 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
AREAL-DTA: Dynamic Tree Attention for Efficient Reinforcement Learning of Large Language Models
Jan 31, 2026Reinforcement learning (RL) based post-training for large language models (LLMs) is computationally expensive, as it generates many rollout sequences that could frequently share long token prefixes. Existing RL frameworks usually process these sequences independently, repeatedly recomputing identical prefixes during forward and backward passes during policy model training, leading to substantial inefficiencies in computation and memory usage. Although prefix sharing naturally induces a tree structure over rollouts, prior tree-attention-based solutions rely on fully materialized attention masks and scale poorly in RL settings. In this paper, we introduce AREAL-DTA to efficiently exploit prefix sharing in RL training. AREAL-DTA employs a depth-first-search (DFS)-based execution strategy that dynamically traverses the rollout prefix tree during both forward and backward computation, materializing only a single root-to-leaf path at a time. To further improve scalability, AREAL-DTA incorporates a load-balanced distributed batching mechanism that dynamically constructs and processes prefix trees across multiple GPUs. Across the popular RL post-training workload, AREAL-DTA achieves up to $8.31\times$ in $τ^2$-bench higher training throughput.
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL
Aug 13, 2025Recent advancements in LLM-based agents have demonstrated remarkable capabilities in handling complex, knowledge-intensive tasks by integrating external tools. Among diverse choices of tools, search tools play a pivotal role in accessing vast external knowledge. However, open-source agents still fall short of achieving expert-level Search Intelligence, the ability to resolve ambiguous queries, generate precise searches, analyze results, and conduct thorough exploration. Existing approaches fall short in scalability, efficiency, and data quality. For example, small turn limits in existing online RL methods, e.g. <=10, restrict complex strategy learning. This paper introduces ASearcher, an open-source project for large-scale RL training of search agents. Our key contributions include: (1) Scalable fully asynchronous RL training that enables long-horizon search while maintaining high training efficiency. (2) A prompt-based LLM agent that autonomously synthesizes high-quality and challenging QAs, creating a large-scale QA dataset. Through RL training, our prompt-based QwQ-32B agent achieves substantial improvements, with 46.7% and 20.8% Avg@4 gains on xBench and GAIA, respectively. Notably, our agent exhibits extreme long-horizon search, with tool calls exceeding 40 turns and output tokens exceeding 150k during training time. With a simple agent design and no external LLMs, ASearcher-Web-QwQ achieves Avg@4 scores of 42.1 on xBench and 52.8 on GAIA, surpassing existing open-source 32B agents. We open-source our models, training data, and codes in https://github.com/inclusionAI/ASearcher.
How Far Are We from Optimal Reasoning Efficiency?
Jun 08, 2025Large Reasoning Models (LRMs) demonstrate remarkable problem-solving capabilities through extended Chain-of-Thought (CoT) reasoning but often produce excessively verbose and redundant reasoning traces. This inefficiency incurs high inference costs and limits practical deployment. While existing fine-tuning methods aim to improve reasoning efficiency, assessing their efficiency gains remains challenging due to inconsistent evaluations. In this work, we introduce the reasoning efficiency frontiers, empirical upper bounds derived from fine-tuning base LRMs across diverse approaches and training configurations. Based on these frontiers, we propose the Reasoning Efficiency Gap (REG), a unified metric quantifying deviations of any fine-tuned LRMs from these frontiers. Systematic evaluation on challenging mathematical benchmarks reveals significant gaps in current methods: they either sacrifice accuracy for short length or still remain inefficient under tight token budgets. To reduce the efficiency gap, we propose REO-RL, a class of Reinforcement Learning algorithms that minimizes REG by targeting a sparse set of token budgets. Leveraging numerical integration over strategically selected budgets, REO-RL approximates the full efficiency objective with low error using a small set of token budgets. Through systematic benchmarking, we demonstrate that our efficiency metric, REG, effectively captures the accuracy-length trade-off, with low-REG methods reducing length while maintaining accuracy. Our approach, REO-RL, consistently reduces REG by >=50 across all evaluated LRMs and matching Qwen3-4B/8B efficiency frontiers under a 16K token budget with minimal accuracy loss. Ablation studies confirm the effectiveness of our exponential token budget strategy. Finally, our findings highlight that fine-tuning LRMs to perfectly align with the efficiency frontiers remains an open challenge.
