 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents
Jan 30, 2026Interactive tool-using agents must solve real-world tasks via multi-turn interaction with both humans and external environments, requiring dialogue state tracking, multi-step tool execution, while following complex instructions. Post-training such agents is challenging because synthesis for high-quality multi-turn tool-use data is difficult to scale, and reinforcement learning (RL) could face noisy signals caused by user simulation, leading to degraded training efficiency. We propose a unified framework that combines a self-evolving data agent with verifier-based RL. Our system, EigenData, is a hierarchical multi-agent engine that synthesizes tool-grounded dialogues together with executable per-instance checkers, and improves generation reliability via closed-loop self-evolving process that updates prompts and workflow. Building on the synthetic data, we develop an RL recipe that first fine-tunes the user model and then applies GRPO-style training with trajectory-level group-relative advantages and dynamic filtering, yielding consistent improvements beyond SFT. Evaluated on tau^2-bench, our best model reaches 73.0% pass^1 on Airline and 98.3% pass^1 on Telecom, matching or exceeding frontier models. Overall, our results suggest a scalable pathway for bootstrapping complex tool-using behaviors without expensive human annotation.
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL
Aug 13, 2025Recent advancements in LLM-based agents have demonstrated remarkable capabilities in handling complex, knowledge-intensive tasks by integrating external tools. Among diverse choices of tools, search tools play a pivotal role in accessing vast external knowledge. However, open-source agents still fall short of achieving expert-level Search Intelligence, the ability to resolve ambiguous queries, generate precise searches, analyze results, and conduct thorough exploration. Existing approaches fall short in scalability, efficiency, and data quality. For example, small turn limits in existing online RL methods, e.g. <=10, restrict complex strategy learning. This paper introduces ASearcher, an open-source project for large-scale RL training of search agents. Our key contributions include: (1) Scalable fully asynchronous RL training that enables long-horizon search while maintaining high training efficiency. (2) A prompt-based LLM agent that autonomously synthesizes high-quality and challenging QAs, creating a large-scale QA dataset. Through RL training, our prompt-based QwQ-32B agent achieves substantial improvements, with 46.7% and 20.8% Avg@4 gains on xBench and GAIA, respectively. Notably, our agent exhibits extreme long-horizon search, with tool calls exceeding 40 turns and output tokens exceeding 150k during training time. With a simple agent design and no external LLMs, ASearcher-Web-QwQ achieves Avg@4 scores of 42.1 on xBench and 52.8 on GAIA, surpassing existing open-source 32B agents. We open-source our models, training data, and codes in https://github.com/inclusionAI/ASearcher.
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
May 30, 2025Reinforcement learning (RL) has become a trending paradigm for training large language models (LLMs), particularly for reasoning tasks. Effective RL for LLMs requires massive parallelization and poses an urgent need for efficient training systems. Most existing large-scale RL systems for LLMs are synchronous by alternating generation and training in a batch setting, where the rollouts in each training batch are generated by the same (or latest) model. This stabilizes RL training but suffers from severe system-level inefficiency. Generation must wait until the longest output in the batch is completed before model update, resulting in GPU underutilization. We present AReaL, a \emph{fully asynchronous} RL system that completely decouples generation from training. Rollout workers in AReaL continuously generate new outputs without waiting, while training workers update the model whenever a batch of data is collected. AReaL also incorporates a collection of system-level optimizations, leading to substantially higher GPU utilization. To stabilize RL training, AReaL balances the workload of rollout and training workers to control data staleness, and adopts a staleness-enhanced PPO variant to better handle outdated training samples. Extensive experiments on math and code reasoning benchmarks show that AReaL achieves \textbf{up to 2.57$\times$ training speedup} compared to the best synchronous systems with the same number of GPUs and matched or even improved final performance. The code of AReaL is available at https://github.com/inclusionAI/AReaL/.
On Designing Effective RL Reward at Training Time for LLM Reasoning
Oct 19, 2024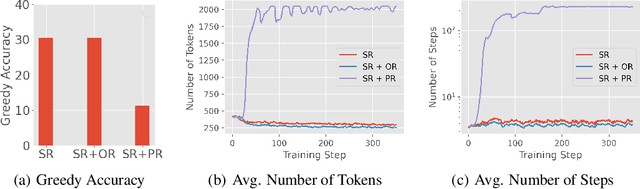
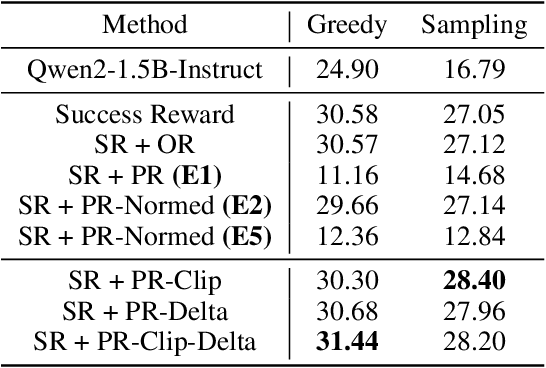

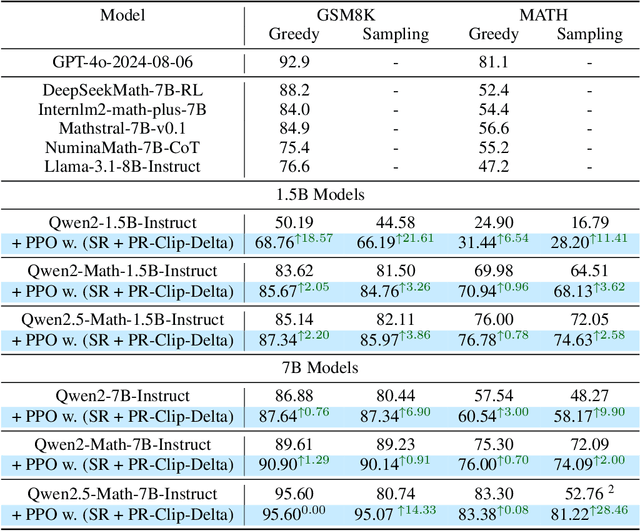
Reward models have been increasingly critical for improving the reasoning capability of LLMs. Existing research has shown that a well-trained reward model can substantially improve model performances at inference time via search. However, the potential of reward models during RL training time still remains largely under-explored. It is currently unclear whether these reward models can provide additional training signals to enhance the reasoning capabilities of LLMs in RL training that uses sparse success rewards, which verify the correctness of solutions. In this work, we evaluate popular reward models for RL training, including the Outcome-supervised Reward Model (ORM) and the Process-supervised Reward Model (PRM), and train a collection of LLMs for math problems using RL by combining these learned rewards with success rewards. Surprisingly, even though these learned reward models have strong inference-time performances, they may NOT help or even hurt RL training, producing worse performances than LLMs trained with the success reward only. Our analysis reveals that an LLM can receive high rewards from some of these reward models by repeating correct but unnecessary reasoning steps, leading to a severe reward hacking issue. Therefore, we introduce two novel reward refinement techniques, including Clipping and Delta. The key idea is to ensure the accumulative reward of any reasoning trajectory is upper-bounded to keep a learned reward model effective without being exploited. We evaluate our techniques with multiple reward models over a set of 1.5B and 7B LLMs on MATH and GSM8K benchmarks and demonstrate that with a carefully designed reward function, RL training without any additional supervised tuning can improve all the evaluated LLMs, including the state-of-the-art 7B LLM Qwen2.5-Math-7B-Instruct on MATH and GSM8K benchmarks.