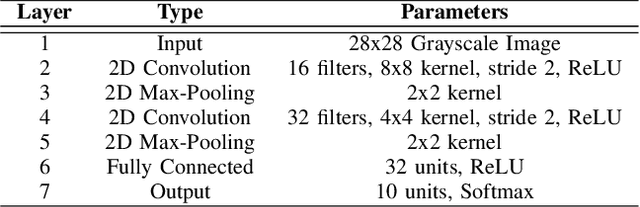

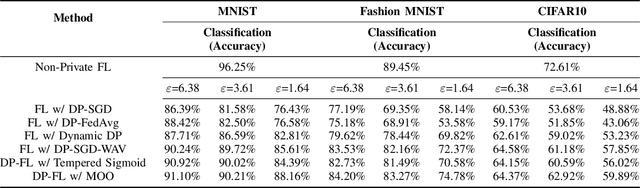
Federated learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it a promising approach for privacy-preserving machine learning. However, ensuring differential privacy (DP) in FL presents challenges due to the trade-off between model utility and privacy protection. Clipping gradients before aggregation is a common strategy to limit privacy loss, but selecting an optimal clipping norm is non-trivial, as excessively high values compromise privacy, while overly restrictive clipping degrades model performance. In this work, we propose an adaptive clipping mechanism that dynamically adjusts the clipping norm using a multi-objective optimization framework. By integrating privacy and utility considerations into the optimization objective, our approach balances privacy preservation with model accuracy. We theoretically analyze the convergence properties of our method and demonstrate its effectiveness through extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 datasets. Our results show that adaptive clipping consistently outperforms fixed-clipping baselines, achieving improved accuracy under the same privacy constraints. This work highlights the potential of dynamic clipping strategies to enhance privacy-utility trade-offs in differentially private federated learning.
Adaptive Clipping for Privacy-Preserving Few-Shot Learning: Enhancing Generalization with Limited Data
Mar 27, 2025In the era of data-driven machine-learning applications, privacy concerns and the scarcity of labeled data have become paramount challenges. These challenges are particularly pronounced in the domain of few-shot learning, where the ability to learn from limited labeled data is crucial. Privacy-preserving few-shot learning algorithms have emerged as a promising solution to address such pronounced challenges. However, it is well-known that privacy-preserving techniques often lead to a drop in utility due to the fundamental trade-off between data privacy and model performance. To enhance the utility of privacy-preserving few-shot learning methods, we introduce a novel approach called Meta-Clip. This technique is specifically designed for meta-learning algorithms, including Differentially Private (DP) model-agnostic meta-learning, DP-Reptile, and DP-MetaSGD algorithms, with the objective of balancing data privacy preservation with learning capacity maximization. By dynamically adjusting clipping thresholds during the training process, our Adaptive Clipping method provides fine-grained control over the disclosure of sensitive information, mitigating overfitting on small datasets and significantly improving the generalization performance of meta-learning models. Through comprehensive experiments on diverse benchmark datasets, we demonstrate the effectiveness of our approach in minimizing utility degradation, showcasing a superior privacy-utility trade-off compared to existing privacy-preserving techniques. The adoption of Adaptive Clipping represents a substantial step forward in the field of privacy-preserving few-shot learning, empowering the development of secure and accurate models for real-world applications, especially in scenarios where there are limited data availability.
