 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
On Designing Effective RL Reward at Training Time for LLM Reasoning
Oct 19, 2024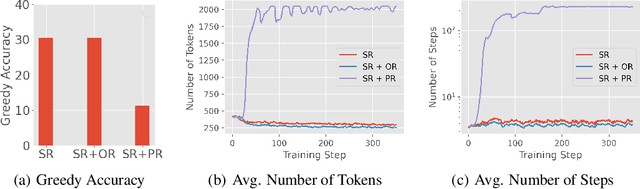
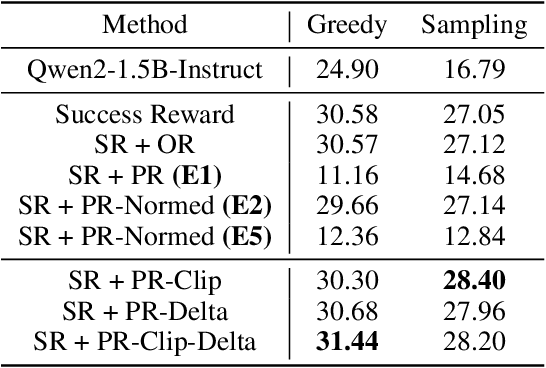

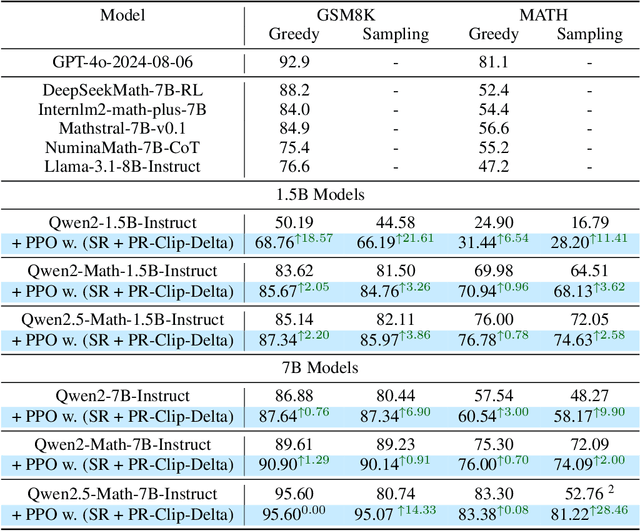
Reward models have been increasingly critical for improving the reasoning capability of LLMs. Existing research has shown that a well-trained reward model can substantially improve model performances at inference time via search. However, the potential of reward models during RL training time still remains largely under-explored. It is currently unclear whether these reward models can provide additional training signals to enhance the reasoning capabilities of LLMs in RL training that uses sparse success rewards, which verify the correctness of solutions. In this work, we evaluate popular reward models for RL training, including the Outcome-supervised Reward Model (ORM) and the Process-supervised Reward Model (PRM), and train a collection of LLMs for math problems using RL by combining these learned rewards with success rewards. Surprisingly, even though these learned reward models have strong inference-time performances, they may NOT help or even hurt RL training, producing worse performances than LLMs trained with the success reward only. Our analysis reveals that an LLM can receive high rewards from some of these reward models by repeating correct but unnecessary reasoning steps, leading to a severe reward hacking issue. Therefore, we introduce two novel reward refinement techniques, including Clipping and Delta. The key idea is to ensure the accumulative reward of any reasoning trajectory is upper-bounded to keep a learned reward model effective without being exploited. We evaluate our techniques with multiple reward models over a set of 1.5B and 7B LLMs on MATH and GSM8K benchmarks and demonstrate that with a carefully designed reward function, RL training without any additional supervised tuning can improve all the evaluated LLMs, including the state-of-the-art 7B LLM Qwen2.5-Math-7B-Instruct on MATH and GSM8K benchmarks.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Apr 16, 2024



Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across various a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
Towards Blockchain-Assisted Privacy-Aware Data Sharing For Edge Intelligence: A Smart Healthcare Perspective
Jun 29, 2023

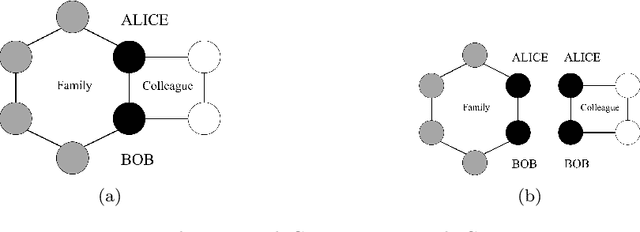
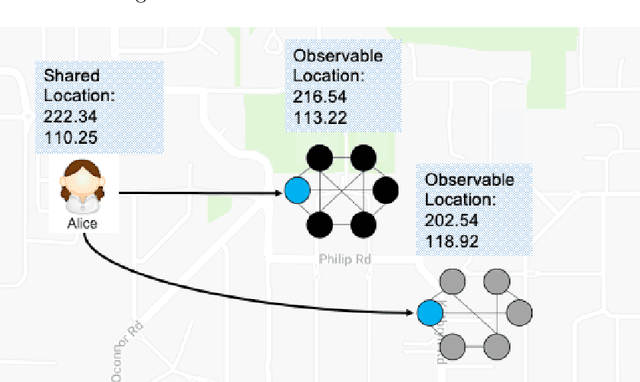
The popularization of intelligent healthcare devices and big data analytics significantly boosts the development of smart healthcare networks (SHNs). To enhance the precision of diagnosis, different participants in SHNs share health data that contains sensitive information. Therefore, the data exchange process raises privacy concerns, especially when the integration of health data from multiple sources (linkage attack) results in further leakage. Linkage attack is a type of dominant attack in the privacy domain, which can leverage various data sources for private data mining. Furthermore, adversaries launch poisoning attacks to falsify the health data, which leads to misdiagnosing or even physical damage. To protect private health data, we propose a personalized differential privacy model based on the trust levels among users. The trust is evaluated by a defined community density, while the corresponding privacy protection level is mapped to controllable randomized noise constrained by differential privacy. To avoid linkage attacks in personalized differential privacy, we designed a noise correlation decoupling mechanism using a Markov stochastic process. In addition, we build the community model on a blockchain, which can mitigate the risk of poisoning attacks during differentially private data transmission over SHNs. To testify the effectiveness and superiority of the proposed approach, we conduct extensive experiments on benchmark datasets.
What Happened 3 Seconds Ago? Inferring the Past with Thermal Imaging
Apr 26, 2023



Inferring past human motion from RGB images is challenging due to the inherent uncertainty of the prediction problem. Thermal images, on the other hand, encode traces of past human-object interactions left in the environment via thermal radiation measurement. Based on this observation, we collect the first RGB-Thermal dataset for human motion analysis, dubbed Thermal-IM. Then we develop a three-stage neural network model for accurate past human pose estimation. Comprehensive experiments show that thermal cues significantly reduce the ambiguities of this task, and the proposed model achieves remarkable performance. The dataset is available at https://github.com/ZitianTang/Thermal-IM.