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
May 30, 2025Reinforcement learning (RL) has become a trending paradigm for training large language models (LLMs), particularly for reasoning tasks. Effective RL for LLMs requires massive parallelization and poses an urgent need for efficient training systems. Most existing large-scale RL systems for LLMs are synchronous by alternating generation and training in a batch setting, where the rollouts in each training batch are generated by the same (or latest) model. This stabilizes RL training but suffers from severe system-level inefficiency. Generation must wait until the longest output in the batch is completed before model update, resulting in GPU underutilization. We present AReaL, a \emph{fully asynchronous} RL system that completely decouples generation from training. Rollout workers in AReaL continuously generate new outputs without waiting, while training workers update the model whenever a batch of data is collected. AReaL also incorporates a collection of system-level optimizations, leading to substantially higher GPU utilization. To stabilize RL training, AReaL balances the workload of rollout and training workers to control data staleness, and adopts a staleness-enhanced PPO variant to better handle outdated training samples. Extensive experiments on math and code reasoning benchmarks show that AReaL achieves \textbf{up to 2.57$\times$ training speedup} compared to the best synchronous systems with the same number of GPUs and matched or even improved final performance. The code of AReaL is available at https://github.com/inclusionAI/AReaL/.
On Designing Effective RL Reward at Training Time for LLM Reasoning
Oct 19, 2024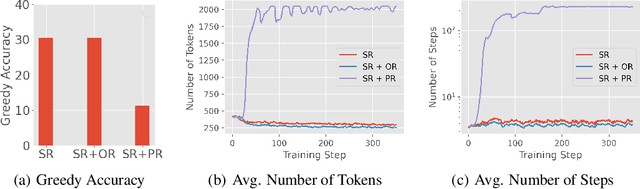
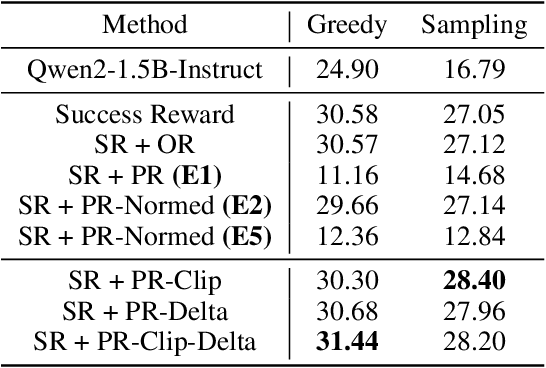

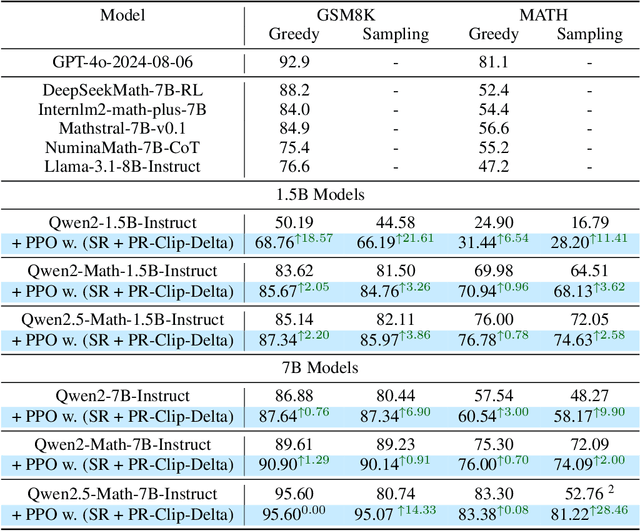
Reward models have been increasingly critical for improving the reasoning capability of LLMs. Existing research has shown that a well-trained reward model can substantially improve model performances at inference time via search. However, the potential of reward models during RL training time still remains largely under-explored. It is currently unclear whether these reward models can provide additional training signals to enhance the reasoning capabilities of LLMs in RL training that uses sparse success rewards, which verify the correctness of solutions. In this work, we evaluate popular reward models for RL training, including the Outcome-supervised Reward Model (ORM) and the Process-supervised Reward Model (PRM), and train a collection of LLMs for math problems using RL by combining these learned rewards with success rewards. Surprisingly, even though these learned reward models have strong inference-time performances, they may NOT help or even hurt RL training, producing worse performances than LLMs trained with the success reward only. Our analysis reveals that an LLM can receive high rewards from some of these reward models by repeating correct but unnecessary reasoning steps, leading to a severe reward hacking issue. Therefore, we introduce two novel reward refinement techniques, including Clipping and Delta. The key idea is to ensure the accumulative reward of any reasoning trajectory is upper-bounded to keep a learned reward model effective without being exploited. We evaluate our techniques with multiple reward models over a set of 1.5B and 7B LLMs on MATH and GSM8K benchmarks and demonstrate that with a carefully designed reward function, RL training without any additional supervised tuning can improve all the evaluated LLMs, including the state-of-the-art 7B LLM Qwen2.5-Math-7B-Instruct on MATH and GSM8K benchmarks.