Privacy at a Price: Exploring its Dual Impact on AI Fairness
Apr 15, 2024



The worldwide adoption of machine learning (ML) and deep learning models, particularly in critical sectors, such as healthcare and finance, presents substantial challenges in maintaining individual privacy and fairness. These two elements are vital to a trustworthy environment for learning systems. While numerous studies have concentrated on protecting individual privacy through differential privacy (DP) mechanisms, emerging research indicates that differential privacy in machine learning models can unequally impact separate demographic subgroups regarding prediction accuracy. This leads to a fairness concern, and manifests as biased performance. Although the prevailing view is that enhancing privacy intensifies fairness disparities, a smaller, yet significant, subset of research suggests the opposite view. In this article, with extensive evaluation results, we demonstrate that the impact of differential privacy on fairness is not monotonous. Instead, we observe that the accuracy disparity initially grows as more DP noise (enhanced privacy) is added to the ML process, but subsequently diminishes at higher privacy levels with even more noise. Moreover, implementing gradient clipping in the differentially private stochastic gradient descent ML method can mitigate the negative impact of DP noise on fairness. This mitigation is achieved by moderating the disparity growth through a lower clipping threshold.
Seeing the Fruit for the Leaves: Robotically Mapping Apple Fruitlets in a Commercial Orchard
Aug 15, 2023

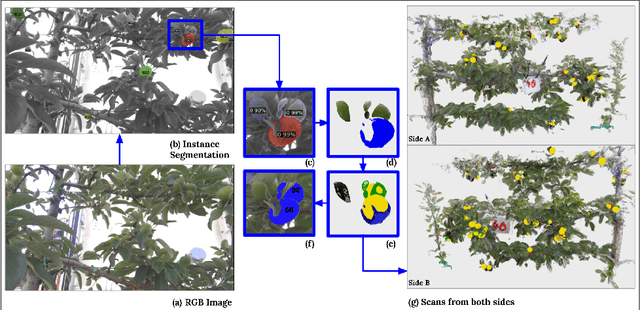

Aotearoa New Zealand has a strong and growing apple industry but struggles to access workers to complete skilled, seasonal tasks such as thinning. To ensure effective thinning and make informed decisions on a per-tree basis, it is crucial to accurately measure the crop load of individual apple trees. However, this task poses challenges due to the dense foliage that hides the fruitlets within the tree structure. In this paper, we introduce the vision system of an automated apple fruitlet thinning robot, developed to tackle the labor shortage issue. This paper presents the initial design, implementation,and evaluation specifics of the system. The platform straddles the 3.4 m tall 2D apple canopy structures to create an accurate map of the fruitlets on each tree. We show that this platform can measure the fruitlet load on an apple tree by scanning through both sides of the branch. The requirement of an overarching platform was justified since two-sided scans had a higher counting accuracy of 81.17 % than one-sided scans at 73.7 %. The system was also demonstrated to produce size estimates within 5.9% RMSE of their true size.
Citations as Queries: Source Attribution Using Language Models as Rerankers
Jun 29, 2023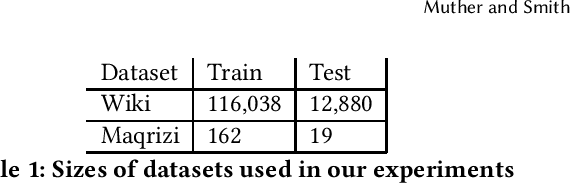


This paper explores new methods for locating the sources used to write a text, by fine-tuning a variety of language models to rerank candidate sources. After retrieving candidates sources using a baseline BM25 retrieval model, a variety of reranking methods are tested to see how effective they are at the task of source attribution. We conduct experiments on two datasets, English Wikipedia and medieval Arabic historical writing, and employ a variety of retrieval and generation based reranking models. In particular, we seek to understand how the degree of supervision required affects the performance of various reranking models. We find that semisupervised methods can be nearly as effective as fully supervised methods while avoiding potentially costly span-level annotation of the target and source documents.
