 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaLHF: Optimized RLHF Training for Large Language Models through Parameter Reallocation
Jun 20, 2024



Reinforcement Learning from Human Feedback (RLHF) stands as a pivotal technique in empowering large language model (LLM) applications. Since RLHF involves diverse computational workloads and intricate dependencies among multiple LLMs, directly adopting parallelization techniques from supervised training can result in sub-optimal performance. To overcome this limitation, we propose a novel approach named parameter ReaLlocation, which dynamically redistributes LLM parameters in the cluster and adapts parallelization strategies during training. Building upon this idea, we introduce ReaLHF, a pioneering system capable of automatically discovering and running efficient execution plans for RLHF training given the desired algorithmic and hardware configurations. ReaLHF formulates the execution plan for RLHF as an augmented dataflow graph. Based on this formulation, ReaLHF employs a tailored search algorithm with a lightweight cost estimator to discover an efficient execution plan. Subsequently, the runtime engine deploys the selected plan by effectively parallelizing computations and redistributing parameters. We evaluate ReaLHF on the LLaMA-2 models with up to $4\times70$ billion parameters and 128 GPUs. The experiment results showcase ReaLHF's substantial speedups of $2.0-10.6\times$ compared to baselines. Furthermore, the execution plans generated by ReaLHF exhibit an average of $26\%$ performance improvement over heuristic approaches based on Megatron-LM. The source code of ReaLHF is publicly available at https://github.com/openpsi-project/ReaLHF .
SaberLDA: Sparsity-Aware Learning of Topic Models on GPUs
Oct 12, 2016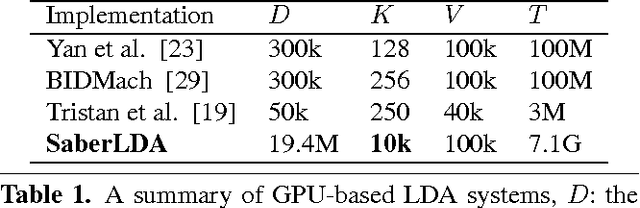
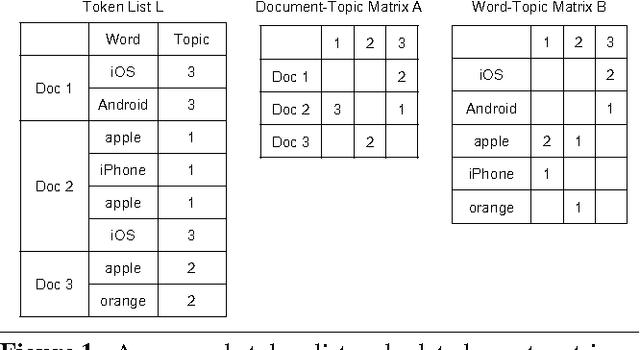

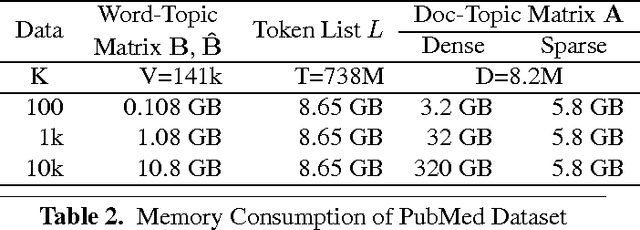
Latent Dirichlet Allocation (LDA) is a popular tool for analyzing discrete count data such as text and images. Applications require LDA to handle both large datasets and a large number of topics. Though distributed CPU systems have been used, GPU-based systems have emerged as a promising alternative because of the high computational power and memory bandwidth of GPUs. However, existing GPU-based LDA systems cannot support a large number of topics because they use algorithms on dense data structures whose time and space complexity is linear to the number of topics. In this paper, we propose SaberLDA, a GPU-based LDA system that implements a sparsity-aware algorithm to achieve sublinear time complexity and scales well to learn a large number of topics. To address the challenges introduced by sparsity, we propose a novel data layout, a new warp-based sampling kernel, and an efficient sparse count matrix updating algorithm that improves locality, makes efficient utilization of GPU warps, and reduces memory consumption. Experiments show that SaberLDA can learn from billions-token-scale data with up to 10,000 topics, which is almost two orders of magnitude larger than that of the previous GPU-based systems. With a single GPU card, SaberLDA is able to learn 10,000 topics from a dataset of billions of tokens in a few hours, which is only achievable with clusters with tens of machines before.
WarpLDA: a Cache Efficient O Algorithm for Latent Dirichlet Allocation
Mar 02, 2016
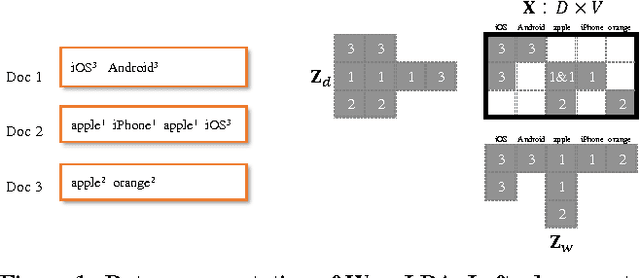


Developing efficient and scalable algorithms for Latent Dirichlet Allocation (LDA) is of wide interest for many applications. Previous work has developed an O(1) Metropolis-Hastings sampling method for each token. However, the performance is far from being optimal due to random accesses to the parameter matrices and frequent cache misses. In this paper, we first carefully analyze the memory access efficiency of existing algorithms for LDA by the scope of random access, which is the size of the memory region in which random accesses fall, within a short period of time. We then develop WarpLDA, an LDA sampler which achieves both the best O(1) time complexity per token and the best O(K) scope of random access. Our empirical results in a wide range of testing conditions demonstrate that WarpLDA is consistently 5-15x faster than the state-of-the-art Metropolis-Hastings based LightLDA, and is comparable or faster than the sparsity aware F+LDA. With WarpLDA, users can learn up to one million topics from hundreds of millions of documents in a few hours, at an unprecedentedly throughput of 11G tokens per second.