ReaLHF: Optimized RLHF Training for Large Language Models through Parameter Reallocation
Jun 20, 2024



Reinforcement Learning from Human Feedback (RLHF) stands as a pivotal technique in empowering large language model (LLM) applications. Since RLHF involves diverse computational workloads and intricate dependencies among multiple LLMs, directly adopting parallelization techniques from supervised training can result in sub-optimal performance. To overcome this limitation, we propose a novel approach named parameter ReaLlocation, which dynamically redistributes LLM parameters in the cluster and adapts parallelization strategies during training. Building upon this idea, we introduce ReaLHF, a pioneering system capable of automatically discovering and running efficient execution plans for RLHF training given the desired algorithmic and hardware configurations. ReaLHF formulates the execution plan for RLHF as an augmented dataflow graph. Based on this formulation, ReaLHF employs a tailored search algorithm with a lightweight cost estimator to discover an efficient execution plan. Subsequently, the runtime engine deploys the selected plan by effectively parallelizing computations and redistributing parameters. We evaluate ReaLHF on the LLaMA-2 models with up to $4\times70$ billion parameters and 128 GPUs. The experiment results showcase ReaLHF's substantial speedups of $2.0-10.6\times$ compared to baselines. Furthermore, the execution plans generated by ReaLHF exhibit an average of $26\%$ performance improvement over heuristic approaches based on Megatron-LM. The source code of ReaLHF is publicly available at https://github.com/openpsi-project/ReaLHF .
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Apr 16, 2024



Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across various a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
Learning Agile Bipedal Motions on a Quadrupedal Robot
Nov 10, 2023
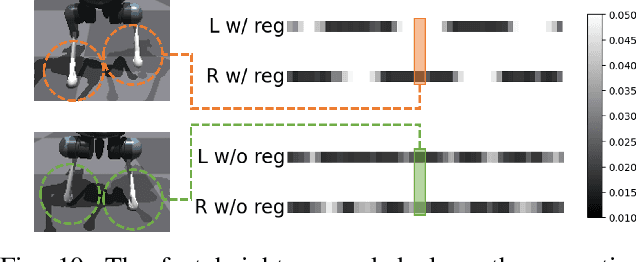
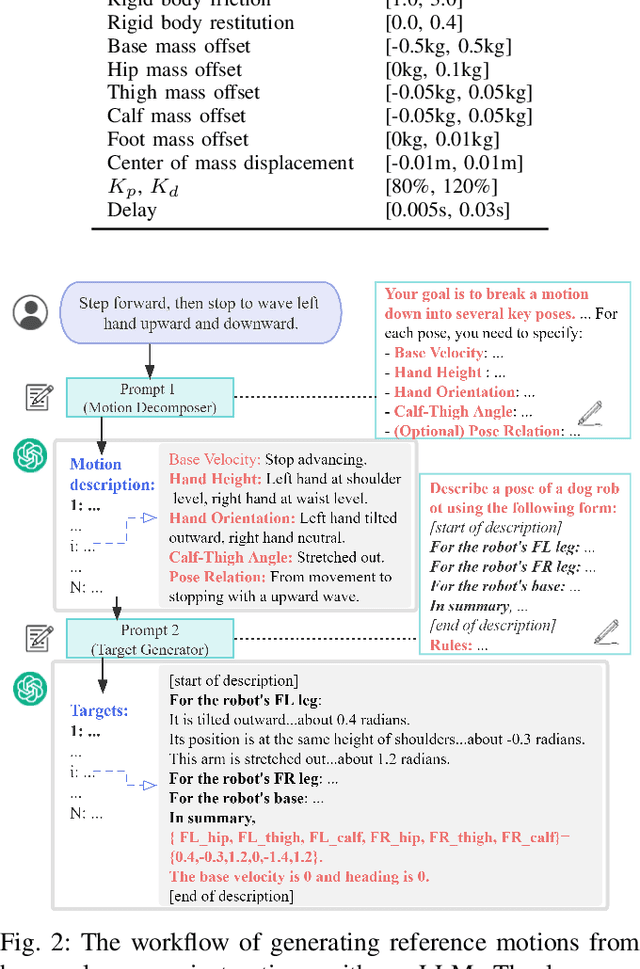