Towards Blockchain-Assisted Privacy-Aware Data Sharing For Edge Intelligence: A Smart Healthcare Perspective
Jun 29, 2023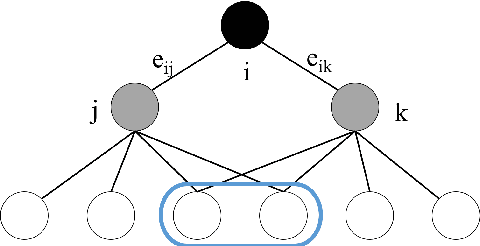

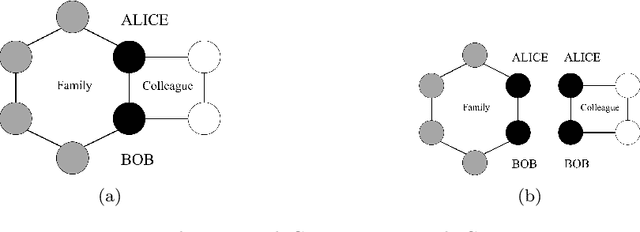
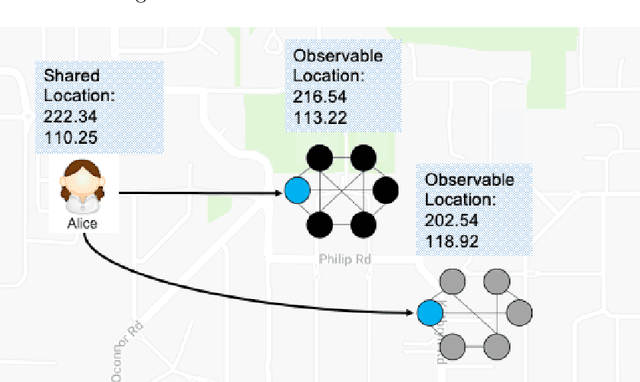
The popularization of intelligent healthcare devices and big data analytics significantly boosts the development of smart healthcare networks (SHNs). To enhance the precision of diagnosis, different participants in SHNs share health data that contains sensitive information. Therefore, the data exchange process raises privacy concerns, especially when the integration of health data from multiple sources (linkage attack) results in further leakage. Linkage attack is a type of dominant attack in the privacy domain, which can leverage various data sources for private data mining. Furthermore, adversaries launch poisoning attacks to falsify the health data, which leads to misdiagnosing or even physical damage. To protect private health data, we propose a personalized differential privacy model based on the trust levels among users. The trust is evaluated by a defined community density, while the corresponding privacy protection level is mapped to controllable randomized noise constrained by differential privacy. To avoid linkage attacks in personalized differential privacy, we designed a noise correlation decoupling mechanism using a Markov stochastic process. In addition, we build the community model on a blockchain, which can mitigate the risk of poisoning attacks during differentially private data transmission over SHNs. To testify the effectiveness and superiority of the proposed approach, we conduct extensive experiments on benchmark datasets.