Can a quadrupedal robot perform bipedal motions like humans? Although developing human-like behaviors is more often studied on costly bipedal robot platforms, we present a solution over a lightweight quadrupedal robot that unlocks the agility of the quadruped in an upright standing pose and is capable of a variety of human-like motions. Our framework is with a bi-level structure. At the low level is a motion-conditioned control policy that allows the quadrupedal robot to track desired base and front limb movements while balancing on two hind feet. The policy is commanded by a high-level motion generator that gives trajectories of parameterized human-like motions to the robot from multiple modalities of human input. We for the first time demonstrate various bipedal motions on a quadrupedal robot, and showcase interesting human-robot interaction modes including mimicking human videos, following natural language instructions, and physical interaction.
Iteratively Learn Diverse Strategies with State Distance Information
Oct 23, 2023
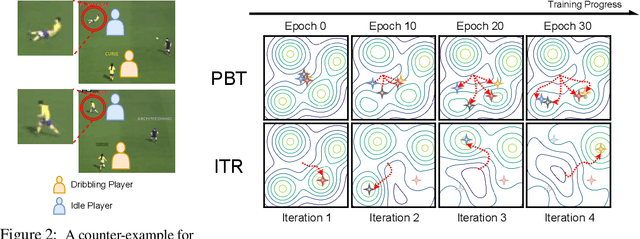
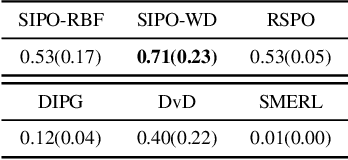
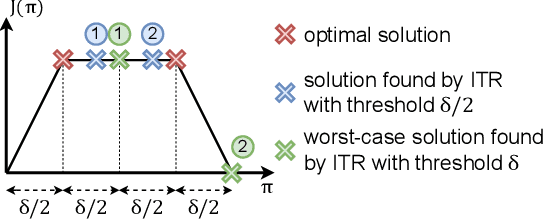
In complex reinforcement learning (RL) problems, policies with similar rewards may have substantially different behaviors. It remains a fundamental challenge to optimize rewards while also discovering as many diverse strategies as possible, which can be crucial in many practical applications. Our study examines two design choices for tackling this challenge, i.e., diversity measure and computation framework. First, we find that with existing diversity measures, visually indistinguishable policies can still yield high diversity scores. To accurately capture the behavioral difference, we propose to incorporate the state-space distance information into the diversity measure. In addition, we examine two common computation frameworks for this problem, i.e., population-based training (PBT) and iterative learning (ITR). We show that although PBT is the precise problem formulation, ITR can achieve comparable diversity scores with higher computation efficiency, leading to improved solution quality in practice. Based on our analysis, we further combine ITR with two tractable realizations of the state-distance-based diversity measures and develop a novel diversity-driven RL algorithm, State-based Intrinsic-reward Policy Optimization (SIPO), with provable convergence properties. We empirically examine SIPO across three domains from robot locomotion to multi-agent games. In all of our testing environments, SIPO consistently produces strategically diverse and human-interpretable policies that cannot be discovered by existing baselines.