Learn to Unlearn: A Survey on Machine Unlearning
May 12, 2023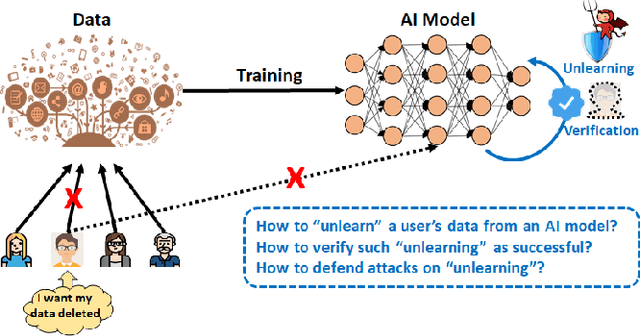
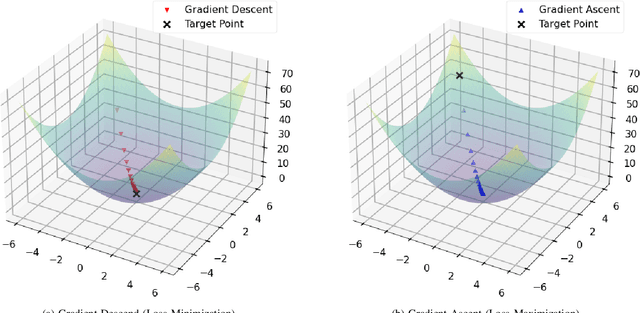
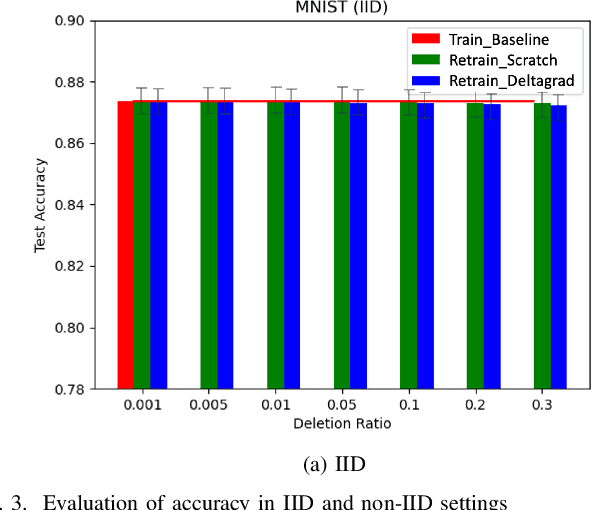
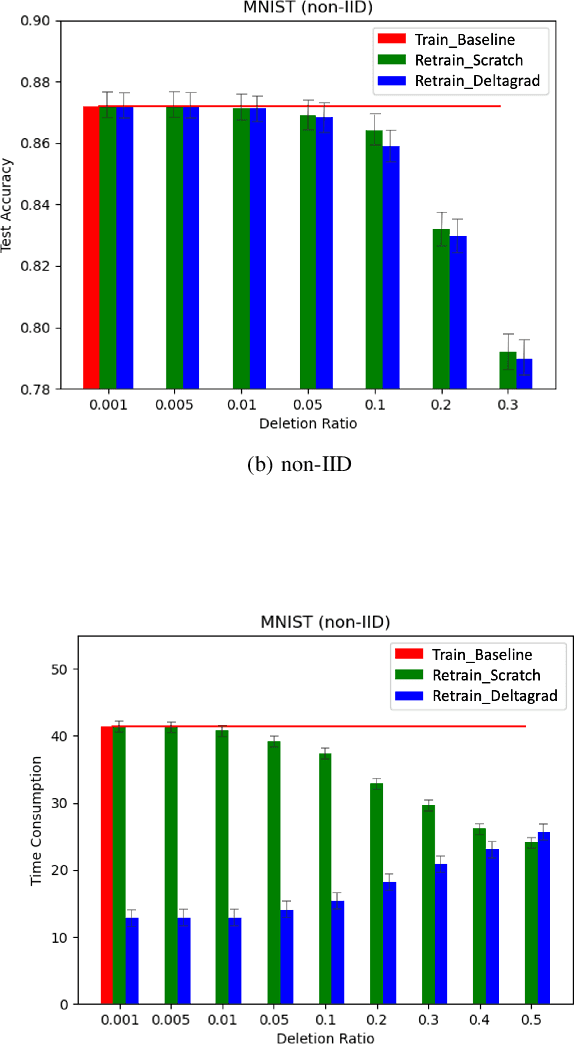
Machine Learning (ML) models contain private information, and implementing the right to be forgotten is a challenging privacy issue in many data applications. Machine unlearning has emerged as an alternative to remove sensitive data from a trained model, but completely retraining ML models is often not feasible. This survey provides a concise appraisal of Machine Unlearning techniques, encompassing both exact and approximate methods, probable attacks, and verification approaches. The survey compares the merits and limitations each method and evaluates their performance using the Deltagrad exact machine unlearning method. The survey also highlights challenges like the pressing need for a robust model for non-IID deletion to mitigate fairness issues. Overall, the survey provides a thorough synopsis of machine unlearning techniques and applications, noting future research directions in this evolving field. The survey aims to be a valuable resource for researchers and practitioners seeking to provide privacy and equity in ML systems.